

Faire tourner un LLM directement sur votre téléphone sans internet avec MLC LLM

Introduction
MLC LLM est une solution universelle qui permet de déployer n'importe quel modèle de langage sur un ensemble diversifié de plateformes matérielles et d'applications natives. Grâce à un cadre de travail productif, cette solution offre une optimisation des performances pour chaque cas d'utilisation. Tout fonctionne localement, sans serveur, et est accéléré par les GPU locaux sur votre téléphone et votre ordinateur portable. Pour en savoir plus, consultez leur dépôt GitHub.
Essayer MLC LLM
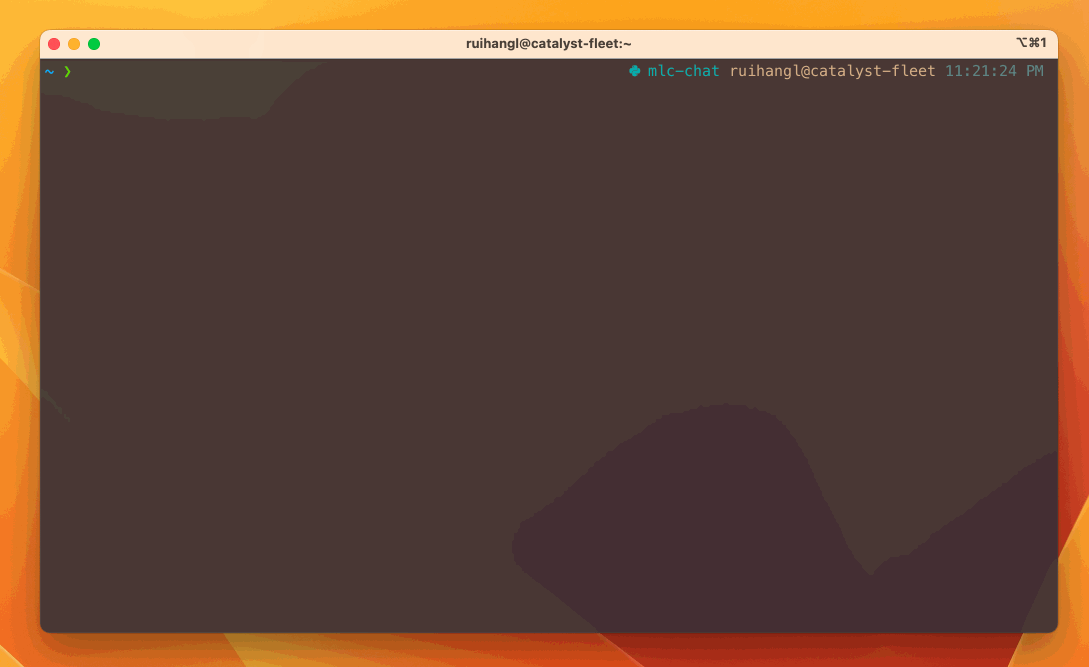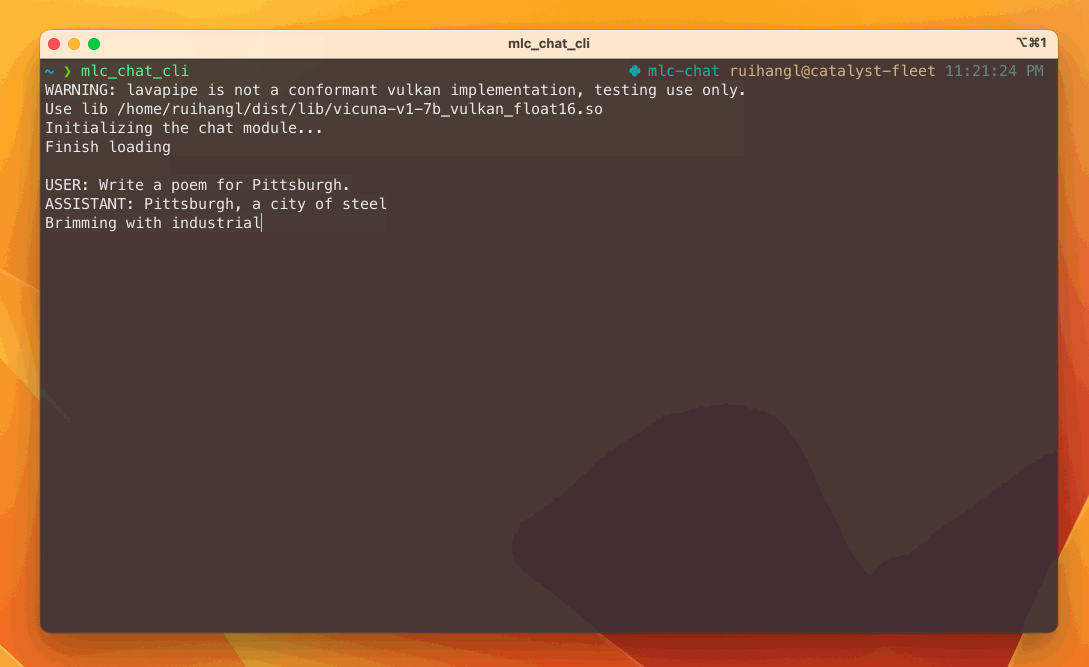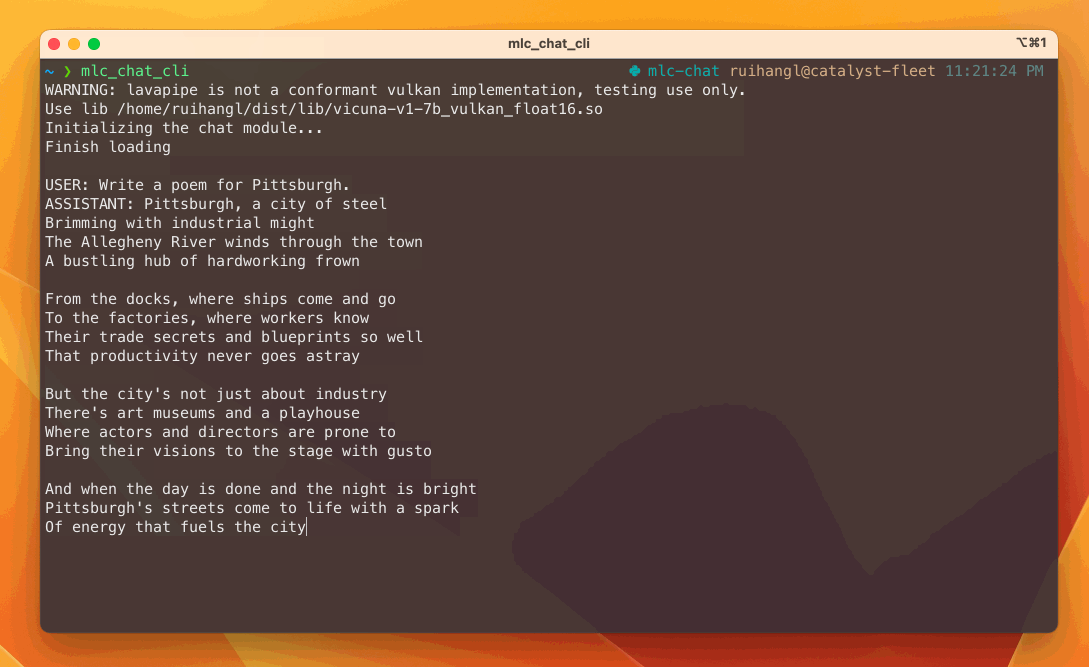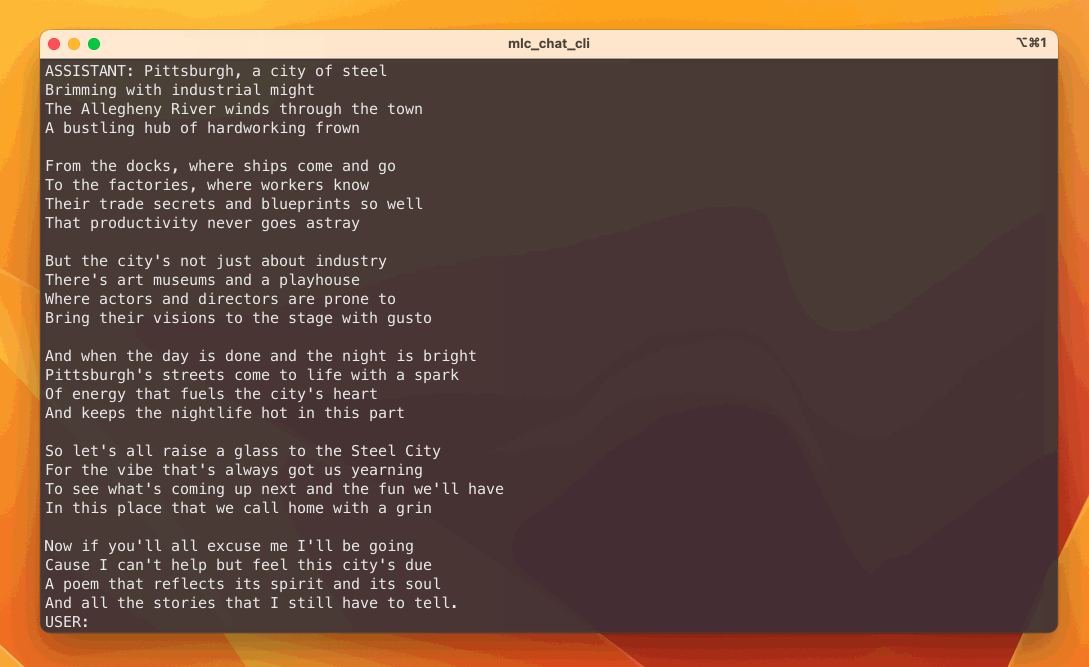
Pour tester les modèles de langage et le chatbot en local, suivez les instructions correspondant à votre plateforme :
- iPhone : Consultez la page TestFlight (limitée aux 9000 premiers utilisateurs) pour installer et utiliser l'application de chat iOS. L'application nécessite environ 4 Go de mémoire pour fonctionner.
