

Chatbot Arena : Classement des modèles de langage avec le système Elo

La plateforme Chatbot Arena est une initiative qui vise à fournir un benchmarking pour les grands modèles de langage (LLM). La plateforme organise des combats anonymes et aléatoires entre modèles, en utilisant une approche crowdsourcée. Dans un article de blog récent, les créateurs de la plateforme ont partagé les résultats initiaux, ainsi qu'un classement basé sur le système de notation Elo, communément utilisé dans les jeux compétitifs tels que les échecs. La communauté est encouragée à rejoindre cet effort en proposant de nouveaux modèles, en évaluant les performances des modèles existants, en posant des questions et en votant pour les réponses préférées.
Tableau 1. Classement Elo des modèles LLM open-source populaires.
| Rang | Modèle | Classement Elo | Description |
|---|---|---|---|
| 1 | 🥇 vicuna-13b | 1169 | un assistant de chat basé sur LLaMA et affiné sur des conversations partagées par les utilisateurs par LMSYS |
| 2 | 🥈 koala-13b | 1082 | un modèle de dialogue pour la recherche académique par BAIR |
| 3 | 🥉 oasst-pythia-12b | 1065 | un Open Assistant pour tout le monde par LAION |
| 4 | alpaca-13b | 1008 | un modèle basé sur LLaMA et affiné sur des démonstrations de suivi d'instructions par Stanford |
| 5 | chatglm-6b | 985 | un modèle de dialogue bilingue open-source par l'Université Tsinghua |
| 6 | fastchat-t5-3b | 951 | un assistant de chat basé sur FLAN-T5 et affiné par LMSYS |
| 7 | dolly-v2-12b | 944 | un grand modèle de langage open-source affiné pour suivre les instructions par Databricks |
| 8 | llama-13b | 932 | des modèles de langage open-source et performants par Meta |
| 9 | stablelm-tuned-alpha-7b | 858 | des modèles de langage IA stables |

Le tableau 1 présente le classement Elo de neuf modèles populaires, basé sur les 4,7K données de vote et les calculs partagés dans ce notebook. Vous pouvez également essayer la démonstration de vote et en savoir plus sur le classement.
Introduction
Suite au grand succès de ChatGPT, de nombreux modèles de langage open-source ont été développés pour suivre les instructions. Ces modèles sont capables de fournir une assistance précieuse en réponse aux questions ou aux prompts des utilisateurs. Des exemples notables incluent Alpaca et Vicuna, basés sur LLaMA, et OpenAssistant et Dolly, basés sur Pythia.
Malgré la sortie constante de nouveaux modèles chaque semaine, la communauté rencontre des difficultés pour les évaluer efficacement. L'évaluation des assistants LLM est un véritable défi, car les problèmes peuvent être ouverts et il est très difficile de concevoir un programme pour évaluer automatiquement la qualité des réponses. Dans ce cas, nous devons généralement recourir à l'évaluation humaine basée sur la comparaison par paires.
Un bon système de benchmark basé sur la comparaison par paires devrait posséder certaines propriétés souhaitables :
- Scalabilité. Le système doit être capable de passer à un grand nombre de modèles lorsqu'il n'est pas possible de collecter suffisamment de données pour toutes les paires de modèles possibles.
- Incrémentalité. Le système doit pouvoir évaluer un nouveau modèle en utilisant un nombre relativement restreint d'essais.
- Ordre unique. Le système doit fournir un ordre unique pour tous les modèles. Étant donné deux modèles, nous devrions être en mesure de dire lequel est mieux classé ou s'ils sont à égalité.
Les créateurs de modèles de langage ont souvent du mal à trouver des systèmes de benchmarking qui répondent à toutes les propriétés souhaitées. Les cadres de benchmark couramment utilisés pour évaluer les performances des modèles de langage, tels que HELM et lm-evaluation-harness, offrent des mesures multi-métriques pour les tâches courantes dans la recherche académique. Toutefois, ces cadres ne se basent pas sur la comparaison par paires et ne sont pas adaptés pour évaluer des questions ouvertes. Bien que le projet evals d'OpenAI ait été lancé pour collecter de meilleures questions, il ne fournit pas de mécanismes de classement pour tous les modèles participants. Pour évaluer leur propre modèle Vicuna, les auteurs ont utilisé un pipeline d'évaluation basé sur GPT-4, mais celui-ci ne permet pas d'évaluer de manière scalables et incrémentales.
Dans cet article, nous présentons Chatbot Arena, une plateforme de benchmark LLM qui propose des combats anonymes et aléatoires entre modèles de manière crowdsourcée. Chatbot Arena adopte le système de notation Elo, largement utilisé dans les échecs et autres jeux compétitifs. Le système de notation Elo semble prometteur pour répondre aux propriétés souhaitées mentionnées précédemment.
