

Wikipédia et l'Intelligence Artificielle : Une nouvelle ère pour faciliter les recherches en ligne

Il ne fait aucun doute que nous vivons une époque révolutionnaire pour l'intelligence artificielle de traitement du langage naturel. Les développeurs commencent à explorer les vastes capacités émergentes des modèles de compréhension et de génération du langage. L'un des éléments clés de cette nouvelle génération d'applications est constitué par les embedding vector qui alimentent les systèmes de recherche.
Pour aider les développeurs à démarrer rapidement avec des ensembles de données couramment utilisés, cohere a publié une archive massive de vecteurs d'embedding qui peuvent être téléchargés librement et utilisés pour alimenter vos applications.
Utilisation du modèle d'embedding multilingue Cohere pour intégrer des millions d'articles Wikipédia
En utilisant le modèle d'embedding multilingue de Cohere, ils ont intégré des millions d'articles Wikipédia dans de nombreuses langues. Les articles sont décomposés en passages, et un vecteur d'embedding est calculé pour chaque passage.
Les archives sont disponibles en téléchargement sur Hugging Face Datasets et contiennent à la fois le texte, le vecteur d'embedding et des valeurs de métadonnées supplémentaires.
Voici le schéma du dataset :
docs = load_dataset(f"Cohere/wikipedia-22-12-simple-embeddings", split="train")
Le nombre total de vecteurs/embedded passages est de 94 millions, répartis dans les langues suivantes :
- Anglais : 35 millions
- Allemand : 15 millions
- Français : 13 millions
- Espagnol : 10 millions
- Italien : 8 millions
- Japonais : 5 millions
- Arabe : 3 millions
- Chinois (simplifié) : 2 millions
- Coréen : 1 million
- Anglais simplifié : 486 mille
- Hindi : 432 mille
Vous pouvez en apprendre davantage sur la préparation et le traitement des données à travers ce lien.
Que pouvez-vous créer avec ces archives ?
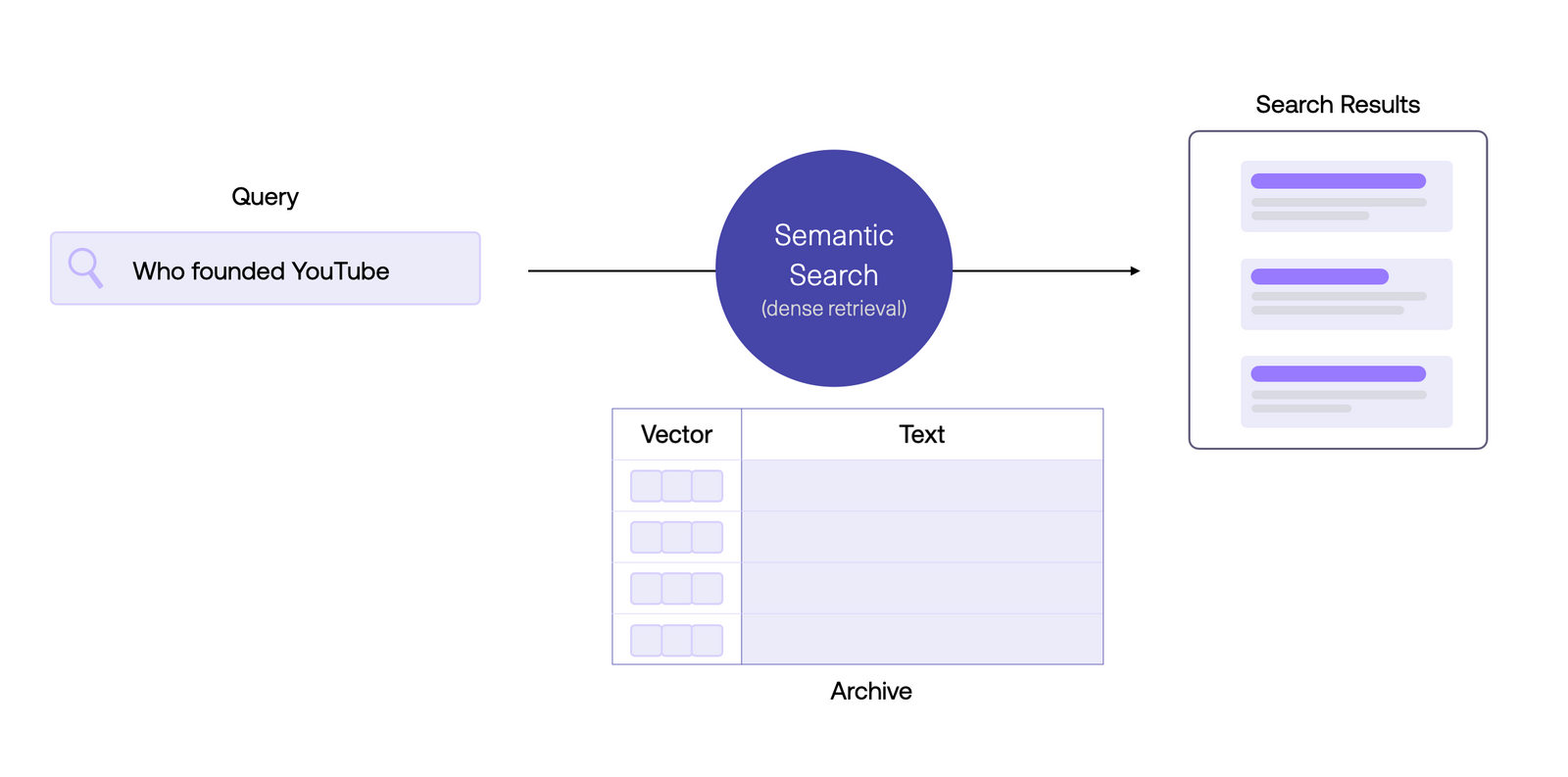
Systèmes de recherche neuronaux
Wikipédia est l'une des sources de connaissances les plus précieuses au monde. Cette archive d'embedding peut être utilisée pour construire des systèmes de recherche capables d'extraire des connaissances pertinentes basées sur une requête utilisateur.
