

Une nouvelle vulnérabilité découverte dans les grands modèles de langage

Qu'est-ce qu'un grand modèle de langage ?
Les grands modèles de langage (LLM) utilisent des techniques d'apprentissage profond pour traiter et générer du texte semblable à celui des humains. Ces modèles s'entraînent sur d'immenses quantités de données issues de livres, d'articles, de sites web et d'autres sources pour générer des réponses, traduire des langues, résumer du texte, répondre à des questions et effectuer une vaste gamme de tâches de traitement du langage naturel.
Cette technologie d'intelligence artificielle en rapide évolution a conduit à la création d'outils en open source et en closed source, tels que ChatGPT, Claude et Google Bard, permettant à quiconque de rechercher et de trouver des réponses à une gamme apparemment infinie de requêtes. Bien que ces outils offrent des avantages significatifs, il y a une préoccupation croissante quant à leur capacité à générer du contenu répréhensible et les conséquences qui en résultent.

Découverte d'une nouvelle vulnérabilité
Des chercheurs de la School of Computer Science de l'Université Carnegie Mellon, du CyLab Security and Privacy Institute et du Center for AI Safety à San Francisco ont découvert une nouvelle vulnérabilité, proposant une méthode d'attaque simple et efficace qui pousse les modèles de langage alignés à générer des comportements répréhensibles avec un taux de succès élevé.