Les auteurs ont lancé l'arène il y a une semaine, avec plusieurs grands modèles de langage open-source populaires, afin de collecter des données. Sur la plateforme, les utilisateurs peuvent engager une conversation avec deux modèles anonymes en même temps et voter pour celui qu'ils préfèrent. Cette méthode de collecte de données permet de représenter certains cas d'utilisation des LLM dans la pratique. Le tableau 2 présente une comparaison entre plusieurs méthodes d'évaluation.
Tableau 2 : Comparaison entre différentes méthodes d'évaluation
| HELM / lm-evaluation-harness | OpenAI/eval | Évaluation Alpaca | Évaluation Vicuna | Chatbot Arena |
|---|---|---|---|---|
| Source des questions | Jeux de données académiques | Mixte | Ensemble d'évaluation d'auto-instruction | Généré par GPT-4 |
| Évaluateur | Programme | Programme/Modèle | Humain | GPT-4 |
| Métriques | Métriques de base | Métriques de base | Taux de victoire | Taux de victoire |
Collecte de données
L'arène est hébergée sur https://arena.lmsys.org en utilisant le système de service multi-modèles FastChat. Les utilisateurs qui accèdent à l'arène peuvent discuter avec deux modèles anonymes côte à côte, comme illustré dans la figure 1. Après avoir reçu les réponses des deux modèles, les utilisateurs ont la possibilité de continuer la discussion ou de voter pour le modèle qu'ils préfèrent. Une fois que le vote est soumis, les noms des modèles sont révélés. Les utilisateurs peuvent poursuivre leur discussion ou recommencer un nouveau combat avec deux nouveaux modèles anonymes choisis aléatoirement. Toutes les interactions des utilisateurs sont enregistrées par la plateforme. Les votes sont utilisés pour l'analyse uniquement lorsque les noms des modèles sont masqués.
