

Comment entraîner vos propres modèles de langage de grande taille (LLM)

Comment Replit entraîne des modèles de langage de grande taille (LLM) en utilisant Databricks, Hugging Face et MosaicML
Retranscription d'un article anglais par Reza SHABANI
Introduction
Les modèles de langage de grande taille, comme GPT-4 d'OpenAI ou PaLM de Google, ont révolutionné le monde de l'intelligence artificielle. Cependant, la plupart des entreprises n'ont pas encore la capacité d'entraîner ces modèles et dépendent entièrement d'un petit nombre de grandes entreprises technologiques comme fournisseurs de cette technologie.
Replit a fortement investi dans l'infrastructure nécessaire pour entraîner leurs propres modèles de langage de grande taille à partir de zéro. Dans cet article, nous donnerons un aperçu de la manière dont ils entraînent les LLMs, depuis les données brutes jusqu'à leur déploiement dans un environnement de production orienté utilisateur. Nous discuterons des défis d'ingénierie auxquels ils sont confrontés en cours de route, et comment ils tirent parti des solutions modernes tel que : Databricks, Hugging Face et MosaicML.
Bien que leurs modèles soient principalement destinés à la génération de code, les techniques et les enseignements abordés sont applicables à tout type de LLM, y compris les modèles de langage général.
Pourquoi entraîner ses propres LLMs ?
Il y a de nombreuses raisons pour lesquelles une entreprise pourrait décider de former elle-même ses LLMs, allant de la confidentialité et la sécurité des données à un meilleur contrôle des mises à jour et des améliorations.
- Personnalisation. Entraîner un modèle personnalisé permet de l'adapter aux besoins et exigences spécifiques, y compris des capacités spécifiques à notre plate-forme, des termes et des contextes qui ne sont pas bien couverts dans les modèles génériques tels que GPT-4 ou même des modèles spécifiques au code comme Codex.
- Réduction de la dépendance. Il est important d'être moins dépendant d'un petit nombre de fournisseurs d'IA. Cela concerne non seulement Replit, mais aussi la communauté des développeurs en général. C'est pourquoi ils prévoient de rendre open source certains de leurs modèles, ce qu'ils ne pourraient pas faire sans les moyens de les entraîner.
- Efficacité des coûts. Bien que les coûts continueront à baisser, les LLMs restent trop onéreux pour une utilisation parmi la communauté mondiale des développeurs.
Canaux de données
Les LLMs nécessitent une quantité immense de données pour être entraînés. Les entraîner nécessite la construction de canaux de données robustes et hautement optimisés, tout en étant suffisamment flexibles pour inclure facilement de nouvelles sources de données publiques et propriétaires.
The Stack
Nous commençons par utiliser The Stack comme notre principale source de données, disponible sur Hugging Face. Hugging Face est une excellente ressource pour les jeux de données et les modèles pré-entraînés. Ils proposent également divers outils utiles dans le cadre de la bibliothèque Transformers, notamment des outils pour la tokenisation, l'inférence des modèles et l'évaluation du code.

The Stack est mis à disposition par le projet BigCode. Les détails de la construction de l'ensemble de données sont disponibles dans Kocetkov et al. (2022). Après déduplication, la version 1.2 de l'ensemble de données contient environ 2,7 To de code source sous licence permissive, écrit dans plus de 350 langages de programmation.
La bibliothèque Transformers gère efficacement bon nombre des défis associés à l'entraînement des modèles, y compris la gestion des données à grande échelle. Cependant, elle peut être insuffisante pour ce processus, si vous avez besoin d'un contrôle supplémentaire sur les données et de la capacité de les traiter de manière distribuée.
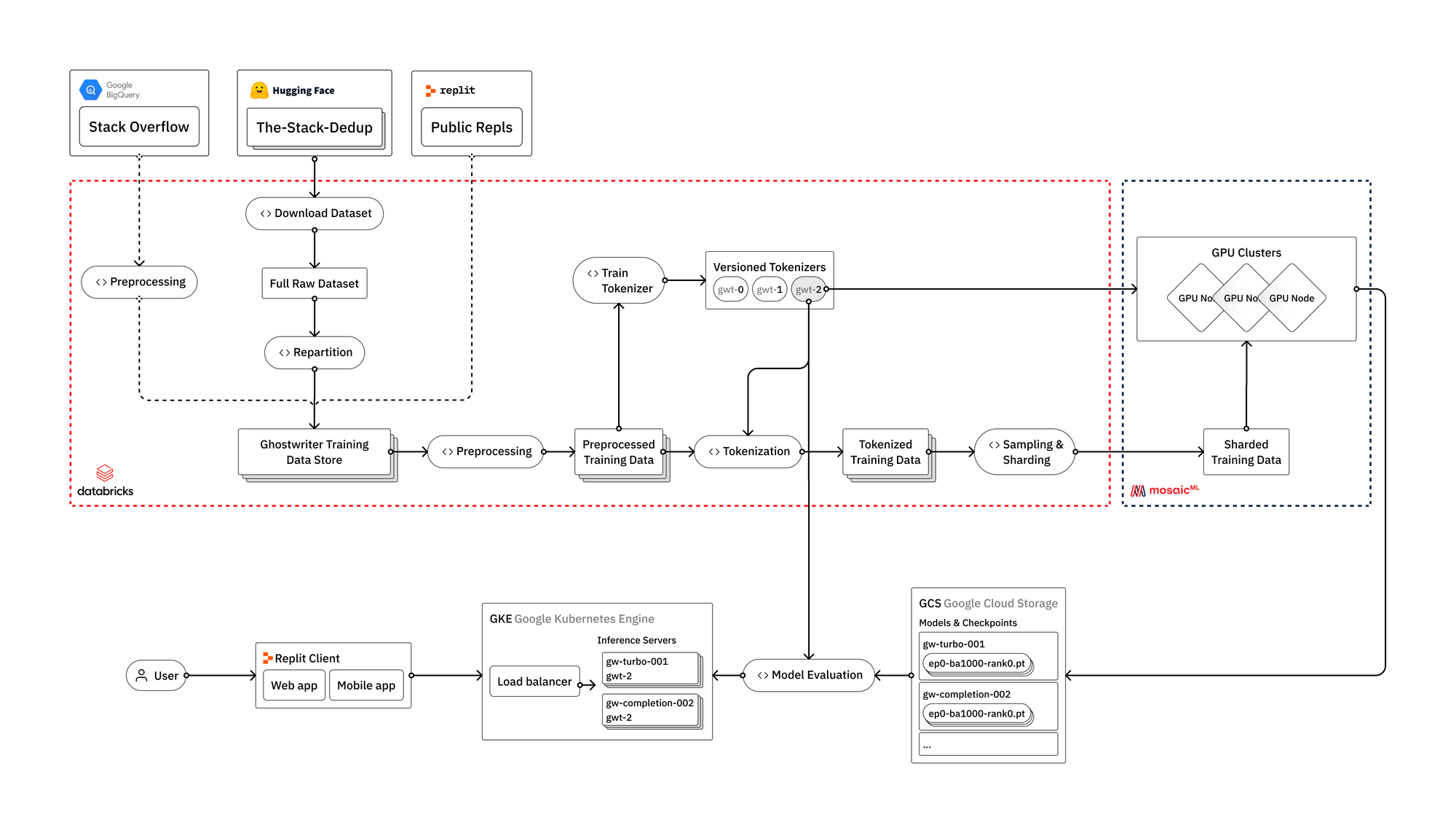
Traitement des données
Pour un traitement avancé des données, Databricks permet de construire des pipelines. Cette approche facilite également l'intégration de sources de données supplémentaires (telles que Replit ou Stack Overflow) dans le processus, que nous prévoyons de faire dans les prochaines itérations.

