

Uber accélère les réseaux neuronaux grâce au format JPEG

Uber AI Labs a récemment introduit une méthode pour rendre les réseaux neuronaux qui traitent les images plus rapides et plus précis. Cette méthode exploite les représentations internes d'images déjà utilisées par le format d'image JPEG.
L'approche d'Uber
Uber utilise les réseaux neuronaux convolutionnels (CNN) pour diverses applications, notamment la détection d'objets, la prédiction de leur mouvement et le traitement de pétaoctets d'images de rue et de satellite pour améliorer ses cartes. Lors de l'utilisation d'un CNN, Uber se soucie non seulement de la précision de la tâche, mais aussi de la vitesse à laquelle elle est accomplie.
Dans un article, Uber décrit une approche présentée à NeurIPS 2018 pour rendre les CNN plus petits, plus rapides et plus précis en même temps en exploitant libjpeg et en utilisant les représentations internes d'images déjà utilisées par le format d'image JPEG.
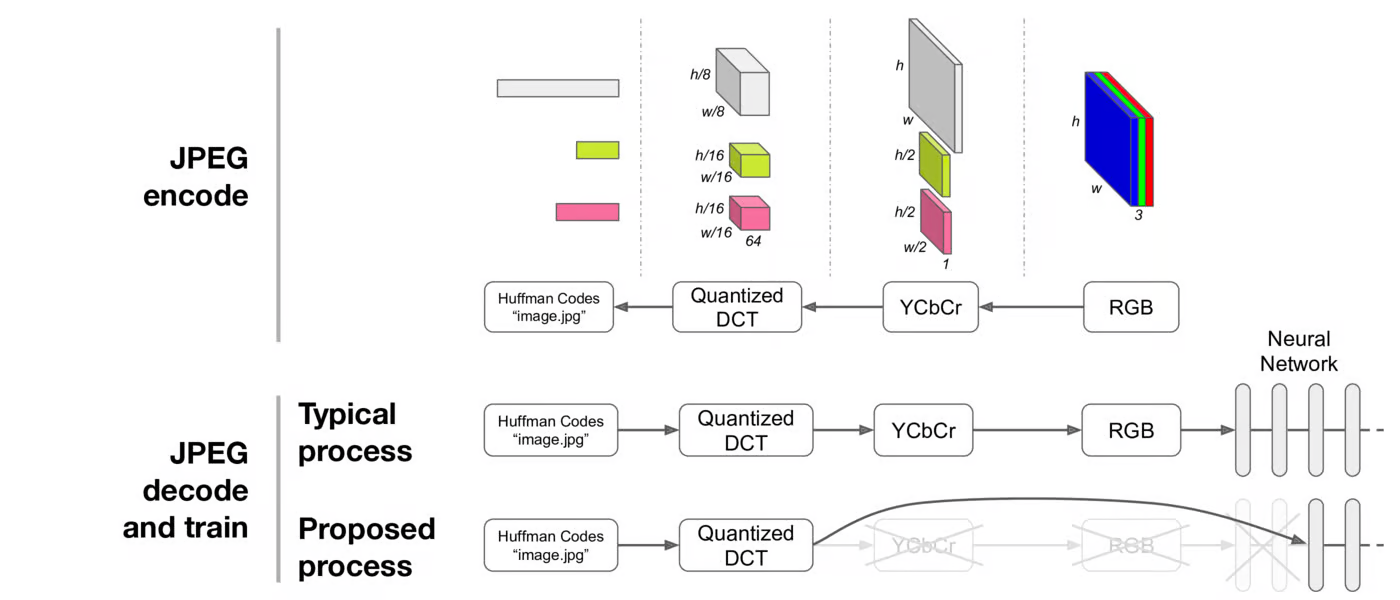
Comment fonctionne le JPEG
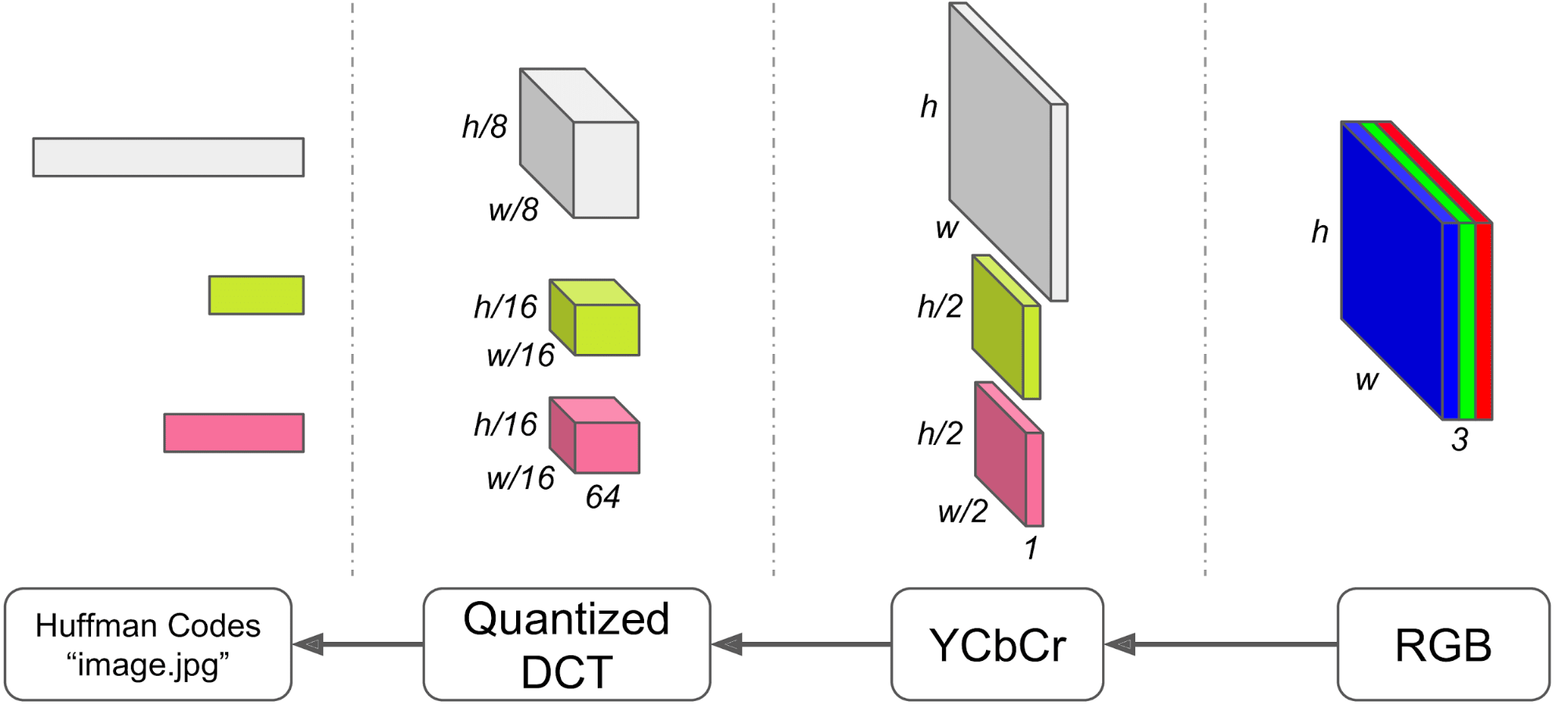
Le format JPEG, bien qu'ancien, reste l'un des formats d'image les plus largement utilisés. Le processus d'encodage JPEG comprend plusieurs étapes, notamment la conversion de l'image en espace colorimétrique YCbCr, la sous-échantillonnage des canaux Cb et Cr, la division de chaque canal en blocs de 8x8 et la transformation en espace de fréquence à l'aide de la transformée en cosinus discrète (DCT). Les coefficients DCT sont ensuite quantifiés et compressés sans perte en utilisant une variante de l'encodage Huffman.
Formation de réseaux sur les entrées DCT
Pour former un réseau à partir d'une représentation JPEG, Uber a dû d'abord résoudre le problème des différentes tailles d'entrée. Le réseau ResNet-50 standard est conçu pour des entrées de forme (224, 224, 3), tandis que les coefficients DCT ont une forme très différente. Pour résoudre ce problème, Uber a proposé deux familles de transformations T1 et T2 : celles qui fusionnent les chemins tôt en utilisant au plus des transformations monocouches, et celles qui effectuent un traitement plus significatif en premier, fusionnant les chemins tard.

