

MEGABYTE : Prédiction de séquences de millions d'octets avec des Transformateurs Multidimensionnels

Une avancée majeure dans le domaine de l'intelligence artificielle a été récemment publiée dans un article intitulé "MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers". L'équipe de chercheurs, composée de Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer et Mike Lewis, a développé une nouvelle architecture de décodage appelée MEGABYTE.
Qu'est-ce que MEGABYTE ?
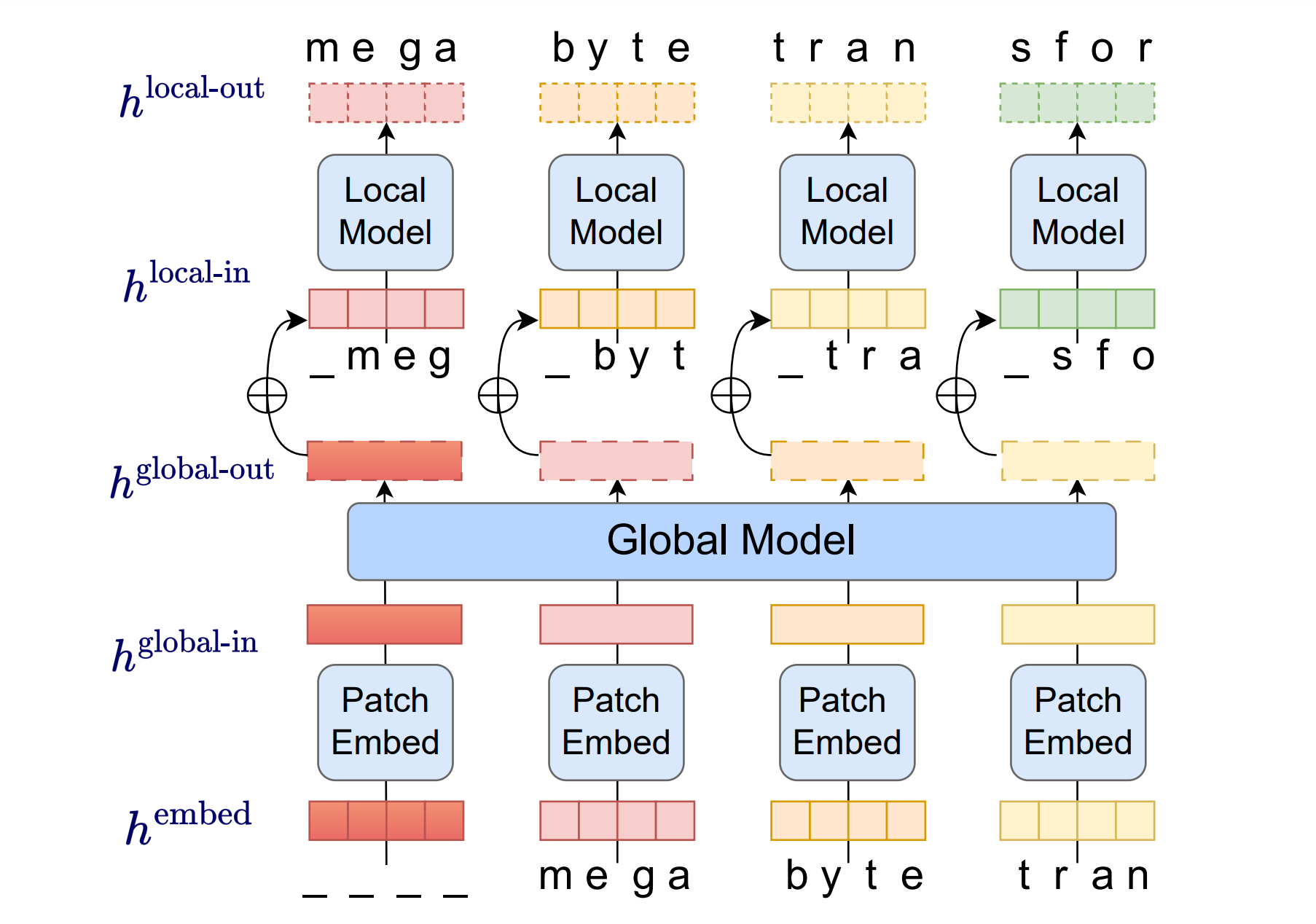
MEGABYTE est une architecture de décodage multiscale qui permet de modéliser de manière différentiable des séquences de plus d'un million d'octets. Elle segmente les séquences en patchs et utilise un sous-modèle local au sein des patchs et un modèle global entre les patchs. Cela permet une auto-attention sous-quadratique, des couches d'alimentation en avant beaucoup plus grandes, une meilleure parallélisation lors du décodage, et une meilleure performance.
