

I-JEPA : Le premier modèle d'IA basé sur la vision de Yann LeCun pour une IA plus humaine

L'année dernière, Yann LeCun, le scientifique en chef de l'IA chez Meta, a proposé une nouvelle architecture visant à surmonter les principales limitations des systèmes d'IA les plus avancés d'aujourd'hui. Sa vision est de créer des machines qui peuvent apprendre des modèles internes du fonctionnement du monde, afin qu'elles puissent apprendre beaucoup plus rapidement, planifier comment accomplir des tâches complexes et s'adapter facilement à des situations inconnues.
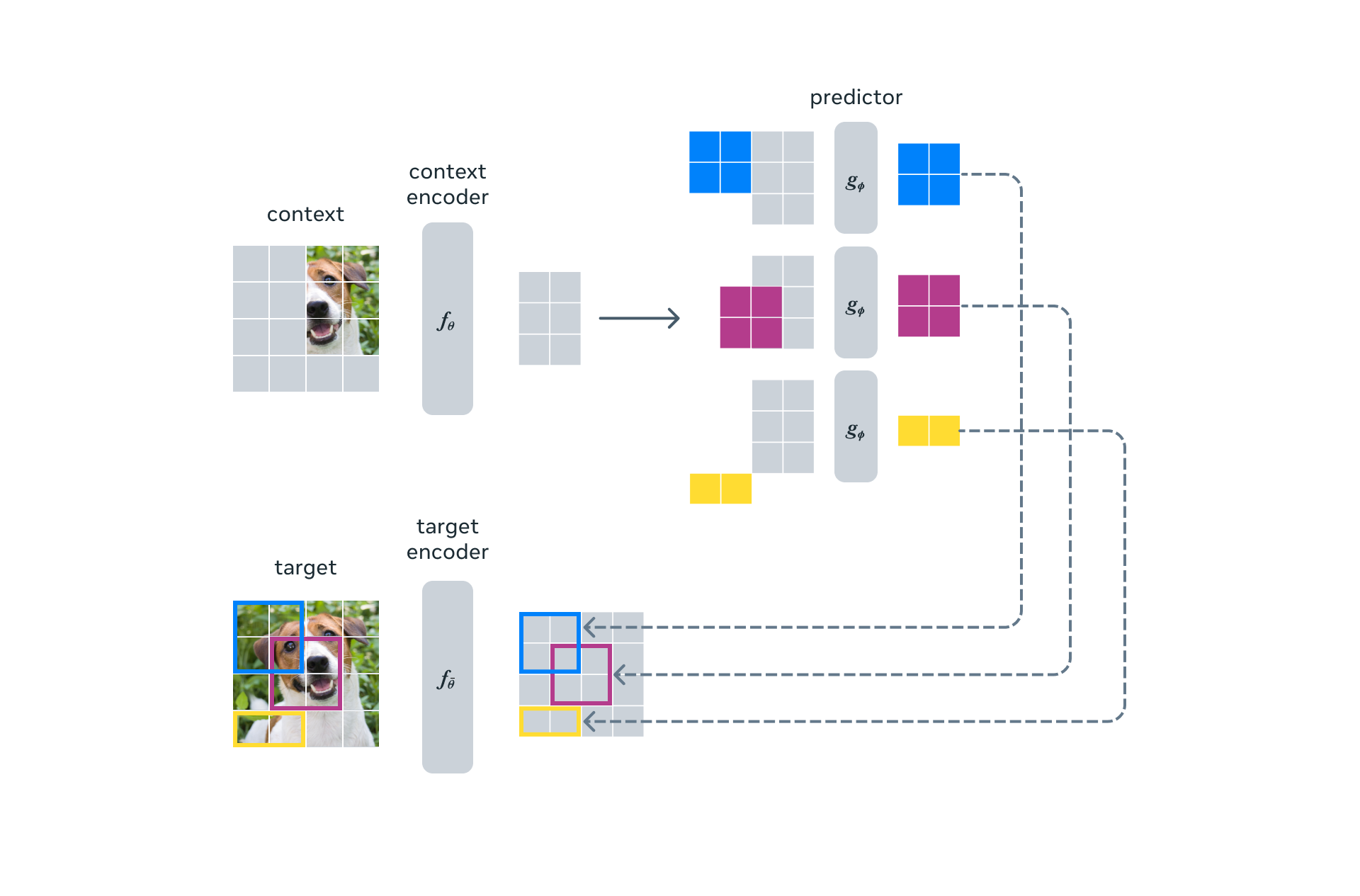
Aujourd'hui, nous sommes ravis de présenter le premier modèle d'IA basé sur un composant clé de la vision de LeCun. Ce modèle, l'Image Joint Embedding Predictive Architecture (I-JEPA), apprend en créant un modèle interne du monde extérieur, qui compare des représentations abstraites d'images (plutôt que de comparer les pixels eux-mêmes).

