

Un script Python de 15 lignes peut-il réellement rivaliser avec les poids lourds de l'intelligence artificielle ?

Une équipe de chercheurs de l'Université de Waterloo, au Canada, aurait récemment publié une découverte pour le moins surprenante : un programme d'intelligence artificielle (IA) écrit en 15 lignes de code Python pourrait rivaliser avec les modèles les plus avancés dans le domaine du Machine Learning.
Contexte : La Classification de Texte
La classification de texte est l'une des disciplines les plus actives de l'intelligence artificielle. Elle consiste à trier automatiquement des textes courts dans un ensemble de catégories prédéfinies. Pour évaluer la performance d'un modèle, les chercheurs travaillent avec des bases de données spécifiques, comme celle basée sur 1.4 millions de questions posées sur le site Yahoo Answers, réparties en 10 catégories. L'algorithme peut ainsi utiliser ces données pour apprendre à quoi ressemblent les questions de chaque catégorie. Il sera ensuite mis à l'épreuve avec 60 000 questions non-étiquetées pour lesquelles il devra prédire la catégorie.
Mesure de Performance : L'Accuracy
Plusieurs méthodes permettent de mesurer la performance d'un modèle de Machine Learning. La plus courante est l'accuracy, ou "précision" en français, qui est calculée en déterminant le taux de bonnes réponses. Par exemple, un modèle qui donne 45k catégories correctes sur les 60k textes aura un score de 75%. Parmi les modèles textuels les plus performants, on retrouve notamment BERT, publié en open source par Google en 2018, avec ses 340 millions de neurones.
Le Défi de Waterloo : Un Script de 15 Lignes
C'est face à ce colosse de l'IA que les chercheurs de l'université de Waterloo ont décidé de créer un script simple de 15 lignes. Et le résultat est étonnant.
import gzip
import numpy as np
for (x1, _) in test_set:
Cx1 = len(gzip.compress(x1.encode()))
distance_from_x1 = []
for (x2, _) in training_set:
Cx2 = len(gzip.compress(x2.encode()))
x1x2 = " ".join([x1, x2])
Cx1x2 = len(gzip.compress(x1x2.encode()))
ncd = (Cx1x2 - min(Cx1, Cx2)) / max(Cx1, Cx2)
distance_from_x1.append(ncd)
sorted_idx = np.argsort(np.array(distance_from_x1))
top_k_class = training_set[sorted_idx[:k], 1]
predict_class = max(set(top_k_class), key=top_k_class.count)L'algorithme utilise des opérations de la forme len(gzip.compress(x)), révélant le secret de son efficacité. Gzip est un utilitaire de compression de fichiers qui réduit la taille du fichier sans perte d'information, en trouvant des motifs qui se répètent dans les données à compresser. Ce facteur de compression peut être utilisé pour mesurer la redondance d'information dans un texte, ce qui se révèle très utile dans la classification de texte.
Sans compression, une série de mots "banane" répétée 5 fois est stockée telle quelle :
| banane | banane | banane | banane | banane |
|---|
Avec la compression, nous stockons une instance de "banane" et comptons combien de fois elle est répétée :
| banane | 5 |
|---|
La version compressée est beaucoup plus petite car nous stockons le mot "banane" une fois, puis comptons simplement combien de fois il se répète.
Comprendre la Méthode
L'équipe de chercheurs a mis au point une formule, basée sur des concepts comme la distance de Kolmogorov conditionnelle et l'information algorithmique mutuelle, permettant de calculer une sorte de "distance sémantique" entre deux textes. En somme, cette formule permet de déterminer la similarité entre deux textes, ce qui s'avère être un moyen puissant de classification.
On peut exploiter le principe de compression pour analyser le niveau de redondance dans un document !
J'ai effectué une compression de 1500 caractères de la page Wikipédia "Machine learning" et 1500 caractères générés aléatoirement. Les résultats obtenus sont les suivants : 650 octets pour le texte de Wikipédia compressé contre 950 octets pour le texte aléatoire compressé.
Il est ainsi évident qu'un texte en français présente plus de redondance (c'est-à-dire moins d'entropie), ce qui permet une compression plus efficace.