Cette nouvelle architecture établit la viabilité de la modélisation de séquences autoregressives à grande échelle sans tokenisation, offrant un contraste fort avec les modèles autoregressifs existants qui utilisent généralement une forme de tokenisation.
Performances de MEGABYTE
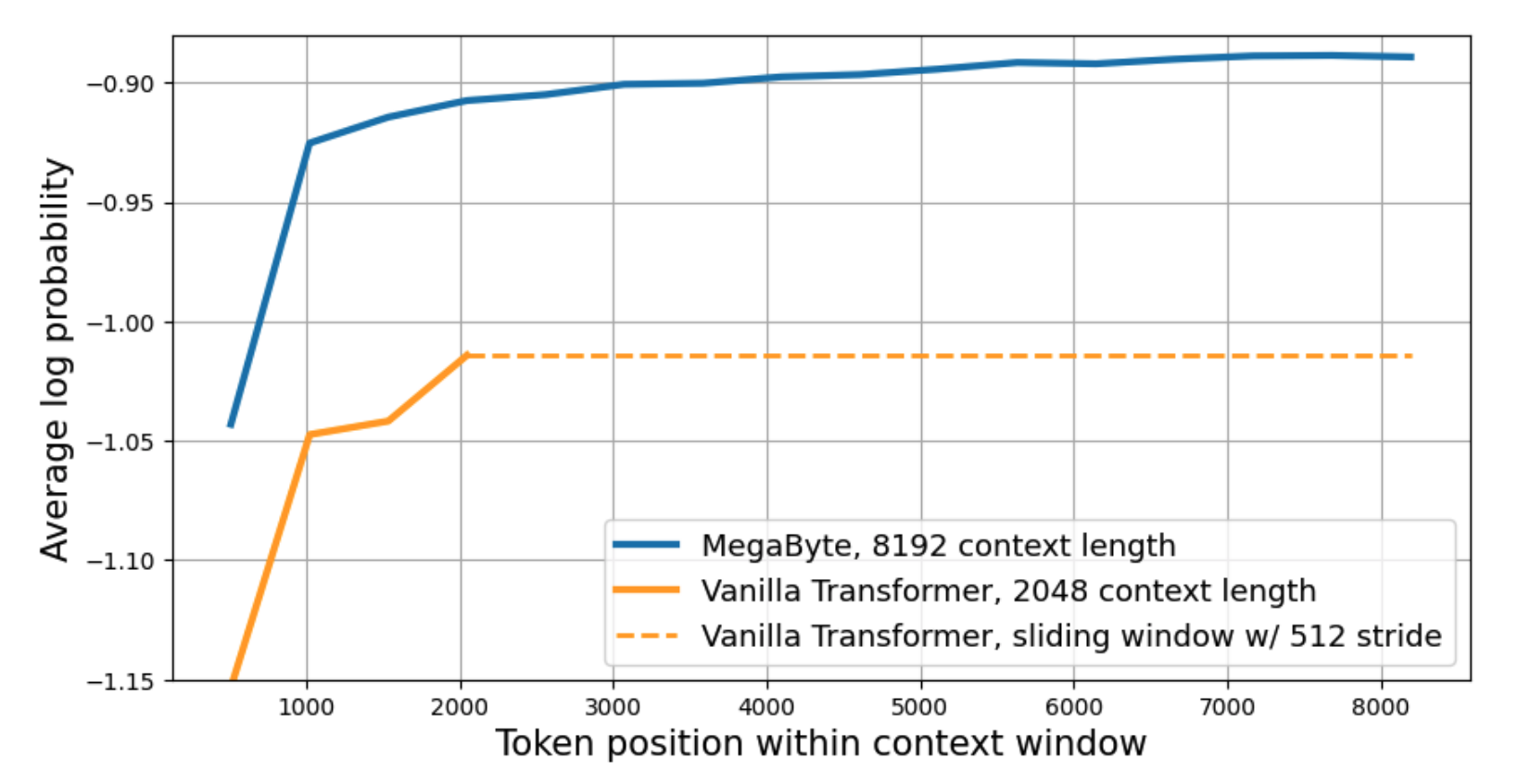
Les résultats montrent que MEGABYTE surpasse les autres systèmes à toutes les résolutions, démontrant une modélisation efficace de séquences de plus de 1M d'octets. MEGABYTE a été évalué sur un ensemble de 5 datasets divers mettant l'accent sur les dépendances à long terme : Project Gutenberg (PG-19), Books, Stories, arXiv, et Code.
