

FreeWilly, les nouveaux modèles d'instruction avancés de Stability AI

Stability AI et son laboratoire CarperAI viennent d'annoncer le lancement de FreeWilly1 et de son successeur FreeWilly2, deux modèles linguistiques d'envergure ouverts au public. Ces deux modèles impressionnent par leur capacité de raisonnement exceptionnelle sur une variété de benchmarks. FreeWilly1 s'appuie sur le modèle initial LLaMA 65B et a été minutieusement affiné grâce à un ensemble de données synthétiquement générées, en utilisant la méthode Supervised Fine-Tune (SFT) au format Alpaca standard. FreeWilly2, quant à lui, utilise le modèle LLaMA 2 70B pour atteindre des performances comparables à celles du GPT-3.5 pour certaines tâches.
Ces deux modèles sont en réalité des expériences de recherche et ont été rendus publics dans le but de favoriser la recherche ouverte sous une licence non commerciale. Des efforts internes ont été déployés pour s'assurer que le modèle reste poli et sans danger, mais les retours et suggestions de la communauté sont les bienvenus pour d'autres tests et améliorations.
Génération et collecte des données
L'entraînement des modèles FreeWilly a été directement inspiré par la méthodologie initiée par Microsoft dans son article : "Orca: Progressive Learning from Complex Explanation Traces of GPT-4". Le processus de génération des données reste similaire, mais les sources de données diffèrent.
L'ensemble de données utilisé pour ces modèles, qui contient 600 000 points de données (soit environ 10% de la taille de l'ensemble de données utilisé dans l'article original d'Orca), a été créé en sollicitant des modèles de langage avec des instructions de haute qualité à partir des ensembles de données suivants, tous créés par Enrico Shippole:
- COT Submix Original
- NIV2 Submix Original
- FLAN 2021 Submix Original
- T0 Submix Original
Avec cette méthodologie, 500 000 exemples ont été générés avec un modèle LLM plus simple et 100 000 autres avec un modèle LLM plus sophistiqué. Ces ensembles de données ont été soigneusement filtrés pour retirer les exemples issus de benchmarks d'évaluation. Bien que l'entraînement se soit fait sur une taille d'échantillon dix fois plus petite que celle de l'article original d'Orca (ce qui réduit significativement le coût et l'empreinte carbone de l'entraînement par rapport à l'article original), les modèles FreeWilly qui en résultent démontrent une performance exceptionnelle sur différents benchmarks, ce qui valide cette approche basée sur des ensembles de données générés de manière synthétique.
Évaluation des performances
Pour évaluer ces modèles, l'outil lm-eval-harness d'EleutherAI a été utilisé, auquel a été ajouté AGIEval.
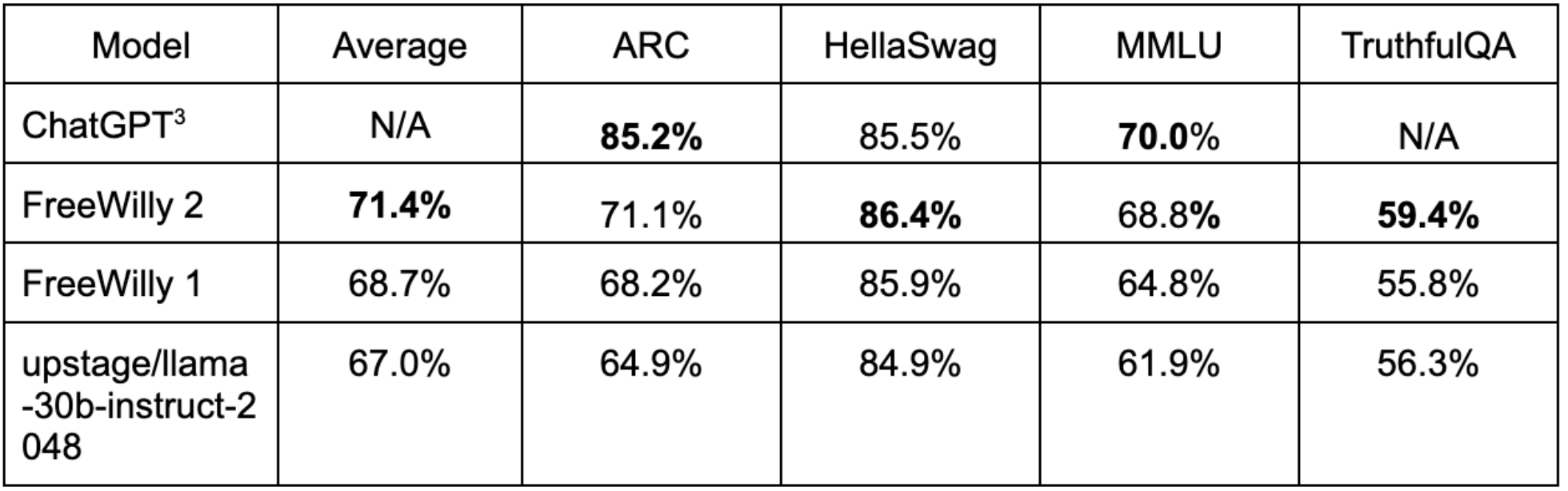
Les deux modèles FreeWilly se distinguent dans de nombreux domaines, notamment dans leur capacité à raisonner de manière complexe, comprendre les subtilités linguistiques et répondre à des questions complexes liées à des domaines spécialisés, comme le droit ou la résolution de problèmes mathématiques.
Classements des benchmarks Open LLM:
Ces résultats FreeWilly ont été évalués par des chercheurs de Stability AI et reproduits indépendamment par Hugging Face le 21 juillet 2023, puis publiés dans leur leaderboard.

