

Comment les modèles de langage à long contexte peuvent-ils vraiment tenir leurs promesses ?

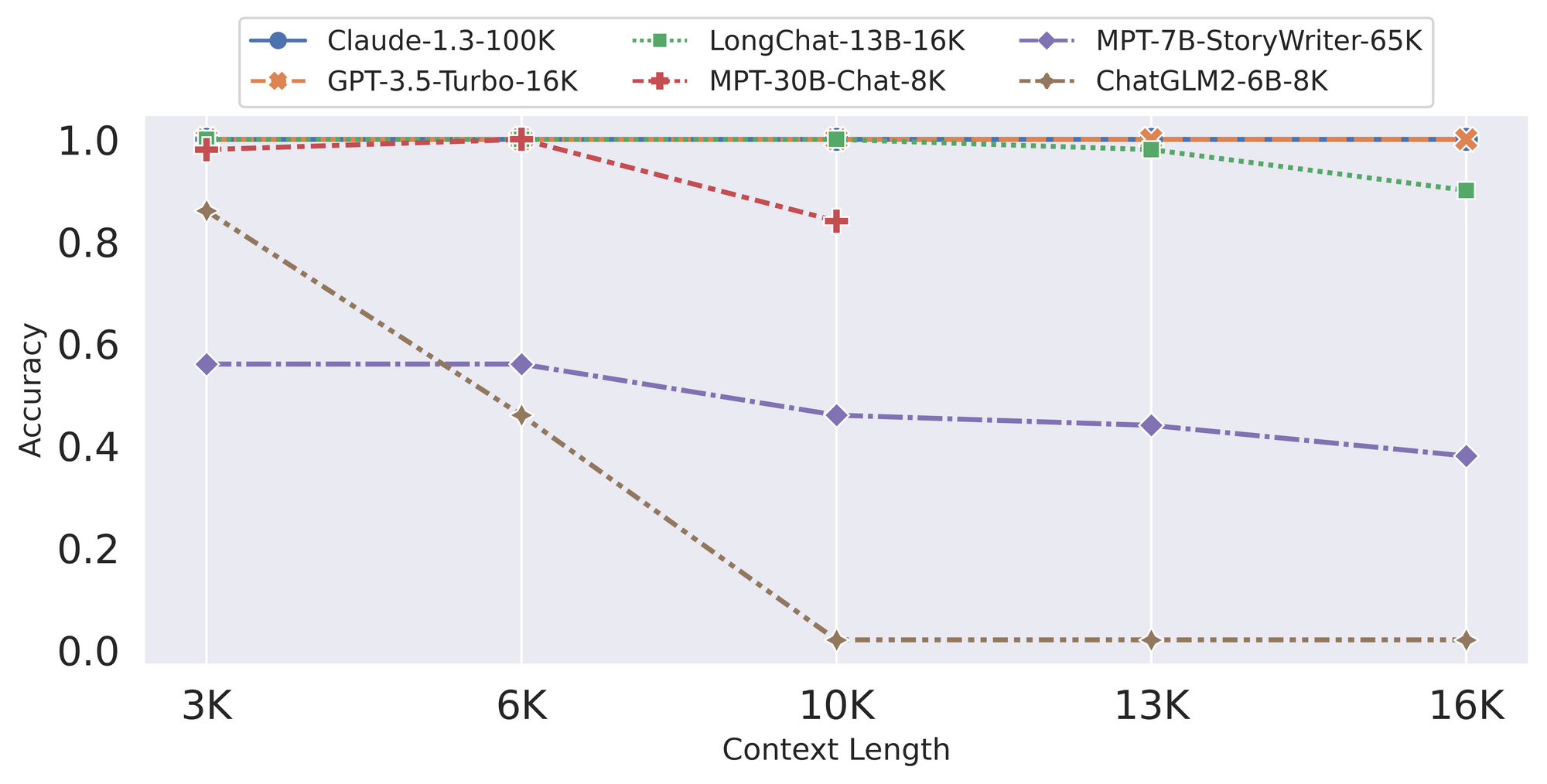
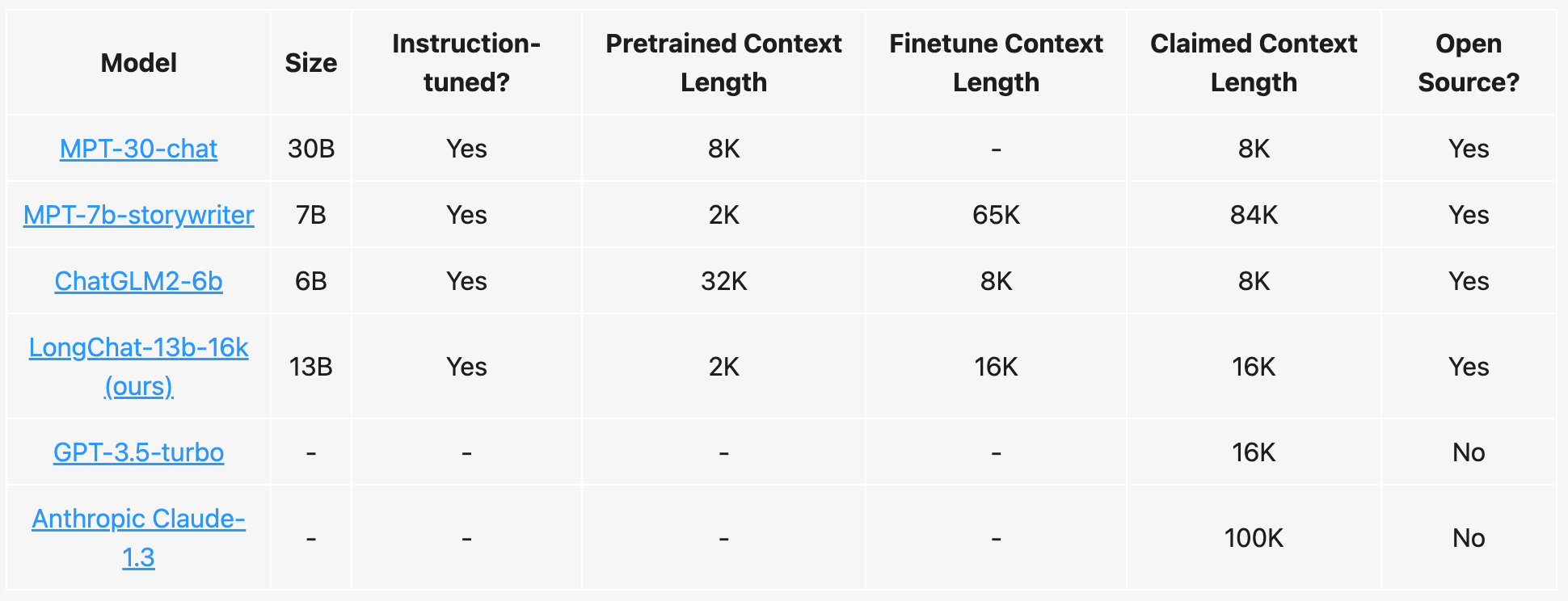
Dans le monde de l'intelligence artificielle, les modèles de chatbot sont en constante évolution. L'équipe de LongChat a récemment introduit leurs derniers modèles, LongChat-7B et LongChat-13B, qui offrent un nouveau niveau de longueur de contexte étendue jusqu'à 16K tokens. Les résultats d'évaluation montrent que la précision de récupération à longue portée de LongChat-13B est jusqu'à 2 fois supérieure à celle d'autres modèles à long contexte ouverts tels que MPT-7B-storywriter (84K), MPT-30B-chat (8K), et ChatGLM2-6B (8k). LongChat montre des résultats prometteurs pour combler l'écart entre les modèles ouverts et les modèles à long contexte propriétaires tels que Claude-100K et GPT-4-32K.
Les modèles LongChat peuvent gérer de longs contextes
Non seulement les modèles LongChat peuvent gérer une telle longueur de contexte, mais ils suivent également précisément les instructions humaines dans les dialogues et démontrent une forte performance dans le benchmark de préférence humaine MT-Bench. Leurs versions de prévisualisation sont disponibles sur HuggingFace : lmsys/longchat-13b-16k et lmsys/longchat-7b-16k. Vous pouvez les essayer immédiatement en CLI ou en interface web en utilisant FastChat.
L'intérêt pour les modèles à long contexte
Il y a eu une augmentation significative de l'intérêt au sein de la communauté open source pour le développement de modèles de langage avec un contexte plus long ou l'extension de la longueur du contexte des modèles existants comme LLaMA. Cette tendance a conduit à des observations intéressantes et à des discussions approfondies dans diverses sources, comme le blog de Kaiokendev et ce manuscrit arXiv ; entre-temps, plusieurs modèles notables ont été publiés prétendant supporter un contexte beaucoup plus long que LLaMA, notamment :
- MPT-7B-storywriter supporte une longueur de contexte de 65K et extrapole à 84K.
