

GPT-4 : Une performance discutable sur le curriculum du MIT

Dans une analyse critique intitulée "No, GPT-4 can’t ace MIT", trois étudiants seniors du MIT en EECS (Electrical Engineering and Computer Science) ont examiné le document "Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models". Leur analyse révèle des problèmes significatifs avec les données et la méthodologie utilisées dans le document original.
Résumé de l'analyse
Un document affirmant que GPT-4 pourrait réussir le curriculum du MIT en mathématiques et en EECS a récemment fait le buzz sur Twitter. Cependant, l'analyse de ce document par les étudiants du MIT a révélé des problèmes majeurs. Malgré l'affirmation des auteurs du document original qu'ils ont manuellement vérifié la qualité du jeu de données publié, les étudiants du MIT ont trouvé des signes clairs qu'une partie importante du jeu de données d'évaluation était contaminée, permettant au modèle de tricher.
Problèmes avec les données
Les étudiants ont identifié plusieurs problèmes avec les données utilisées dans le document original. Parmi eux, environ 4% des questions du jeu de test étaient insolubles avec les informations fournies, et environ 5% des questions étaient des doublons. De plus, ils ont trouvé des fuites d'informations dans les exemples de "few-shot".
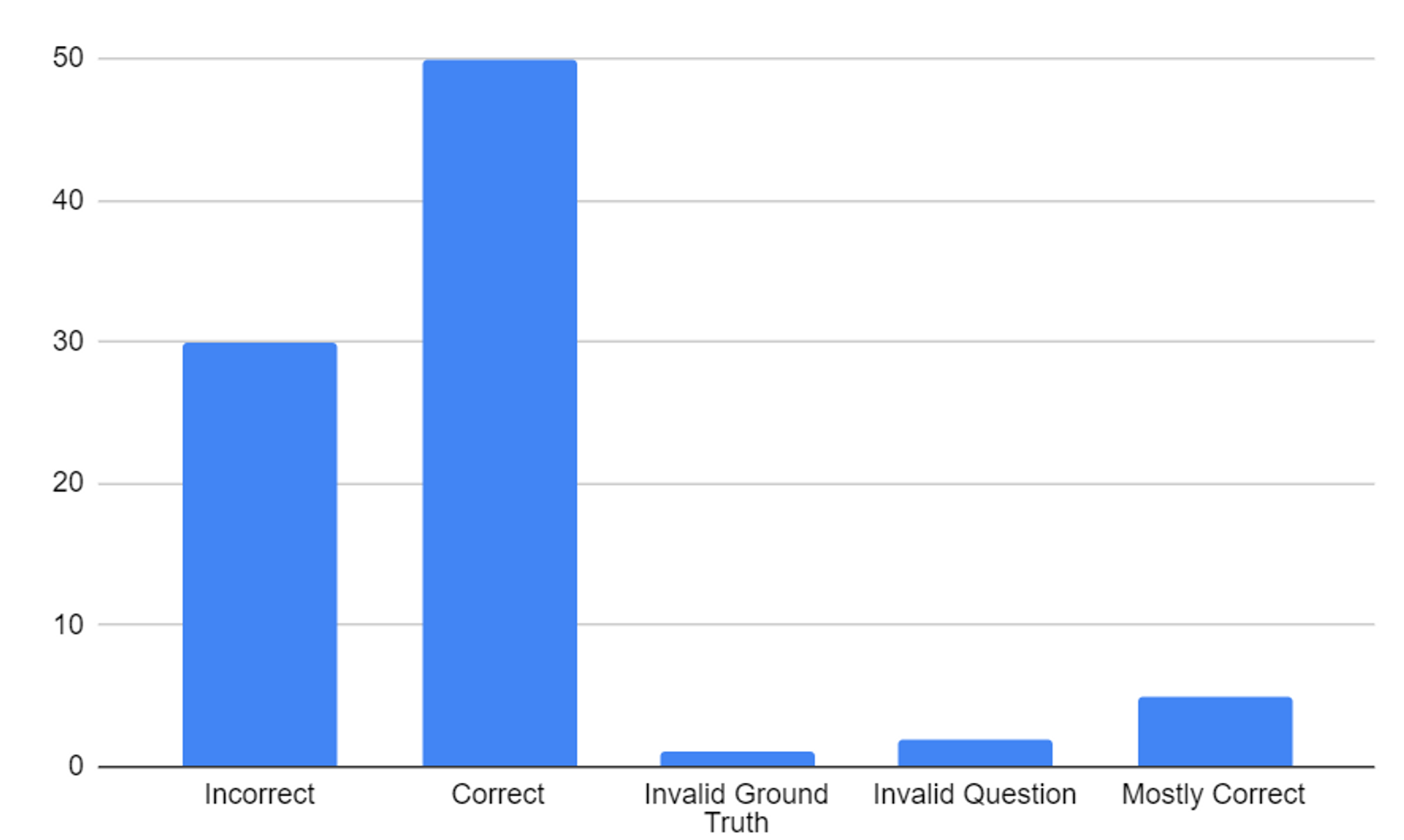
Méthodologie en question
L'analyse a également révélé des problèmes avec la méthodologie utilisée dans le document original. Par exemple, les auteurs ont utilisé une approche de "prompting" d'expert qui a conduit à des textes incohérents et n'a pas ajouté d'informations utiles. De plus, ils ont trouvé des erreurs dans le code source qui ont conduit à un "prompting" différent de celui décrit dans le document.
Conclusion
Les étudiants du MIT concluent que les problèmes qu'ils ont identifiés avec les données et la méthodologie utilisées dans le document original sont préoccupants. Ils appellent à une plus grande prudence dans l'utilisation des modèles de langage comme GPT-4 pour l'évaluation des données, soulignant que ces modèles ne peuvent pas encore être traités comme des oracles générant la vérité absolue.
Réflexions supplémentaires
Cette analyse soulève des questions importantes sur l'utilisation des modèles de langage dans la recherche en IA. Elle met en évidence les défis associés à l'évaluation de la performance de ces modèles et à la garantie de la qualité des données. Elle souligne également l'importance de la validation par les pairs et de la rigueur scientifique dans la conduite de la recherche en IA. Enfin, elle rappelle que, bien que les modèles de langage comme GPT-4 soient des outils puissants, ils ne sont pas infaillibles et doivent être utilisés avec prudence.