Une performance solide sur plusieurs tâches de vision par ordinateur
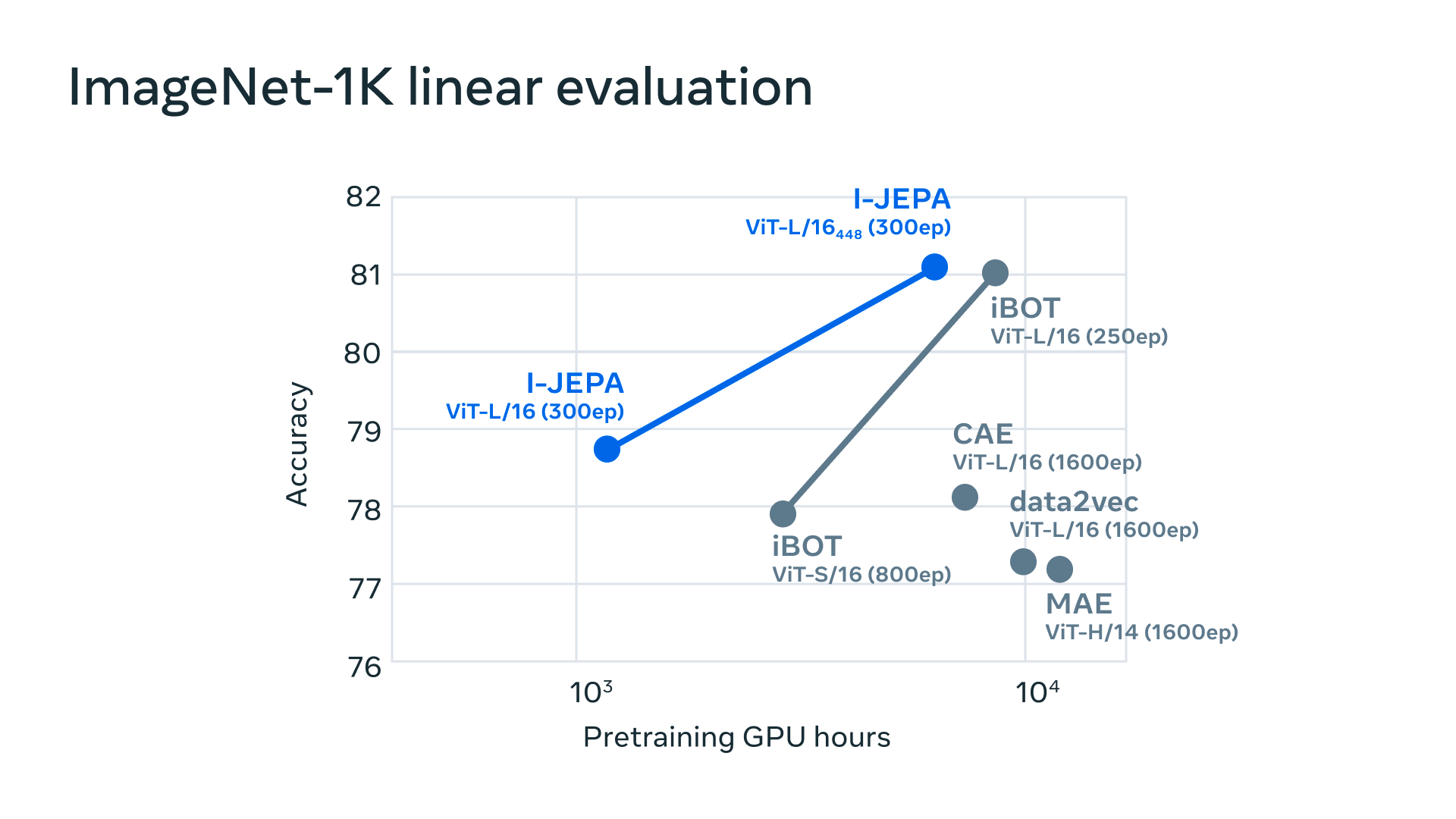
I-JEPA offre de solides performances sur plusieurs tâches de vision par ordinateur et est beaucoup plus efficace sur le plan computationnel que d'autres modèles de vision par ordinateur largement utilisés. Les représentations apprises par I-JEPA peuvent également être utilisées pour de nombreuses applications différentes sans nécessiter de réglages fins importants. Par exemple, nous entraînons un modèle de transformateur visuel de 632M de paramètres en utilisant 16 GPUs A100 en moins de 72 heures, et il atteint des performances de pointe pour la classification à faible tirage sur ImageNet, avec seulement 12 exemples étiquetés par classe. D'autres méthodes prennent généralement de deux à dix fois plus d'heures-GPU et obtiennent des taux d'erreur plus élevés lorsqu'elles sont formées avec la même quantité de données.
Un pas vers une architecture prédictive à large capacité
L'idée derrière I-JEPA est de prédire les informations manquantes dans une représentation abstraite qui est plus proche de la compréhension générale des gens. Comparé aux méthodes génératives qui prédisent dans l'espace pixel/token, I-JEPA utilise des cibles de prédiction abstraites pour lesquelles les détails inutiles au niveau des pixels sont potentiellement éliminés, amenant ainsi le modèle à apprendre des caractéristiques plus sémantiques. Une autre décision de conception essentielle pour guider I-JEPA vers la production de représentations sémantiques est la stratégie de masquage de plusieurs blocs proposée.
Efficacité accrue et forte performance
