

L'Intelligence Artificielle pour expliquer les neurones des modèles de langage

L'intelligence artificielle et les modèles de langage ont connu une croissance importante ces dernières années. Pourtant, notre compréhension de leur fonctionnement interne reste limitée. Un projet récent a utilisé GPT-4 pour générer automatiquement des explications sur le comportement des neurones dans les modèles de langage, en se basant sur GPT-2. Dans cet article, nous examinons les méthodes utilisées et les résultats obtenus.
Méthodologie
Le processus proposé pour générer des explications sur le comportement des neurones comprend trois étapes :
- Génération d'explications avec GPT-4 : Montrer des séquences de texte pertinentes et les activations à GPT-4 pour générer une explication sur le comportement d'un neurone donné de GPT-2.
- Simulation avec GPT-4 : Simuler ce qu'un neurone qui réagirait à l'explication ferait, toujours en utilisant GPT-4.
- Comparaison : Évaluer l'explication en fonction de la correspondance entre les activations simulées et les activations réelles.
Résultats
En utilisant cette méthodologie, les chercheurs ont pu mesurer l'efficacité de leurs techniques pour différentes parties du réseau et ont tenté d'améliorer la méthode pour les parties mal expliquées. Par exemple, leur technique fonctionne moins bien pour les modèles plus grands, peut-être parce que les couches supérieures sont plus difficiles à expliquer.
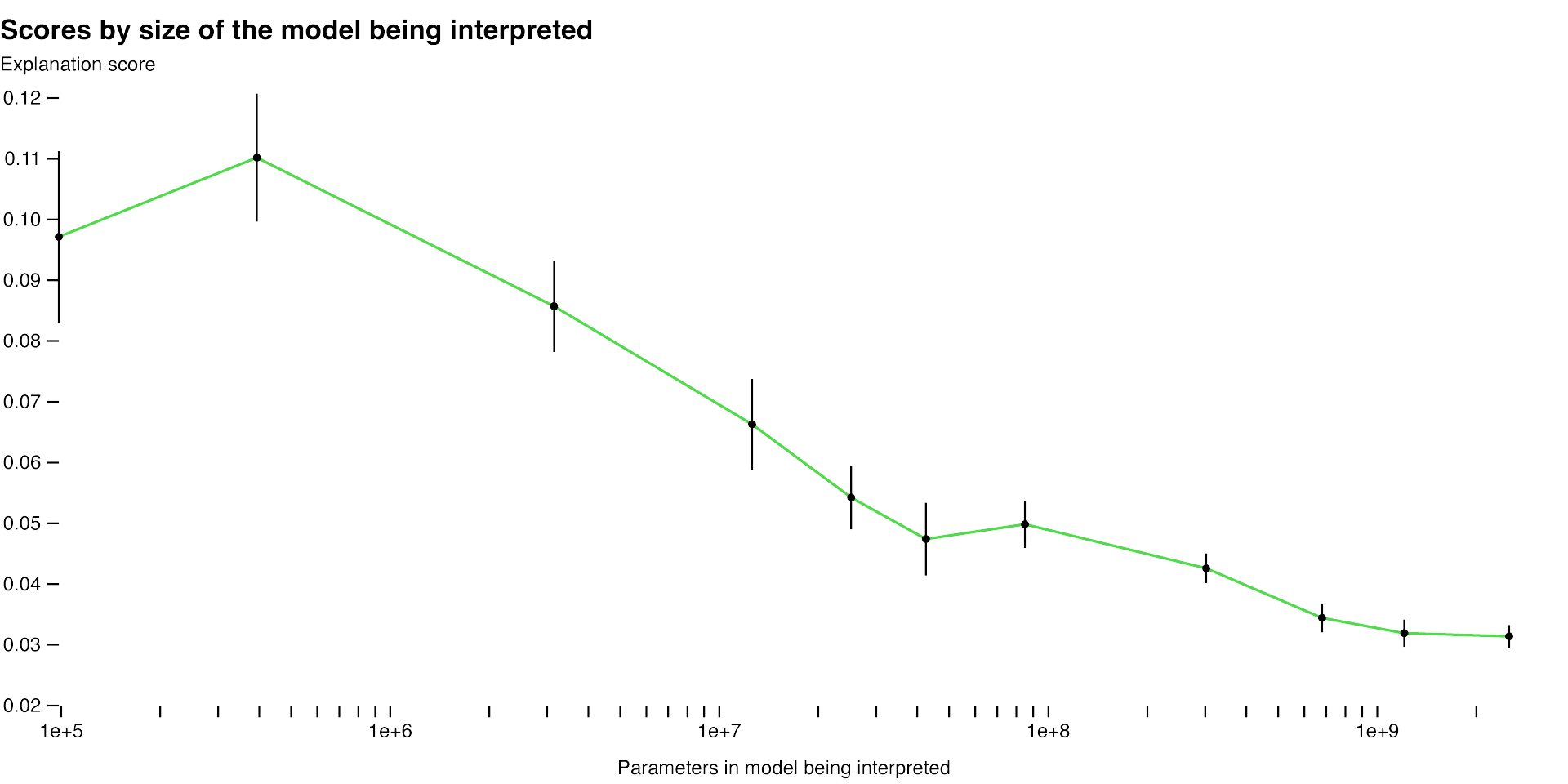
Ils ont également trouvé des moyens d'améliorer les scores d'explication :
- En itérant sur les explications, en demandant à GPT-4 de proposer des contre-exemples possibles, puis en révisant les explications à la lumière de leurs activations.
- En utilisant des modèles plus grands pour donner des explications. Le score moyen augmente à mesure que les capacités du modèle expliquant augmentent.
- En changeant l'architecture du modèle expliqué. La formation de modèles avec différentes fonctions d'activation a amélioré les scores d'explication.
Limitations et perspectives
La méthode actuelle présente plusieurs limitations, qui pourraient être abordées dans des travaux futurs :
- Se concentrer sur des explications courtes en langage naturel, alors que les neurones peuvent avoir un comportement très complexe, impossible à décrire de manière succincte.
- Trouver et expliquer automatiquement des circuits neuronaux entiers mettant en œuvre des comportements complexes, avec des neurones et des têtes d'attention travaillant ensemble.
- Expliquer le comportement des neurones sans tenter d'expliquer les mécanismes qui produisent ce comportement. Les explications à haut score pourraient donc mal se comporter sur des textes hors distribution.
- Le processus global est assez gourmand en ressources de calcul.
Les chercheurs sont enthousiastes quant aux extensions et aux généralisations de leur approche. À terme, ils aimeraient utiliser des modèles pour former, tester et itérer sur des hypothèses entièrement générales, comme le ferait un chercheur en interprétabilité.
Source : OpenAI



