

Transformer : nouvelle méthodologie pour traiter 1 million de tokens et plus
Dans un récent article scientifique, des chercheurs de DeepPavlov, de l'Artificial Intelligence Research Institute (AIRI) et du London Institute for Mathematical Sciences ont présenté une nouvelle méthode pour étendre la capacité des modèles transformer à traiter efficacement de grandes quantités de texte. En exploitant l'architecture du Transformer à mémoire récurrente (Recurrent Memory Transformer, RMT), ils ont augmenté la longueur du contexte pris en charge par les modèles transformer jusqu'à un niveau sans précédent de deux millions de tokens, tout en maintenant une précision élevée pour la récupération de la mémoire.
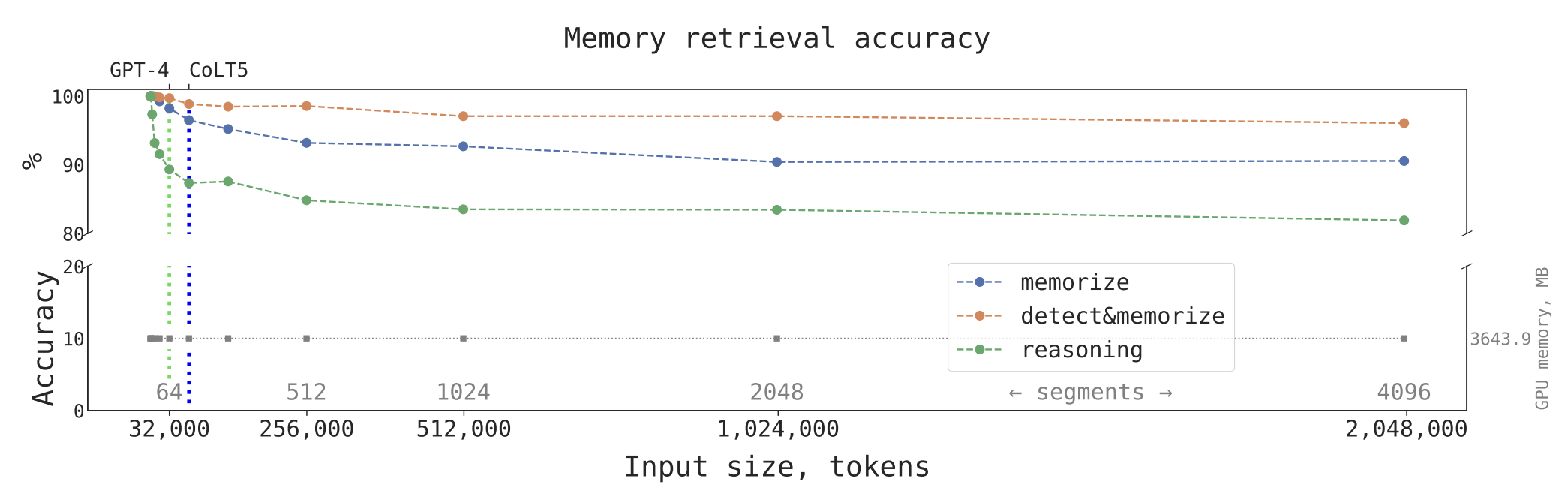
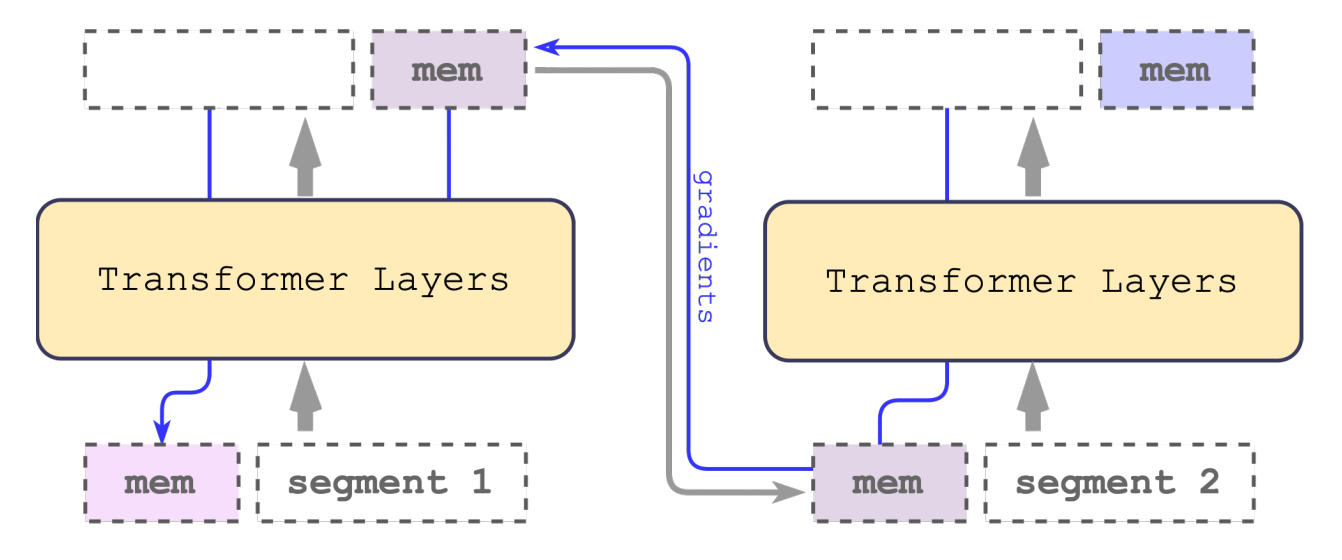
Transformer à mémoire récurrente (RMT)
RMT peut être appliqué à une variété de modèles transformer populaires, tels que BERT, sans modifications majeures. En divisant le texte en segments et en traitant les segments séquentiellement, RMT préserve la mémoire tout en permettant à l'information de circuler entre les segments de la séquence d'entrée à l'aide de connexions récurrentes.