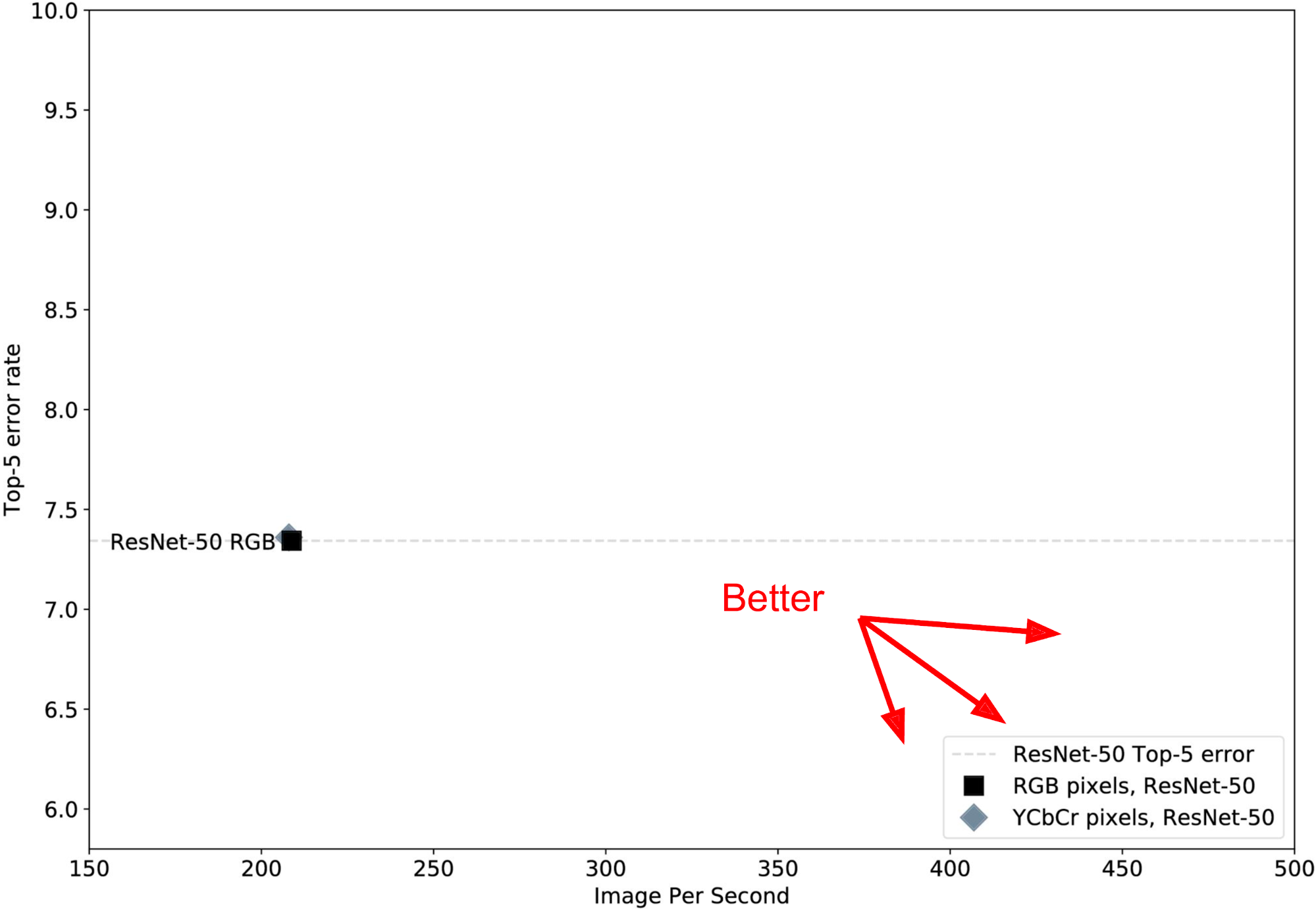
Résultats et directions futures
Les résultats obtenus par Uber sont encourageants. En formant des réseaux à partir d'une représentation JPEG, ils ont réussi à obtenir des réseaux à la fois précis et rapides à exécuter. Les gains de vitesse sont dus à un volume de données plus petit sur la couche d'entrée et les couches suivantes. Les gains de précision sont principalement dus à l'utilisation spécifique d'une représentation DCT, qui fonctionne étonnamment bien pour la classification d'images.
Les directions futures suggérées par ces résultats incluent l'évaluation de différentes représentations de l'espace de fréquence, des DCT de différentes tailles, et la performance sur la détection, la segmentation, et d'autres tâches de traitement d'images.
Questions à considérer
- Comment l'approche d'Uber pourrait-elle être appliquée à d'autres types de données en plus des images ?
- Quels pourraient être les avantages et les inconvénients potentiels de l'utilisation de la représentation DCT pour la formation de réseaux neuronaux ?
- Comment cette méthode pourrait-elle être améliorée ou adaptée pour d'autres applications de l'IA ?