Dans leur dernière étude, intitulée "Universal and Transferable Adversarial Attacks on Aligned Language Models", les professeurs associés de CMU, Matt Fredrikson et Zico Kolter, l'étudiant en doctorat Andy Zou et l'ancien élève Zifan Wang ont trouvé un suffixe qui, lorsqu'il est attaché à un large éventail de requêtes, augmente considérablement la probabilité que les LLM, qu'ils soient open-source ou closed-source, produisent des réponses affirmatives à des requêtes qu'ils refuseraient autrement. Leur approche produit automatiquement ces suffixes adverses grâce à une combinaison de techniques de recherche gourmandes et basées sur le gradient.
"Pour le moment, les préjudices directs aux personnes qui pourraient être causés par l'incitation d'un chatbot à produire du contenu répréhensible ou toxique peuvent ne pas être particulièrement graves," a déclaré Fredrikson. "Mais la préoccupation est que ces modèles jouent un rôle plus important dans les systèmes autonomes qui fonctionnent sans supervision humaine. À mesure que les systèmes autonomes deviennent plus réels, il sera très important de s'assurer que nous avons un moyen fiable d'empêcher qu'ils soient détournés par des attaques de ce type."
Attaques adverses et implications
En 2020, Fredrikson et d'autres chercheurs du CyLab et du Software Engineering Institute ont découvert des vulnérabilités au sein des classificateurs d'images, des modèles d'apprentissage profond basés sur l'IA qui identifient automatiquement le sujet des photos. En apportant des modifications mineures aux images, les chercheurs ont pu modifier la façon dont les classificateurs les percevaient et les étiquetaient.
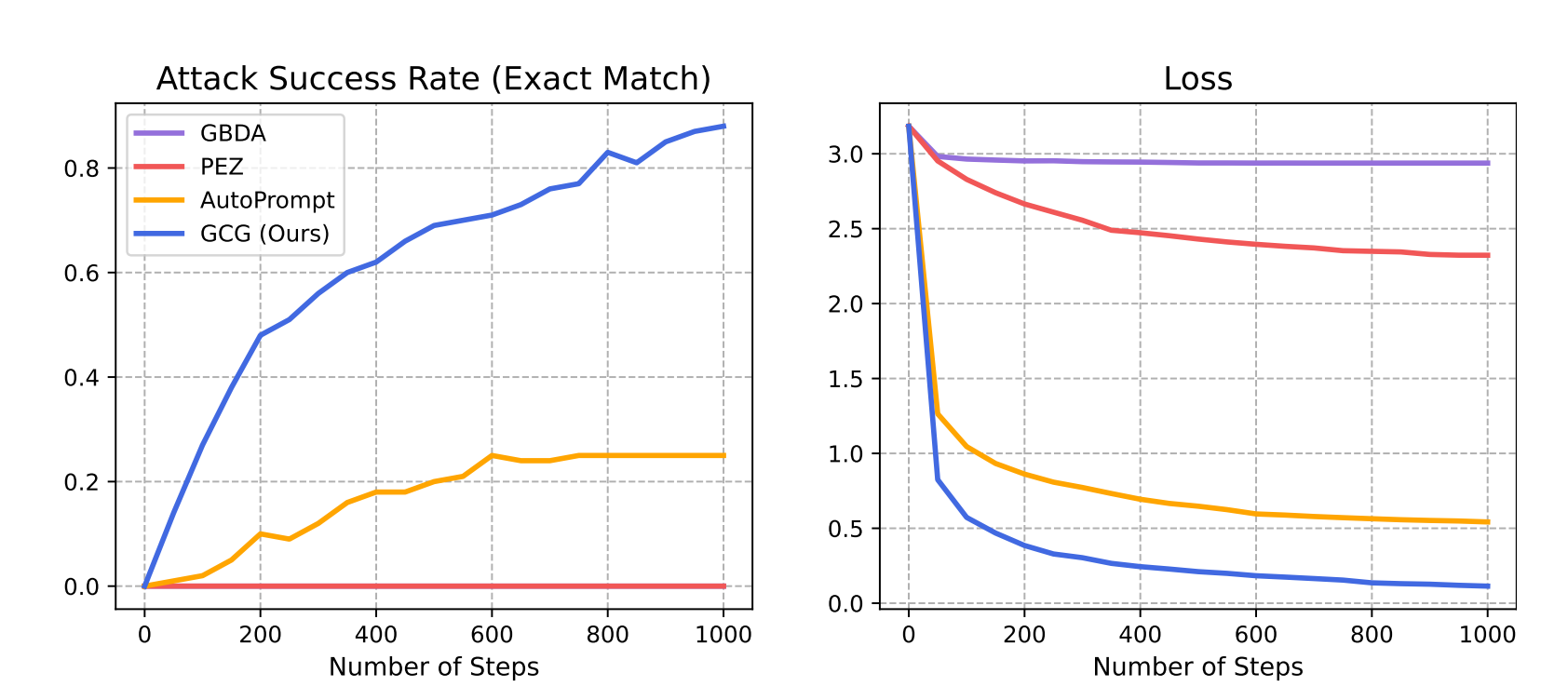
En utilisant des méthodes similaires, Fredrikson, Kolter, Zou et Wang ont réussi à attaquer le chatbot open-source de Meta, incitant le LLM à générer du contenu répréhensible. Pendant qu'ils discutaient de leur découverte, Wang a décidé d'essayer l'attaque sur ChatGPT, un LLM beaucoup plus grand et plus sophistiqué. À leur surprise, cela a fonctionné.
Fredrikson a déclaré : "Nous n'avions pas prévu d'attaquer les grands modèles de langage et les chatbots propriétaires. Mais notre recherche montre que même si vous avez un grand modèle fermé de mille milliards de paramètres, les gens peuvent toujours l'attaquer en regardant des modèles open source plus petits et plus simples et en apprenant comment attaquer ceux-ci."
En entraînant le suffixe d'attaque sur plusieurs incitations et modèles, les chercheurs ont également induit du contenu répréhensible dans des interfaces publiques comme Google Bard et Claud et dans des LLM open-source tels que Llama 2 Chat, Pythia, Falcon et d'autres.
Fredrikson a ajouté : "Pour l'instant, nous n'avons tout simplement pas de moyen convaincant d'empêcher cela, donc la prochaine étape est de comprendre comment corriger ces modèles."
La défense contre ces attaques
Des attaques similaires existent depuis une décennie sur différents types de classificateurs d'apprentissage automatique, comme en vision par ordinateur. Bien que ces attaques posent encore un défi, de nombreuses défenses proposées s'appuient directement sur les attaques elles-mêmes.
Fredrikson conclut : "Comprendre comment monter ces attaques est souvent la première étape dans le développement d'une défense solide."



