

Comparaison et analyse des GPU Nvidia H100 et A100

Dans le monde des GPU, Nvidia a toujours été un acteur majeur. Récemment, la société a fait un pas de géant avec le lancement de son nouveau GPU orienté calcul, le H100. Basé sur l'architecture Hopper, ce GPU est conçu pour des tâches de calcul intensives et offre une performance impressionnante.
| H100 | A100 | |
|---|---|---|
| Nom du périphérique rapporté | H100 PCIe | A100-SXM4-40GB |
| CPU | Intel Xeon Platinum 8480+ | AMD EPYC 7J13 |
| Horloge de boost maximale du cœur | 1755 MHz | 1410 MHz |
| Horloge de cœur au repos | 345 MHz | 210 MHz |
| Horloge de la mémoire (ne change pas sous charge) | 1593 MHz | 1215 MHz |
Une architecture impressionnante
Le H100 est le dernier membre de la gamme de GPU orientés calcul de Nvidia. Il utilise l'architecture Hopper et est construit sur une énorme puce de 814 mm2 utilisant le processus 4N de TSMC avec 80 milliards de transistors. Cette puce géante implémente 144 multiprocesseurs de streaming (SM), 60 Mo de cache L2, et 12 contrôleurs de mémoire HBM de 512 bits. La version PCIe du H100, testée sur Lambda Cloud, permet d'activer 114 de ces SM, 50 Mo de cache L2, et 10 contrôleurs de mémoire HBM2. La carte peut consommer jusqu'à 350 W.
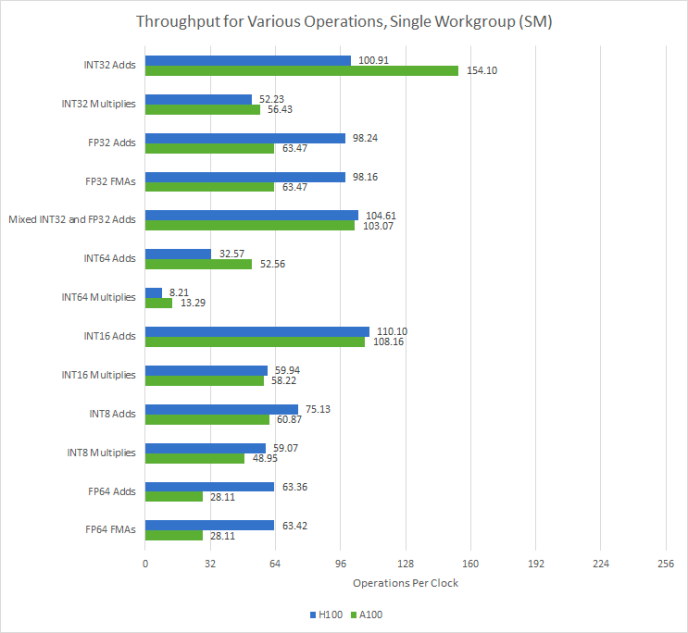
Des performances de calcul exceptionnelles
Le H100 a une capacité de calcul impressionnante. Chaque sous-partition SM (SMSP) du H100 dispose de 32 unités FP32, lui permettant d'exécuter une instruction de warp par horloge. En plus de la performance FP32, la performance FP64 double également. Chaque SMSP H100 peut exécuter une instruction de warp FP64 tous les deux cycles, comparativement à une fois tous les quatre cycles sur A100. Cela fait du H100 un bien meilleur performeur que l'A100 pour les applications scientifiques qui nécessitent une précision accrue.
