

Comment détecter du texte généré par IA, tel que ChatGPT ?

La détection fiable de textes générés par l'IA : est-ce possible ?
Les modèles de langage sont des outils puissants qui peuvent être utilisés pour compléter des documents, répondre à des questions et même générer du texte. Cependant, leur utilisation non réglementée peut entraîner des conséquences malveillantes telles que le plagiat, la génération de fausses nouvelles et le spamming. Il est donc crucial de détecter de manière fiable les textes générés par l'IA afin d'assurer une utilisation responsable de ces modèles.
Les progrès rapides des grands modèles de langage
Au cours des dernières années, les grands modèles de langage (LLM) ont connu un développement fulgurant, leur permettant d'effectuer des tâches impressionnantes. Néanmoins, l'utilisation non encadrée de ces modèles peut entraîner des conséquences néfastes, telles que le plagiat, la diffusion de fausses informations et l'envoi de spams. Par conséquent, il est essentiel d'identifier avec fiabilité les textes générés par l'IA pour garantir un usage responsable de ces modèles.
Les résultats impossibles pour la détection fiable
La détection des abus de modèles linguistiques dans des contextes réels, tels que le plagiat et la propagation massive de propagande, exige l'identification de textes issus de tous les types de modèles linguistiques, y compris ceux sans filigrane. Toutefois, à mesure que ces modèles évoluent et se perfectionnent, les textes générés se rapprochent de plus en plus de ceux rédigés par des humains, rendant ainsi la détection plus ardue. Plus précisément, la distance de variation totale entre les distributions de séquences de texte produites par l'IA et celles créées par des humains se réduit à mesure que les modèles linguistiques se sophistiquent.
Cela implique que les approches de détection traditionnelles, comme l'analyse syntaxique et sémantique, ne suffisent plus pour repérer les textes générés par l'IA. De surcroît, les modèles de langage peuvent être adaptés pour produire des textes similaires à ceux rédigés par des humains grâce à des techniques telles que le "fine-tuning", ce qui rend encore plus délicate la différenciation entre les textes issus de l'IA et ceux écrits par des personnes.
Les résultats de l'étude