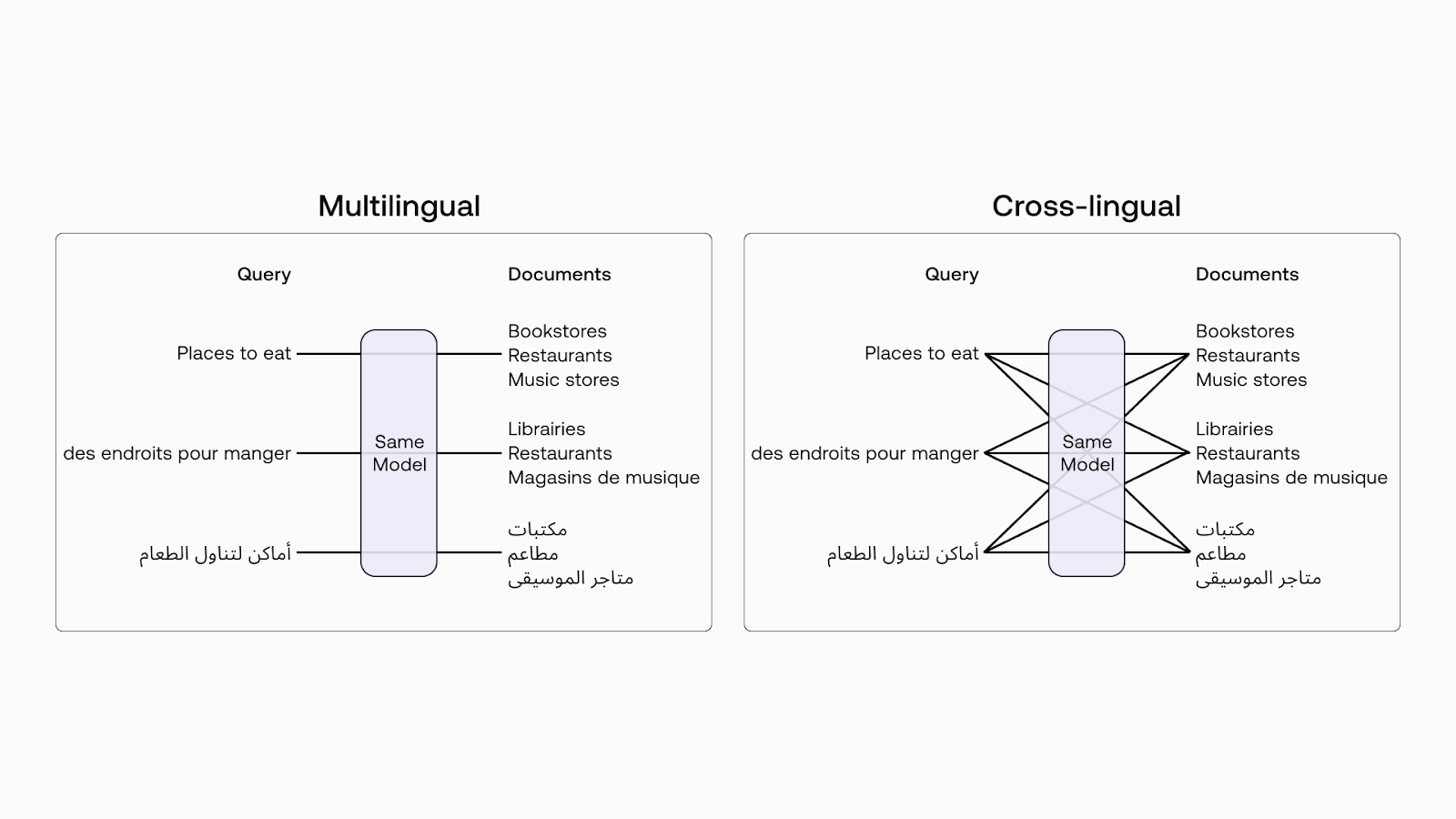
Utilisation de plusieurs langues
Puisque ces archives étaient intégrées à un modèle aux propriétés interlinguistiques, vous pouvez utiliser plusieurs langues dans votre application et vous baser sur le principe que des phrases similaires en termes de signification auront des embeddings similaires, même si elles sont dans des langues différentes.
Construisons ensemble
N'hésitez pas à passer sur le fil "Archives d'Embedding : Wikipedia" sur le Discord de Cohere en rejoignant ici si vous avez des questions, des idées ou si vous voulez partager quelque chose de cool que vous avez construit avec ces archives.
Source : Cohere