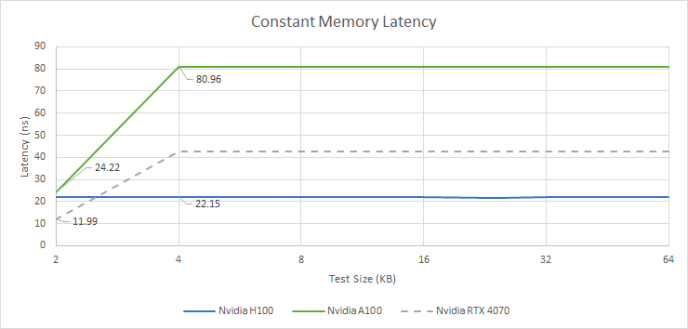
Une bande passante monstrueuse
Avec six piles de HBM2e, le H100 peut atteindre une bande passante de VRAM de près de 2 To/s. Cette bande passante monstrueuse de la VRAM sera très utile pour des ensembles de travail massifs sans motifs d'accès favorables au cache. Les GPU de consommation ont tendance à favoriser un bon cache plutôt que des configurations massives de VRAM. Les quelques GPU de consommation qui ont utilisé HBM n'ont jamais bien performé par rapport à leurs concurrents équipés de GDDR, malgré une bande passante mémoire plus importante et souvent plus de débit de calcul pour la soutenir.
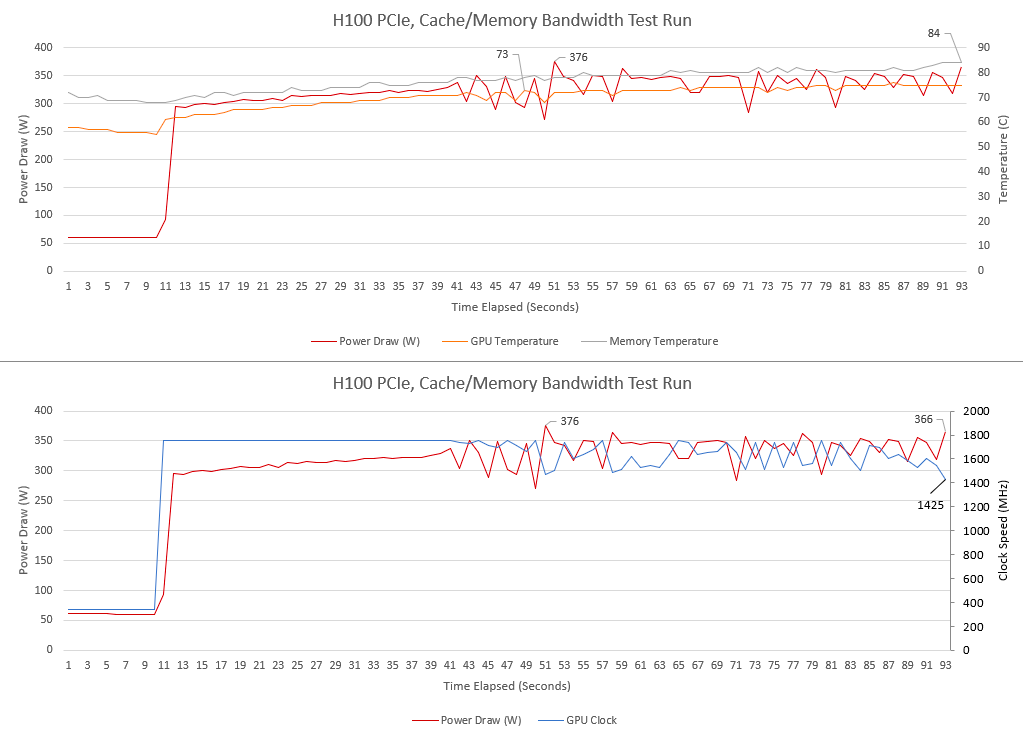
Conclusion
Le H100 de Nvidia est un GPU massivement large fonctionnant à des horloges relativement basses, ce qui met l'accent sur la performance par watt plutôt que sur la performance absolue. Il est conçu pour exécuter de grands travaux de longue durée. Basé sur l'accent mis sur la bande passante de la VRAM plutôt que sur la capacité de mise en cache, ces travaux tombent probablement dans la catégorie où si vous ne pouvez pas attraper le motif d'accès avec quelques dizaines de mégaoctets de cache, doubler la capacité de cache ne sera probablement pas d'une grande aide. Cependant, avec ses performances impressionnantes et sa bande passante énorme, le H100 est sans aucun doute un pas de géant dans le monde des GPU.