- MPT-30B-chat supporte une longueur de contexte de 8K.
- ChatGLM2-6B supporte un contexte de 8K.
L'exploration de techniques pour allonger le contexte
Chez LMSYS Org, ils ont simultanément exploré diverses techniques pour allonger le contexte de leurs modèles comme Vicuna. Dans ce billet de blog, en parallèle de la sortie de la série LongChat, ils partagent leurs outils d'évaluation pour vérifier la capacité à long contexte des LLM.
L'entraînement de LongChat
LongChat est affiné à partir des modèles LLaMA, qui ont été initialement pré-entraînés avec une longueur de contexte de 2048. La recette d'entraînement peut être conceptuellement décrite en deux
étapes :
Étape 1 : Condensation des embeddings rotatifs
L'embedding de position rotatif est un type d'embedding de position qui injecte l'information de position dans le Transformer. Il est mis en œuvre dans le transformer Hugging Face par :
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
Où les position_ids sont des indices tels que 1, 2, 3, ... qui dénotent la position d'un token dans la phrase. Par exemple, le token "aujourd'hui" dans la phrase "aujourd'hui est un bon jour" a position_ids 1. La fonction apply_rotary_pos_emb() applique alors une transformation basée sur les position_ids fournies.
Le modèle LLaMA est pré-entraîné avec un embedding rotatif sur une longueur de séquence de 2048, ce qui signifie qu'il n'a pas observé de scénarios où position_ids > 2048 pendant la phase de pré-entraînement. Au lieu de forcer le modèle LLaMA à s'adapter à position_ids > 2048, ils condensent position_ids > 2048 pour être dans 0 à 2048. Intuitivement, ils conjecturent que cette condensation peut réutiliser au maximum les poids du modèle appris à l'étape de pré-entraînement.
Étape 2 : Finetuning sur les données de conversation
Après avoir condensé l'embedding, ils effectuent la procédure de finetuning sur leur ensemble de données de conversation. Ils réutilisent leurs conversations partagées par les utilisateurs précédemment utilisées pour l'entraînement de Vicuna. Ils nettoient les données en utilisant la pipeline de données FastChat, et tronquent ces conversations pour qu'elles ne dépassent pas 16K. Ils affinent le modèle en utilisant la perte de prédiction du prochain token. Ils affinent les modèles 7B et 13B avec respectivement 80k et 18k conversations.