Depuis son lancement il y a environ une semaine, l'arène a recueilli 4,7k votes anonymes valides. Les auteurs partagent quelques analyses exploratoires dans un notebook, dont un bref résumé est présenté ici.
Résultats initiaux et classement
Les tableaux 1 et 2 montrent les notations Elo des modèles populaires basées sur les 4,7k données de vote et les calculs partagés dans le notebook. Vous pouvez également essayer la démo de vote et en savoir plus sur le classement.
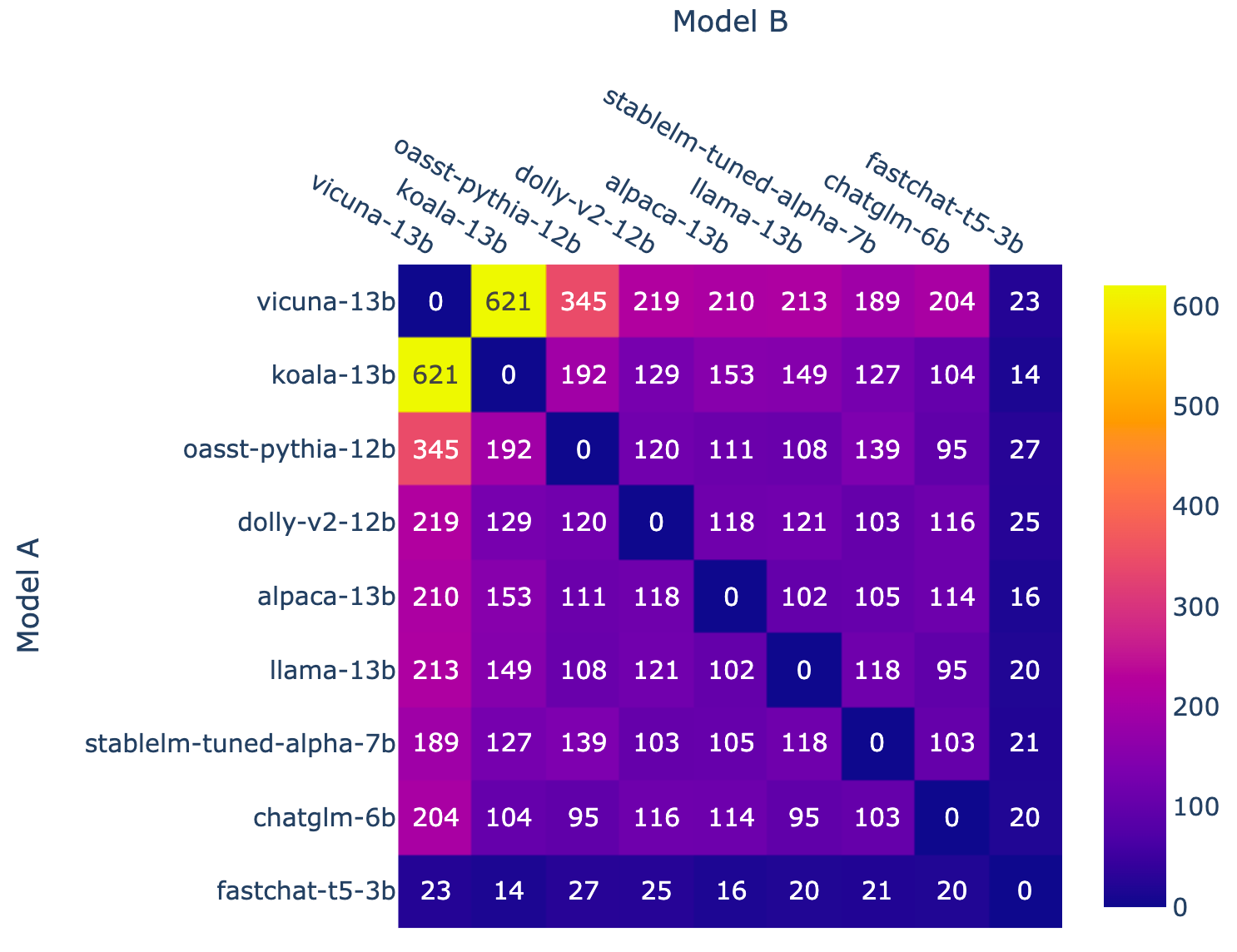
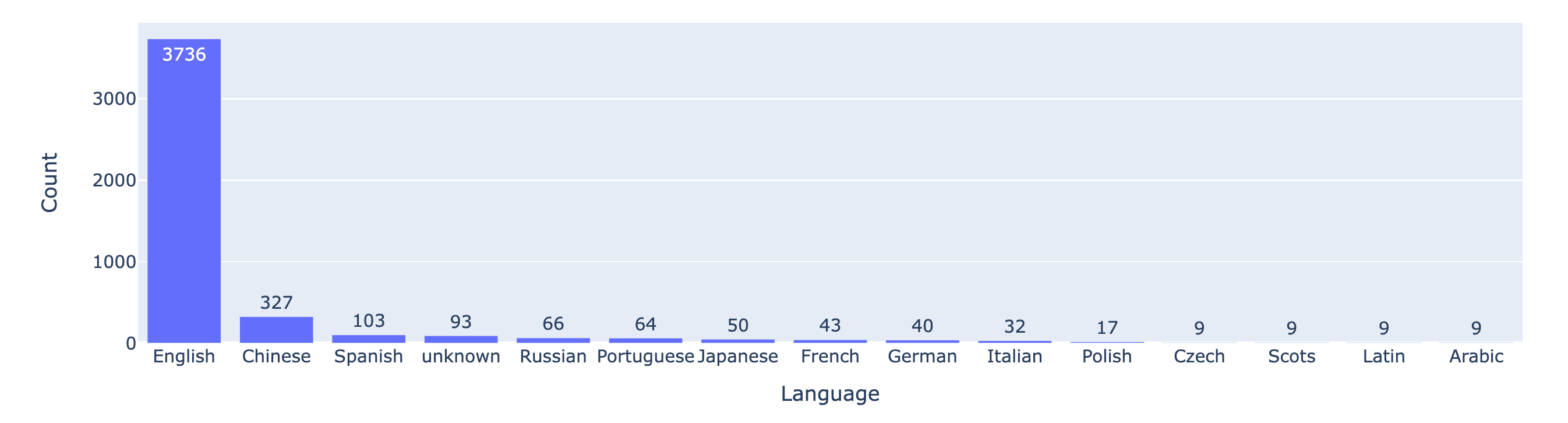
Les figures 2 et 3 montrent le nombre de combats pour chaque combinaison de modèles et la répartition des langues, respectivement. La plupart des prompts des utilisateurs sont en anglais.
Plans futurs
Ils prévoient de travailler sur les points suivants :
- Ajouter davantage de modèles fermés (ChatGPT-3.5 est maintenant disponible dans l'arène anonyme)
- Ajouter davantage de modèles open-source
- Publier des classements mis à jour périodiquement (par exemple, mensuellement)
- Mettre en œuvre de meilleurs algorithmes d'échantillonnage, des mécanismes de tournoi et des systèmes de service pour prendre en charge un plus grand nombre de modèles
- Fournir des classements plus précis pour différents types de tâches.
Liens
- Démo : https://arena.lmsys.org
- Classement : https://leaderboard.lmsys.org
- GitHub : https://github.com/lm-sys/FastChat
- Notebook Colab : https://colab.research.google.com/drive/1lAQ9cKVErXI1rEYq7hTKNaCQ5Q8TzrI5?usp=sharing