La préformation I-JEPA est également efficace sur le plan computationnel. Elle n'implique pas de frais généraux associés à l'application d'augmentations de données plus intensives sur le plan computationnel pour produire plusieurs vues. Seule une vue de l'image doit être traitée par l'encodeur cible, et seuls les blocs de contexte doivent être traités par l'encodeur de contexte.
Nous constatons empiriquement que I-JEPA apprend de solides représentations sémantiques prêtes à l'emploi sans l'utilisation de vues d'augmentation artisanales. Il surpasse également les méthodes de reconstruction de pixels et de tokens sur l'évaluation linéaire et semi-supervisée d'ImageNet-1K.
Un pas de plus vers une intelligence au niveau humain dans l'IA
I-JEPA démontre le potentiel des architectures pour apprendre des représentations d'image compétitives prêtes à l'emploi sans avoir besoin de connaissances supplémentaires codées à travers des transformations d'image artisanales. Il serait particulièrement intéressant de faire progresser les JEPAs pour apprendre des modèles du monde plus généraux à partir de modalités plus riches.
Nous avons hâte de travailler à l'extension de l'approche JEPA à d'autres domaines, comme les données appariées image-texte et les données vidéo. À l'avenir, les modèles JEPA pourraient avoir des applications passionnantes pour des tâches comme la compréhension des vidéos. C'est une étape importante vers l'application et l'échelle des méthodes d'apprentissage auto-supervisées pour apprendre un modèle général du monde.
Pour plus d'informations, consultez le document sur I-JEPA qui sera présenté à la CVPR 2023 la semaine prochaine. Le code de formation et les points de contrôle du modèle sont également disponibles en open source dès aujourd'hui.
Article basé sur le rapport officiel de Meta.





