

AudioCraft : une IA générative pour l'audio, désormais accessible à tous

Une nouvelle étape a été franchie dans le domaine de l'intelligence artificielle générative avec l'ouverture du code source d'AudioCraft. Ce cadre simplifié permet de générer des audios et musiques de haute qualité à partir d'entrées utilisateur en texte, après un apprentissage sur des signaux audio bruts.
Présentation d'AudioCraft
AudioCraft se compose de trois modèles : MusicGen, AudioGen et EnCodec. MusicGen, formé avec de la musique détenue par Meta et spécifiquement sous licence, génère de la musique à partir d'entrées utilisateur en texte. De son côté, AudioGen, qui a été formé sur des effets sonores publics, génère de l'audio à partir d'entrées utilisateur en texte.
Une version améliorée du décodeur EnCodec a récemment été publiée. Elle permet une génération de musique de meilleure qualité avec moins d'artefacts. Le modèle AudioGen préformé permet de générer des sons environnementaux et des effets sonores comme un chien qui aboie, des klaxons de voitures ou des pas sur un plancher de bois. Tous les poids et le code du modèle AudioCraft sont maintenant accessibles. Ils sont disponibles à des fins de recherche et pour améliorer la compréhension de la technologie par le public.
Du texte à l'audio en toute simplicité
Alors que les modèles d'IA générative, y compris les modèles de langage, ont fait d'énormes progrès ces dernières années, l'audio a toujours semblé un peu à la traîne. Générer un audio de haute fidélité de n'importe quel type nécessite de modéliser des signaux et des motifs complexes à différentes échelles. La musique est probablement le type d'audio le plus difficile à générer car elle est composée de motifs locaux et à long terme.
Pour relever ce défi, des approches ont été développées pour apprendre des tokens audio discrets à partir du signal brut à l'aide du codec audio neural EnCodec. Cela fournit un nouveau "vocabulaire" fixe pour les échantillons de musique. Il est alors possible de former des modèles de langage autorégressifs sur ces tokens audio discrets pour générer de nouveaux tokens et de nouveaux sons et musiques lors de la conversion des tokens en espace audio avec le décodeur d'EnCodec.
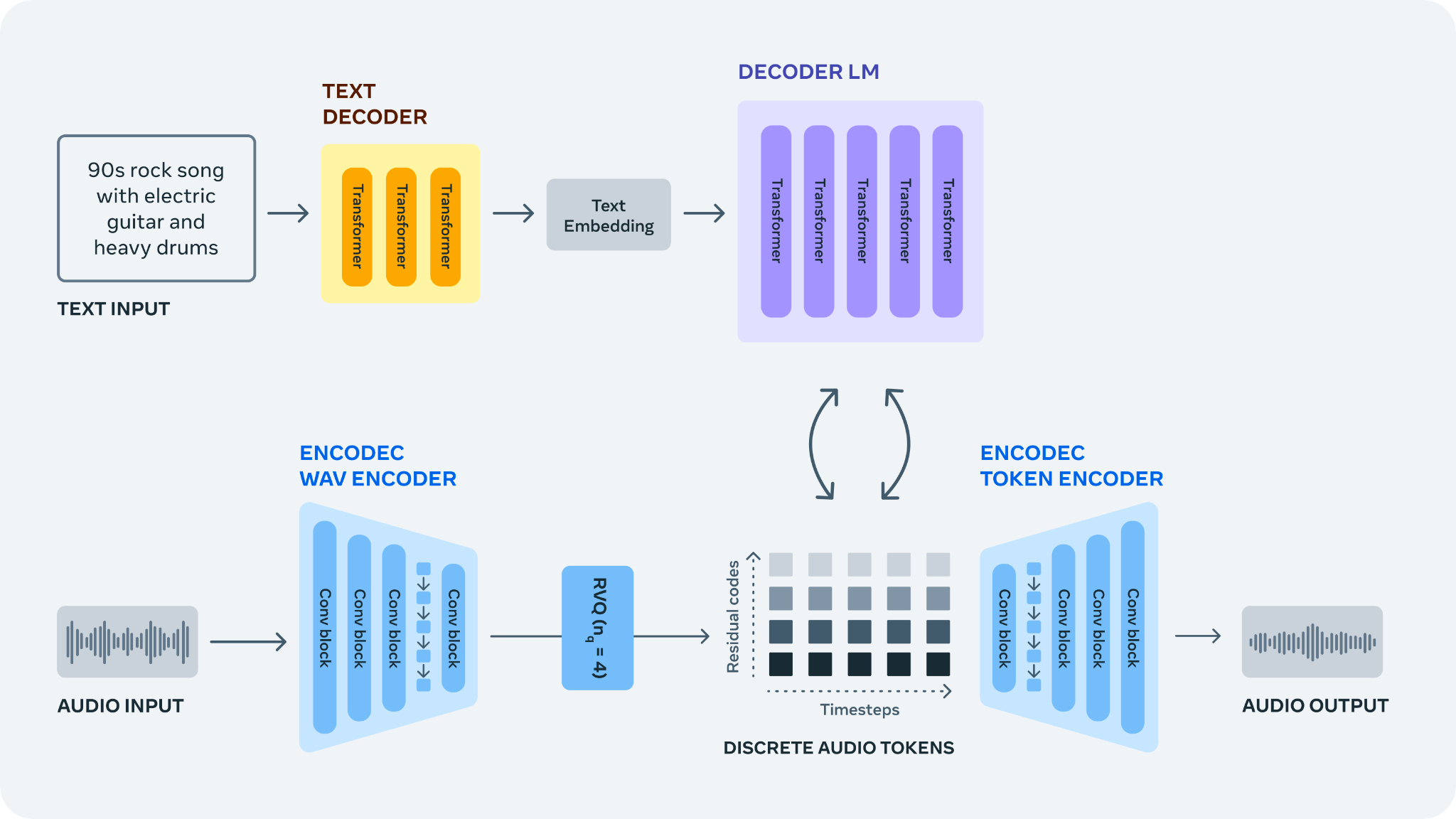
La génération d'audio à partir de descriptions textuelles
Avec AudioGen, il a été démontré qu'il est possible de former des modèles d'IA pour effectuer la tâche de génération de texte en audio. Étant donnée une description textuelle d'une scène acoustique, le modèle peut générer le son environnemental correspondant à la description avec des conditions d'enregistrement réalistes et un contexte de scène complexe.