- Windows, Linux, Mac : Installez l'interface en ligne de commande (CLI) pour discuter avec le bot dans votre terminal. Suivez les instructions fournies sur leur site.
- Navigateur Web : Consultez le projet WebLLM pour déployer des modèles directement dans votre navigateur, sans serveur et accéléré par WebGPU.
Qu'est-ce que MLC LLM ?
Les progrès récents en intelligence artificielle générative (IA) et les modèles de langage de grande taille (LLM) sont de plus en plus présents. Cependant, les LLM sont gourmands en ressources et exigent des calculs intensifs. Les développeurs doivent souvent compter sur de puissants clusters et du matériel coûteux pour exécuter l'inférence des modèles. De plus, le déploiement des LLM présente plusieurs défis, tels que l'évolution constante des modèles, les contraintes de mémoire et la nécessité d'optimisation.
L'objectif de ce projet est de permettre le développement, l'optimisation et le déploiement de modèles d'IA pour l'inférence sur un éventail d'appareils, y compris les navigateurs, ordinateurs portables et applications mobiles des utilisateurs. Pour ce faire, il faut tenir compte de la diversité des dispositifs de calcul et des environnements de déploiement.
MLC LLM propose un flux de travail reproductible, systématique et personnalisable qui permet aux développeurs et chercheurs en systèmes d'IA de mettre en œuvre des modèles et des optimisations dans une approche axée sur la productivité et Python. Cette méthodologie permet d'expérimenter rapidement de nouveaux modèles et idées, puis de les déployer nativement sur les cibles souhaitées. De plus, le projet élargit continuellement l'accélération des LLM en élargissant les backends de TVM pour rendre la compilation des modèles plus transparente et efficace.
Comment MLC permet-il un déploiement natif universel ?
La pierre angulaire de la solution en question repose sur la compilation de l'apprentissage automatique (MLC), utilisée pour déployer efficacement les modèles d'IA. L'entreprise mise sur les écosystèmes open-source, incluant les tokenizers de HuggingFace et Google, ainsi que les LLM open-source tels que Llama, Vicuna, Dolly et d'autres. Le flux de travail principal est basé sur Apache TVM Unity, un développement prometteur au sein de la communauté Apache TVM.
Voici quelques-unes des principales caractéristiques de MLC LLM :
- Forme dynamique : L'intégration d'un modèle de langage en tant que TVM IRModule avec un support natif de forme dynamique est réalisée, permettant d'éviter l'ajout de padding supplémentaire à la longueur maximale et de réduire la quantité de calcul et l'utilisation de la mémoire.
- Optimisations de compilation ML composable : De nombreuses optimisations de déploiement de modèles sont effectuées, telles que la transformation de code de compilation améliorée, la fusion, la planification de la mémoire, l'offloading de bibliothèque et l'optimisation manuelle du code, qui peuvent être facilement intégrées sous forme de transformations IRModule de TVM exposées en tant qu'API Python.
- Quantification : Des quantifications à faible nombre de bits sont utilisées pour compresser les poids du modèle et tirer parti de TensorIR au niveau des boucles de TVM pour personnaliser rapidement les générations de code pour différents schémas d'encodage de compression.
- Runtime : Les bibliothèques générées finales fonctionnent dans l'environnement natif, avec un runtime TVM comportant des dépendances minimales et prenant en charge diverses API de pilotes GPU et liaisons de langage natif (C, JavaScript, etc).
Architecture et compatibilité
En tant que point de départ, MLC génère des shaders GPU pour CUDA, Vulkan et Metal. Il est possible d'ajouter d'autres supports, tels qu'OpenCL, SYCL, WebGPU-native, grâce à des améliorations du compilateur et du runtime TVM. MLC prend également en charge diverses cibles CPU, notamment ARM et x86 via LLVM.
Nous nous appuyons fortement sur l'écosystème open-source, plus précisément sur TVM Unity, un développement récent passionnant du projet TVM qui permet des expériences de développement interactives MLC axées sur Python. Nous avons également tiré parti d'optimisations telles que les noyaux de quantification fusionnés, le support natif de la forme dynamique et les backends GPU diversifiés.
Source : https://mlc.ai/mlc-llm/