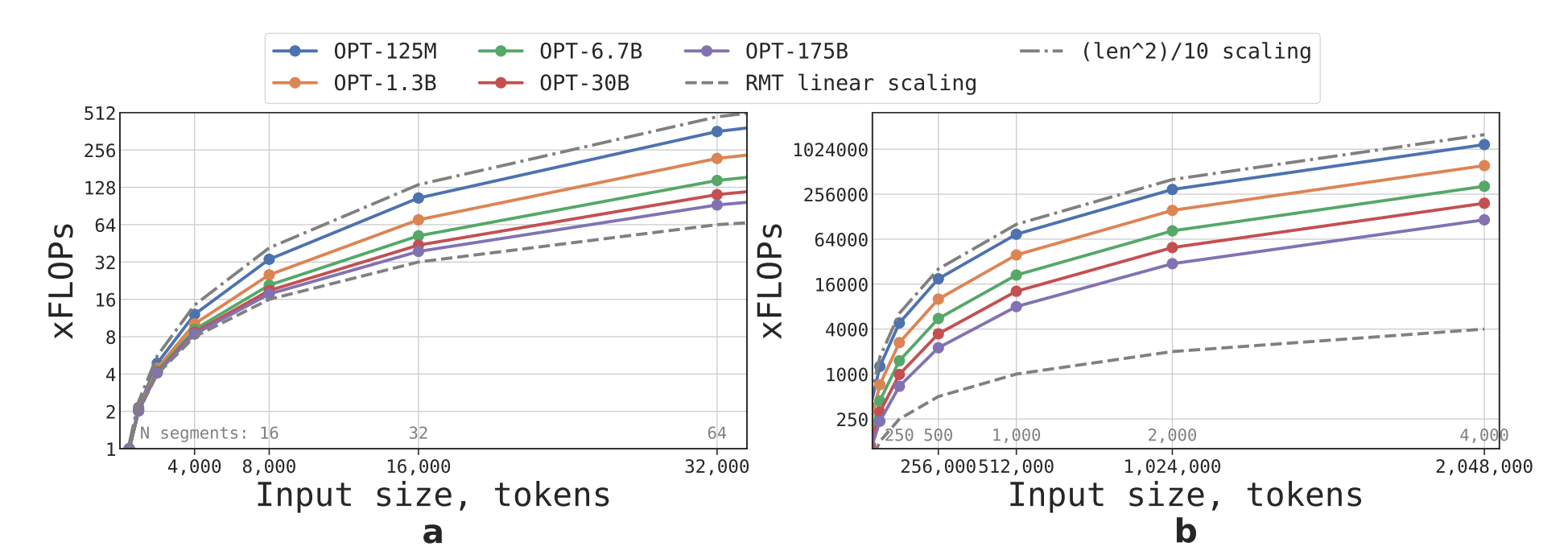
Efficacité computationnelle
Comparer au modèle transformer de base, RMT réduit considérablement le nombre de FLOPs et améliore l'efficacité computationnelle. Au fur et à mesure que la taille des séquences d'entrée augmente, RMT offre un important gain en termes FLOPs par rapport aux modèles non récurrents.