Benchmarks GPT4ALL (tous en 0-shot):

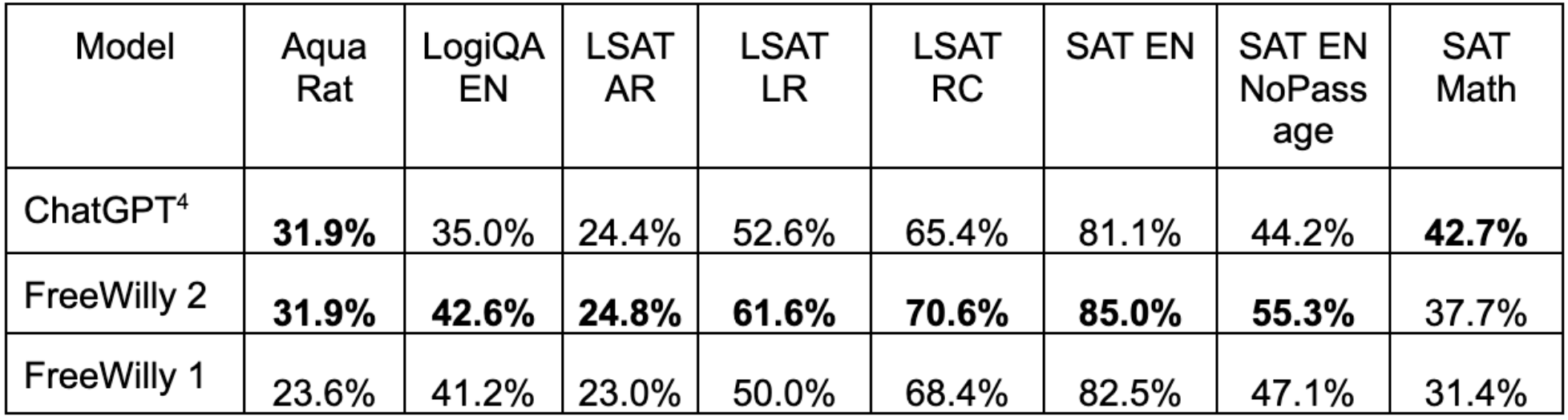
AGI Eval (tous en 0-shot):
Vers un futur ouvert
FreeWilly1 et FreeWilly2 marquent un nouveau standard dans le domaine des modèles de langage de grande taille en accès libre. Ces deux modèles font progresser la recherche, améliorent la compréhension du langage naturel et permettent de réaliser des tâches complexes. Les possibilités que ces modèles offrent à la communauté de l'IA sont infinies et ils sont susceptibles d'inspirer de nouvelles applications.
La gratitude envers l'équipe passionnée de chercheurs, d'ingénieurs et de collaborateurs dont les efforts exceptionnels et le dévouement ont permis d'atteindre cet exploit est de mise.
Gardez un œil sur les prochains développements passionnants et commencez à explorer le potentiel incroyable de FreeWilly dès aujourd'hui!
Notes:
- Les poids de FreeWilly2 sont publiés tels quels, tandis que ceux de FreeWilly1 sont publiés en deltas par rapport au modèle original. Les deux modèles sont diffusés sous licence CC-BY-NC 4.0
- Cela inclut le ARC-Challenge et d'autres sur le leaderboard Open LLM, ainsi que les benchmarks de performance de GPT4ALL
- Comme mentionné dans le "Rapport Technique GPT-4" d'OpenAI (27 mars 2023)
- Comme rapporté dans l'article "Orca: Apprentissage progressif à partir de traces d'explication complexes de GPT-4" de Microsoft Research (5 juin 2023)



