

OpenLLaMA : Une reproduction ouverte du modèle LLaMA

OpenLLaMA est une reproduction open source du modèle de langage LLaMA de Meta AI. Dans cette version, une prévisualisation publique du modèle OpenLLaMA 7B, entraîné sur 200 milliards de tokens, est disponible. Les poids pré-entraînés des modèles OpenLLaMA sont fournis en formats PyTorch et Jax, ainsi que les résultats d'évaluation et une comparaison avec les modèles LLaMA originaux. Des mises à jour sont à venir.
 openlm-research
openlm-researchEntraînement et données
Les modèles OpenLLaMA sont entraînés sur le jeu de données RedPajama, publié par Together, qui est une reproduction du jeu de données d'entraînement LLaMA contenant plus de 1,2 billion de tokens. Les étapes de prétraitement et les hyperparamètres d'entraînement sont les mêmes que ceux du papier original LLaMA, y compris l'architecture du modèle, la longueur du contexte, les étapes d'entraînement, le programme d'apprentissage et l'optimiseur. La seule différence entre les deux est le jeu de données utilisé : OpenLLaMA emploie le jeu de données RedPajama plutôt que celui utilisé par le LLaMA original.
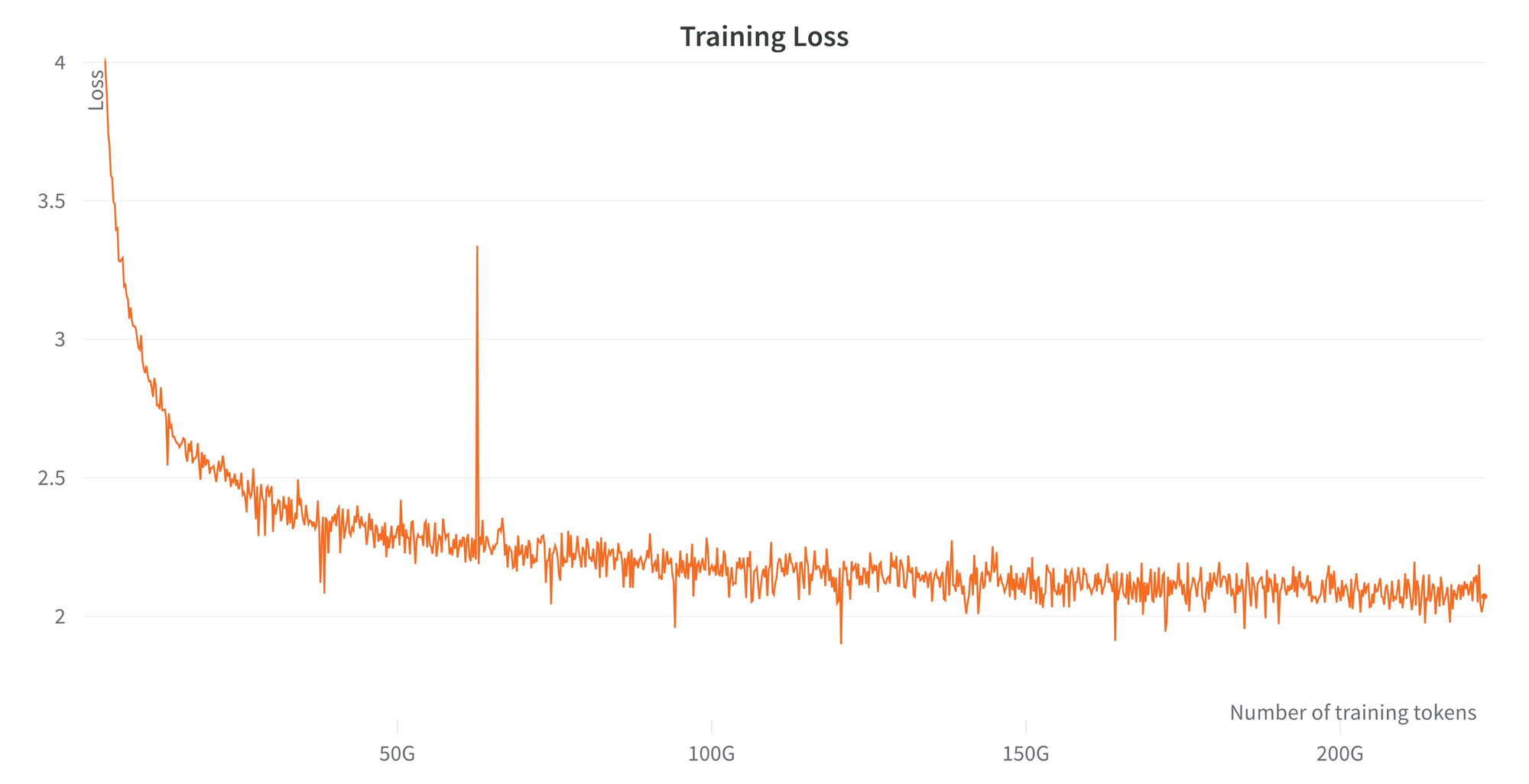
Les modèles sont entraînés sur des TPU-v4s en utilisant EasyLM, une chaîne d'entraînement basée sur JAX développée pour l'entraînement et le réglage fin des modèles de langage. Une combinaison de parallélisme normal des données et de parallélisme entièrement fragmenté des données (également connu sous le nom de ZeRO stage 3) est utilisée pour équilibrer le débit d'entraînement et l'utilisation de la mémoire. Au total, un débit de plus de 1900 tokens/seconde/TPU-v4 est atteint lors de l'entraînement.
Évaluation
OpenLLaMA est évalué sur un large éventail de tâches en utilisant lm-evaluation-harness. Les résultats de LLaMA sont générés en exécutant le modèle LLaMA original sur les mêmes métriques d'évaluation. OpenLLaMA présente des performances comparables à celles du LLaMA original et du GPT-J sur la majorité des tâches, et les dépasse dans certaines tâches. On s'attend à ce que les performances d'OpenLLaMA, une fois l'entraînement terminé sur 1 billion de tokens, soient encore améliorées.
Publication des poids de prévisualisation et utilisation
Pour encourager les retours de la communauté, un point de contrôle de prévisualisation des poids est publié. Ce point de contrôle peut être téléchargé à partir de HuggingFace Hub. Les poids sont publiés dans deux formats : un format EasyLM à utiliser avec le framework EasyLM, et un format PyTorch à utiliser avec la bibliothèque Huggingface Transformers.

Plans futurs
La version actuelle n'est qu'une prévisualisation de ce que la version complète d'OpenLLaMA offrira. L'objectif principal est de terminer le processus d'entraînement sur l'ensemble du jeu de données RedPajama. Cela permettra d'obtenir une comparaison équitable entre le modèle LLaMA original et notre OpenLLaMA. Outre le modèle 7B, un modèle plus petit de 3B est également en cours d'entraînement pour faciliter l'utilisation des modèles de langage dans des cas d'utilisation à faible ressource. Restez à l'écoute pour nos prochaines mises à jour.