Expériences et résultats
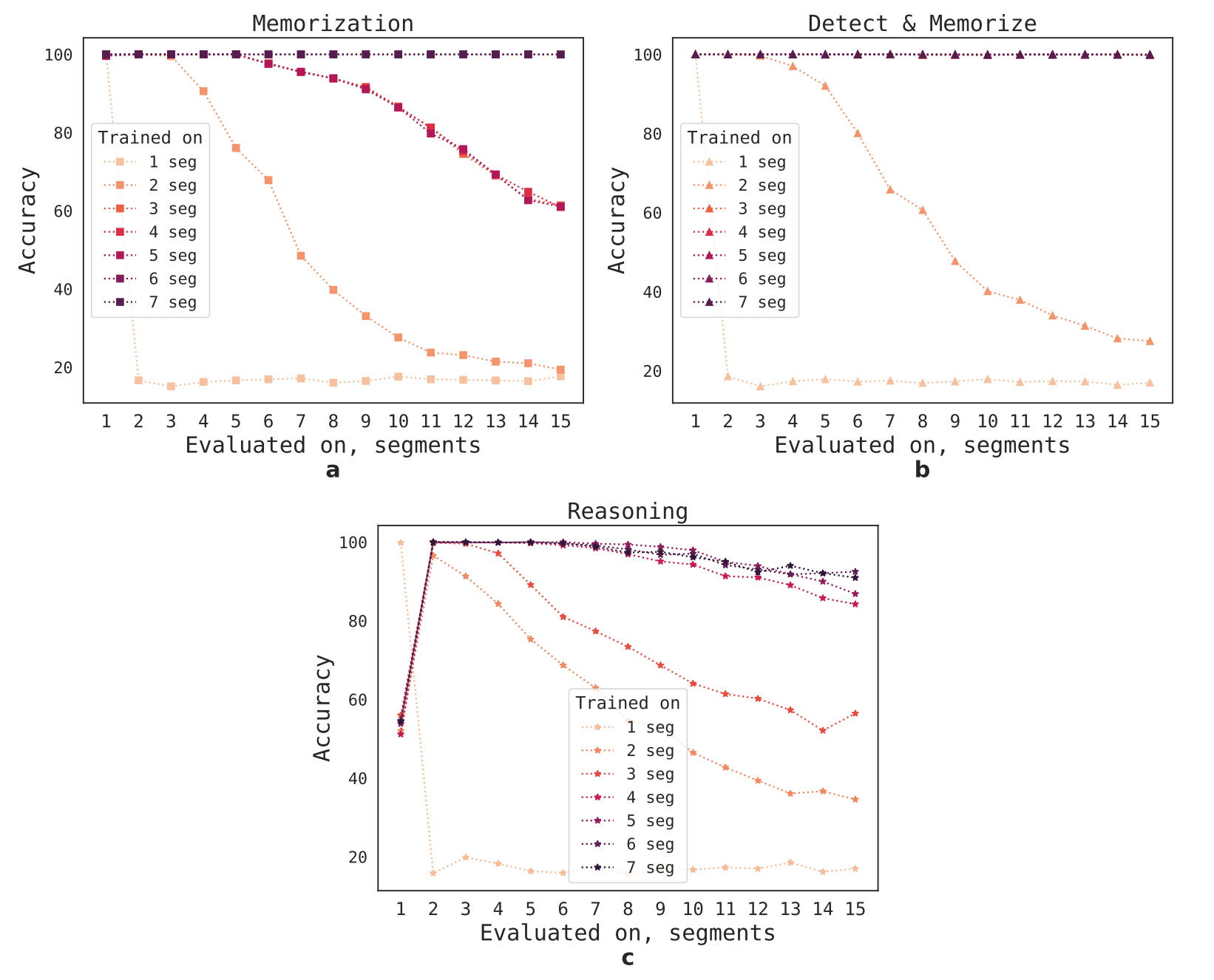
Les chercheurs ont utilisé le modèle BERT pré-entraîné comme base pour RMT. Ils ont mené des expériences avec des tâches de mémorisation synthétiques qui exigent la mémorisation de faits simples et le raisonnement de base. Les modèles RMT ont été évalués sur des tâches plus longues pour vérifier la généralisation et l'extrapolation à des longueurs de séquence inédites.
La méthode curriculum learning a été appliquée pour améliorer l'exactitude et la stabilité des solutions lorsque RMT est confronté à des tâches de longueur variable.
Analyse des motifs d'attention des opérations de mémoire
En examinant les motifs d'attention de RMT, les chercheurs ont constaté que les opérations de mémoire correspondantes sont associées à des motifs spécifiques dans l'attention. Cette observation est particulièrement impressionnante, car ces opérations n'étaient pas explicitement motivées par la perte de la tâche.
Travaux connexes
Plusieurs autres méthodes ont été développées pour améliorer l'efficacité des modèles transformer dans le traitement de longues séquences, notamment Transformer-XL, Longformer, GMAT, ETC et Big Bird. Cependant, ces approaches ont toujours des limitations quant à la mémoire et l'évolutivité.
Conclusion
Grâce à l'approche récurrente et à l'utilisation de la mémoire, la complexité quadratique des modèles transformer a été réduite à une complexité linéaire. Les modèles RMT peuvent généraliser leurs capacités à des textes considérablement plus longs lorsqu'ils sont entraînés sur des entrées suffisamment grandes. Dans les travaux futurs, les chercheurs prévoient d'adapter l'approche de la mémoire récurrente aux modèles transformers les plus couramment utilisés pour améliorer davantage la taille du contexte effectif.
Source : arXiv