MusicGen est un modèle de génération audio spécifiquement conçu pour la génération de musique. Les pistes de musique sont plus complexes que les sons environnementaux, et générer des échantillons cohérents sur la structure à long terme est particulièrement important lors de la création de nouvelles pièces musicales. MusicGen a été formé sur environ 400 000 enregistrements avec une description textuelle et des métadonnées, ce qui représente 20 000 heures de musique détenues par Meta ou sous licence spécifiquement pour cet usage.
L'importance du code source ouvert
L'ouverture du code source de la recherche et des modèles qui en résultent est cruciale pour assurer que tous aient un accès égal. Les modèles sont disponibles pour la communauté de recherche à plusieurs tailles et les cartes de modèles AudioGen et MusicGen qui détaillent comment les modèles ont été construits sont partagées, en accord avec les pratiques d'IA responsables. Le code d'entraînement du cadre de recherche audio et le code de formation sont publiés sous licence MIT pour permettre à la communauté au sens large de reproduire et de s'appuyer sur le travail effectué.
La responsabilité et la transparence comme piliers de la recherche
Il est important d'être ouvert sur le travail réalisé afin que la communauté de recherche puisse le développer et poursuivre les discussions importantes sur la manière de construire l'IA de manière responsable. Les concepteurs du projet reconnaissent que les ensembles de données utilisés pour former les modèles manquent de diversité. En particulier, l'ensemble de données musicales utilisé contient une plus grande proportion de musique de style occidental et ne contient que des paires audio-texte avec du texte et des métadonnées écrites en anglais. En partageant le code d'AudioCraft, l'espoir est que d'autres chercheurs pourront plus facilement tester de nouvelles approches pour limiter ou éliminer les biais potentiels dans les modèles génératifs et leur utilisation abusive.
Perspective d'avenir
À l'avenir, l'IA générative pourrait aider les gens à améliorer considérablement le temps d'itération en leur permettant d'obtenir des retours plus rapidement lors des premières phases de prototypage et de "grayboxing". Que ce soit un grand développeur AAA construisant des mondes pour le métaverse, un musicien (amateur, professionnel ou autre) travaillant sur sa prochaine composition, ou un propriétaire de petite ou moyenne entreprise cherchant à améliorer ses ressources créatives, AudioCraft est une étape importante dans la recherche sur l'IA générative. Il est fort à parier que l'approche simple développée pour générer avec succès des échantillons audio robustes, cohérents et de haute qualité aura un impact significatif sur le développement de modèles avancés d'interaction homme-machine prenant en compte les interfaces auditives et multimodales.