Les outils d'évaluation : LongEval
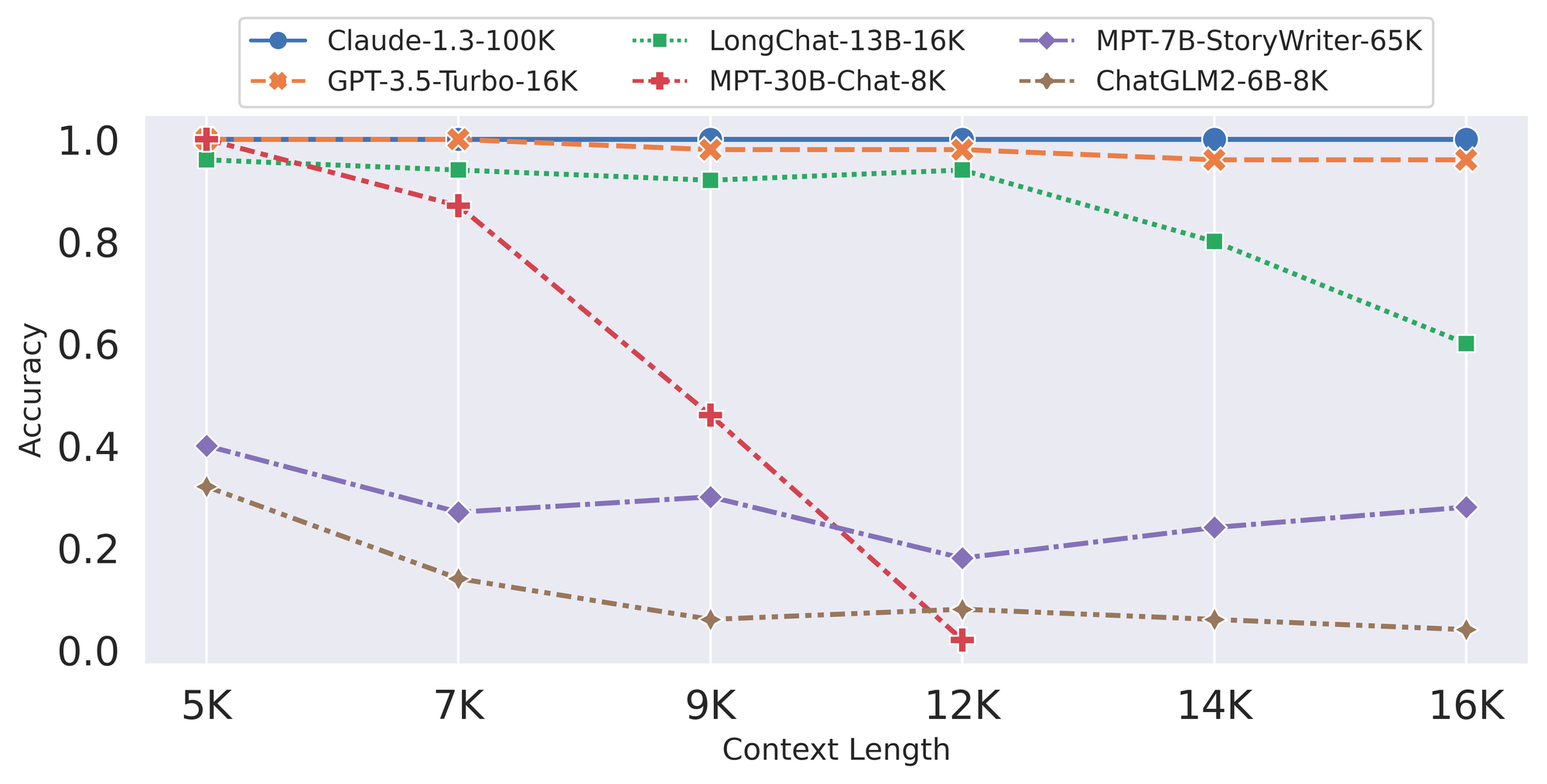
Récemment, les modèles commerciaux et open source ont continué à vanter leur capacité à supporter une longueur de contexte étendue (de 8K, 32K, 84K, à 100K) dans leurs dernières versions, mais comment pouvons-nous vérifier ces affirmations ? Pour y répondre, ils ont conçu LongEval, une suite de tests de contexte long. Cette suite incorpore deux tâches de différents degrés de difficulté, fournissant un moyen simple et rapide de mesurer et de comparer les performances de contexte long.
Résultats et découvertes
Dans leurs évaluations, les modèles commerciaux à long contexte tiennent toujours leur promesse : gpt-3.5-16k et Anthropic Claude (presque) atteignent une performance parfaite dans les deux benchmarks. Cependant, les modèles open source existants ne fonctionnent souvent pas bien à la longueur de contexte revendiquée - en fait, généralement une longueur de contexte beaucoup plus petite.
Prochaines étapes
Inspirés par les performances prometteuses et la recette d'entraînement simple de leurs modèles 16K, ils aimeraient explorer encore plus de modèles de chatbot à long contexte. Ils ont observé de nombreux problèmes d'efficacité (par exemple, la mémoire et le débit) lors de l'entraînement et de l'inférence en utilisant des chatbots avec une longueur de contexte beaucoup plus longue. Ils prévoient de développer de nouvelles technologies de système pour améliorer les performances des LLM à long contexte.
Conclusion
Il y a un écart entre la capacité d'effectuer une inférence sur de longs contextes et un bon modèle à long contexte. Par exemple, des techniques telles que Flash Attention permettent au modèle d'être servi dans une séquence beaucoup plus longue. Cependant, le fournisseur du modèle doit bien entraîner le modèle (par exemple, avec des données de séquence plus longues de haute qualité, ou effectuer une condensation comme ils l'ont exploré) pour obtenir une bonne génération de texte à long contexte, une récupération et une capacité de raisonnement. Ils appellent la communauté à contribuer à davantage de benchmarks d'évaluation des chatbots à long contexte et à comprendre/combler davantage l'écart.
Source : LMSYS