De plus, la fusion de deux textes se compressera d'autant plus facilement que les deux textes sont similaires :
la compression conjointe de l'article sur le "football" et de l'article sur le "rugby" donne un résultat de 1000 octets. Tandis que la compression conjointe de l'article sur le "football" et de l'article sur "l'espace" donne un résultat de 1200 octets.
Sur la base de ces constatations, nous pouvons établir un mécanisme pour mesurer une sorte de "distance sémantique" entre deux textes !
La formule ci-dessous est celle qui est utilisée par les chercheurs dans leur article :
\[ NCD(x, y) = \frac{C(xy) - \min(C(x), C(y))}{\max(C(x), C(y))} \]
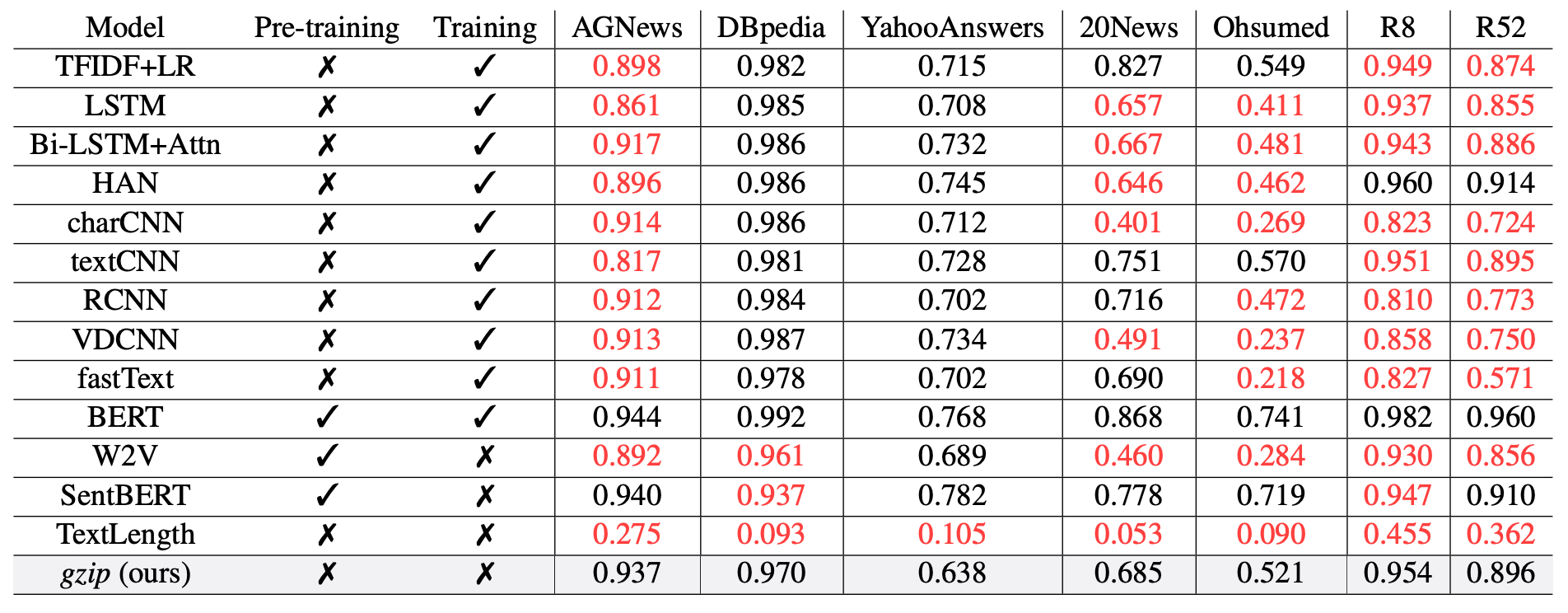
Impressionnants Résultats Pratiques
Sur un benchmark comprenant 13 modèles récents, cet algorithme se classe sur le podium à plusieurs reprises, et atteint même la première place sur de nombreux datasets non-anglais. Même si BERT semble généralement plus efficace, cette technique présente trois avantages majeurs : sa simplicité de mise en œuvre, aucun pré-entraînement nécessaire, et une bonne performance dans toutes les langues.