MEGABYTE donne des résultats compétitifs avec les modèles de pointe formés sur des sous-mots. Ces résultats suggèrent que MEGABYTE pourrait permettre aux futurs grands modèles de langage d'être sans tokenisation.
Comparaison avec d'autres modèles
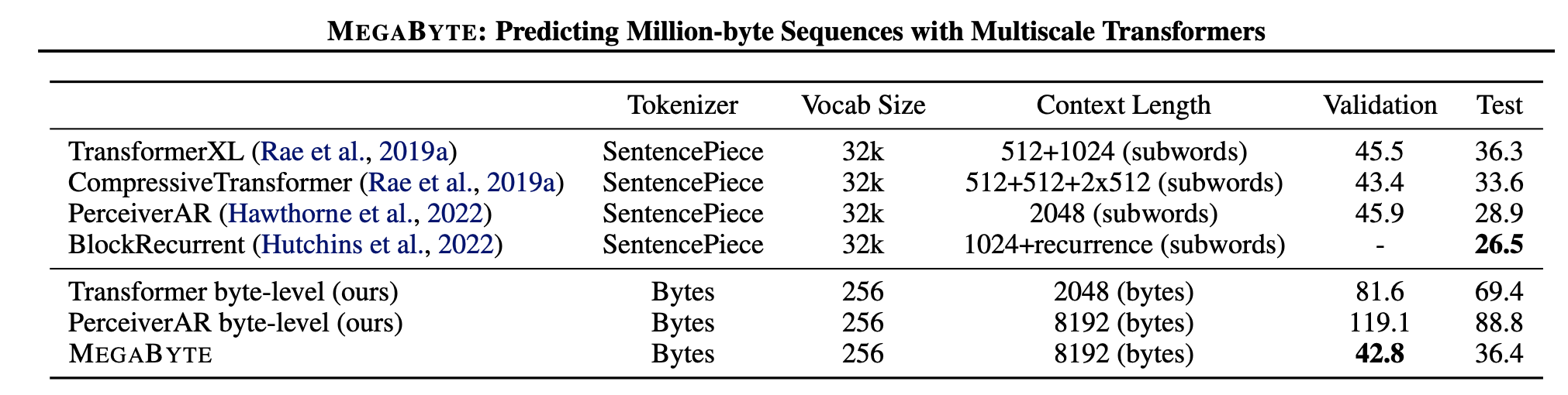
Dans des expériences à grande échelle sur PG19, MEGABYTE surpasse les autres modèles en octets par une large marge, et donne des résultats compétitifs avec les modèles de pointe formés sur des sous-mots. Par exemple, MEGABYTE a obtenu un score de 36.4 en perplexité de test, comparé à 69.4 pour le Transformer au niveau des octets et 88.8 pour le PerceiverAR au niveau des octets.
Conclusion
MEGABYTE représente une avancée significative dans le domaine de l'intelligence artificielle, en particulier dans la modélisation de séquences à grande échelle. Il offre une nouvelle approche pour la modélisation de séquences autoregressives sans tokenisation, et ses performances supérieures à celles des modèles existants suggèrent qu'il pourrait jouer un rôle important dans le développement futur des grands modèles de langage.
Pour plus d'informations, vous pouvez consulter l'article complet ici.