Une étude récente conduite par des chercheurs de l'Université du Maryland s'est penchée sur la fiabilité de la détection des textes produits par l'IA. Les chercheurs ont employé une méthode nommée "distance de variation totale" pour évaluer la ressemblance entre les distributions de séquences de texte créées par l'IA et celles écrites par des humains.
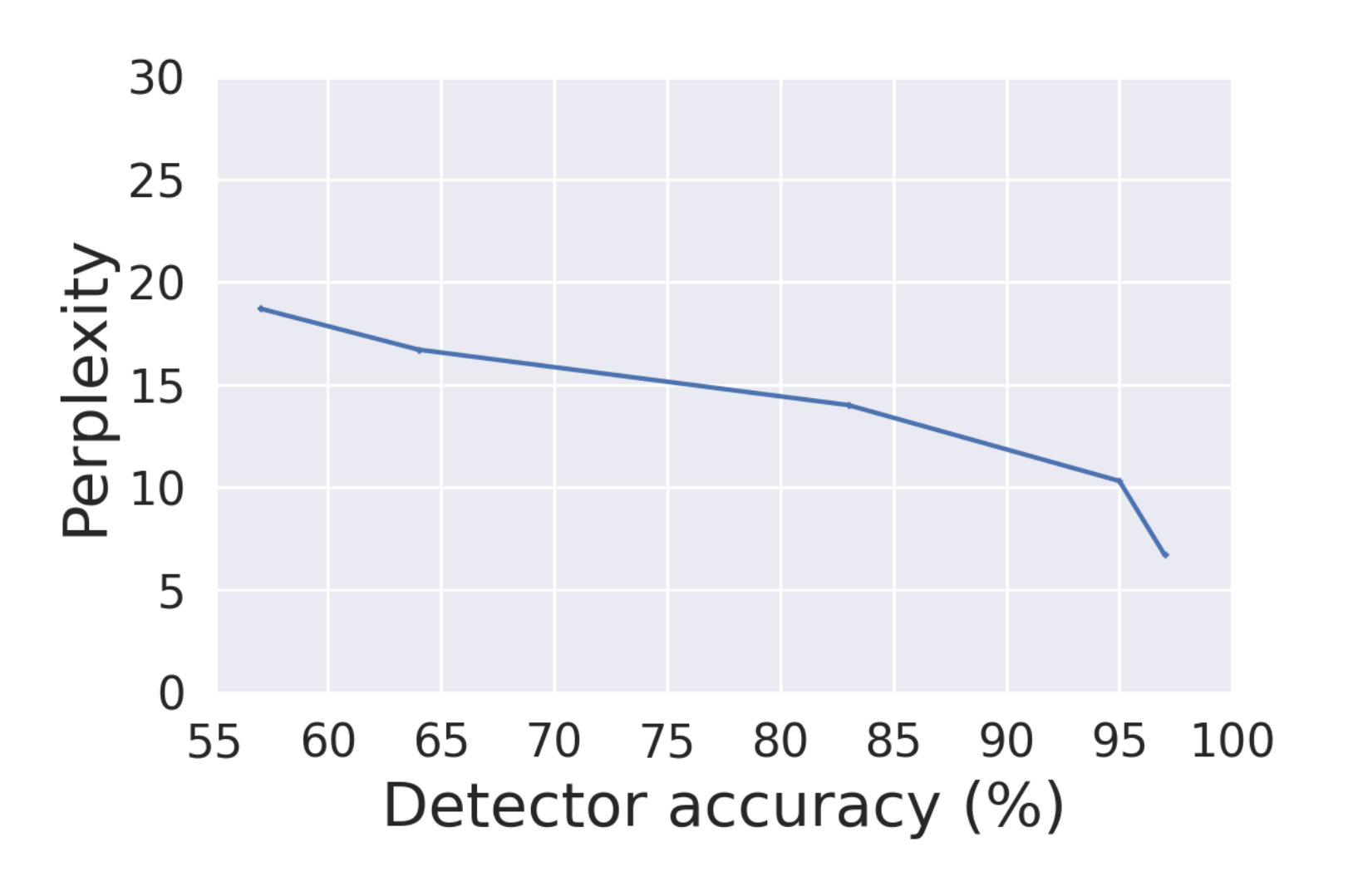
Les résultats ont révélé que la distinction entre le texte issu de l'IA et celui rédigé par des personnes devient de plus en plus difficile à mesure que les modèles linguistiques se complexifient. De plus, il a été constaté que même si le texte généré par l'IA est estampillé d'un filigrane, celui-ci peut être aisément contourné en utilisant un simple outil de reformulation.
Les implications
Les conclusions de cette étude soulignent l'importance des implications liées à la détection fiable des textes créés par l'IA. Les méthodes conventionnelles ne suffisent plus pour identifier ces textes, et l'élaboration de nouvelles approches est indispensable. Cette situation met également en lumière les enjeux liés à la régulation des modèles de langage.
Comment garantir l'utilisation responsable de ces modèles si les textes qu'ils génèrent ne peuvent être détectés de manière fiable ? Il est plausible que des individus malveillants exploitent ces modèles pour produire des textes nuisibles tels que des fake news ou du spam. Il devient donc essentiel de promouvoir une utilisation éthique. Parmi les solutions possibles figurent l'apposition de filigranes sur les textes issus de l'IA et l'instauration de mécanismes de détection plus avancés.
Conclusion
En conclusion, la détection fiable des textes générés par l'IA est un défi important qui nécessite des recherches supplémentaires. Les résultats actuels montrent que les méthodes traditionnelles ne sont plus suffisantes pour détecter ces textes, et qu'il est nécessaire de développer de nouvelles méthodes pour y parvenir. Cela soulève également des questions sur la réglementation de l'utilisation des modèles de langage et sur la nécessité d'une utilisation responsable de ces outils puissants. En fin de compte, il est important d'équilibrer les avantages potentiels des modèles linguistiques avec les risques associés à leur utilisation non réglementée.