Optimisation et Compactage du Code
Le code, bien que déjà minimaliste, n'est pas exempt d'optimisations possibles. Par exemple, en utilisant un tas binaire, une structure de données spécialisée, il est possible d'améliorer la performance du calcul. De plus, grâce à certaines techniques, le script peut être encore plus compacté, passant de 538 à 214 caractères, sans compromettre son efficacité :
import gzip,heapq
g=lambda x:len(gzip.compress(x))
def classify(t):
A=g(t)
h=[(-1,)]*K
for(a,b)in train:heapq.heappushpop(h,((min(A,g(a))-g(t+b' '+a))/max(A,g(a)),b))
s=[x[1]for x in h]
return max(set(s),key=s.count)Nous pouvons aussi améliorer sa lisibilité, au détriment de sa longueur. Pour améliorer la lisibilité, nous pouvons adopter une approche plus orientée objet et diviser le code en fonctions plus petites, chacune ayant une responsabilité claire. Cela rendra le code plus lisible et plus maintenable. Voici un exemple d'amélioration :
import gzip
import numpy as np
class Classifier:
def __init__(self, training_set, k):
self.training_set = training_set
self.k = k
def compress(self, text):
return len(gzip.compress(text.encode()))
def ncd(self, x1, x2):
x1_compressed = self.compress(x1)
x2_compressed = self.compress(x2)
x1x2_compressed = self.compress(" ".join([x1, x2]))
return (x1x2_compressed - min(x1_compressed, x2_compressed)) / max(x1_compressed, x2_compressed)
def classify(self, test_set):
for x1, _ in test_set:
distances = [(self.ncd(x1, x2), y) for x2, y in self.training_set]
distances.sort(key=lambda x: x[0])
top_k_classes = [y for _, y in distances[:self.k]]
yield max(set(top_k_classes), key=top_k_classes.count)
classifier = Classifier(training_set, k=5)
predictions = classifier.classify(test_set)
Dans ce code, nous avons une classe Classifier qui est initialisée avec le training_set et k. Elle a trois méthodes : compress pour compresser un texte, ncd pour calculer la distance de compression normalisée entre deux textes, et classify pour classer un test_set. Le résultat de classify est un générateur qui produit les classes prédites pour chaque élément du test_set.
Cela rend le code beaucoup plus organisé et chaque fonction a une responsabilité claire, ce qui rend le code plus lisible et plus facile à maintenir.
En conclusion, même si la domination des modèles à grande échelle comme BERT est loin d'être remise en question, cette découverte souligne la valeur et le potentiel de solutions alternatives plus simples, ouvrant ainsi des perspectives intéressantes dans le domaine de l'intelligence artificielle.
Mise en garde importante
Une analyse plus approfondie a soulevé des questions cruciales sur les méthodes utilisées dans le papier de recherche que nous venons de discuter. Il semblerait qu'il y ait une confusion significative autour de l'implémentation de l'algorithme k-Nearest Neighbors (kNN) dans le cadre de cette étude. Plus précisément, la précision rapportée semble plus proche d'une précision "top-2" plutôt que d'une précision standard pour kNN avec k=2.
De plus, le traitement des cas d'égalité (quand les deux labels les plus proches sont différents) a été remis en question. Le code source du papier marquerait un test comme correct si l'un des deux labels les plus proches correspond au label du test. Cette approche déroge à l'implémentation standard de kNN et peut potentiellement mener à des résultats surévalués.
En tenant compte de ces éléments, les résultats corrigés pour cette recherche montrent une performance significativement plus faible que celle initialement rapportée. Par exemple, pour le jeu de données "KirundiNews", la méthode gzip serait passée de la meilleure à la pire performance.
Il est donc impératif de traiter les conclusions de ce papier avec prudence. Bien que l'idée d'utiliser gzip pour la classification de texte en ressources faibles soit innovante et intrigante, il est nécessaire de réaliser des analyses plus approfondies pour vérifier la validité de ces résultats. Des pratiques rigoureuses de recherche et d'évaluation sont essentielles pour faire avancer le domaine de l'apprentissage automatique.