La première étape consiste à télécharger les données brutes depuis Hugging Face. Avec Apache Spark pour paralléliser le processus de création de l'ensemble de données pour chaque langage de programmation. Il faut ensuite répartir les données et les réécrire au format parquet avec des paramètres optimisés pour le traitement en aval.
Ensuite, procéder au nettoyage et à la préparation de nos données. Normalement, il est important de dédoublonner les données et de corriger divers problèmes d'encodage, mais The Stack a déjà effectué cela pour nous en utilisant une technique de déduplication presque parfaite décrite dans Kocetkov et al. (2022). Cependant, il faudra relancer le processus de déduplication une fois que nous commencerons à intégrer les données Replit dans les pipelines. C'est là qu'il est avantageux d'utiliser un outil comme Databricks, où nous pouvons traiter The Stack, Stackoverflow et les données Replit comme trois sources au sein d'un même lac de données, et les utiliser selon les besoins du processus en aval.
L'utilisation de Databricks est avantageuse car elle permet des analyses évolutives et traçables sur les données sous-jacentes. Les équipes peuvent exécuter des statistiques sommaires sur les sources de données, vérifier les distributions à longue traîne et diagnostiquer les problèmes ou incohérences dans le processus. Ils travaillent dans des carnets Databricks qui peuvent être intégrés à MLFlow pour suivre et reproduire toutes les analyses en cours de route. Cette étape régulière d'analyse des données permet d'éclairer les différentes étapes de prétraitement effectuées.
Pour le prétraitement, Replit prend les mesures suivantes :
- Anonymiser les données en supprimant toute information d'identification personnelle (PII), notamment les adresses e-mail, les adresses IP et les clés secrètes.
- Utilisation de plusieurs heuristiques pour détecter et supprimer le code généré automatiquement.
- Pour un sous-ensemble de langages, supprimer les codes non compilables ou non analysables à l'aide de parseurs de syntaxe standard.
- Filtrer les fichiers en fonction de la longueur de ligne moyenne, de la longueur de ligne maximale et du pourcentage de caractères alphanumériques.
Tokenisation et apprentissage du vocabulaire
Avant d'effectuer la tokenisation, l'équipe en charge de l'entraînement du modèle entraîne un vocabulaire personnalisé en utilisant un sous-échantillon aléatoire des mêmes données.
Cette étape permet au modèle de mieux comprendre et de générer le contenu du code, ce qui se traduit par une amélioration des performances du modèle et une accélération de l'entraînement et de l'inférence du modèle. Cette étape est cruciale, car elle est utilisée dans les trois étapes du processus (canaux de données, entraînement du modèle, inférence). Elle souligne l'importance d'avoir une infrastructure robuste et entièrement intégrée pour le processus d'entraînement des modèles.
Une fois le vocabulaire personnalisé formé, le processus se poursuit avec la tokenisation des données et la construction d'un jeu de données d'entraînement dans un format fragmenté optimisé pour être utilisé dans le processus d'entraînement du modèle.
Entraînement du modèle
L'entreprise utilise la plate-forme MosaicML pour entraîner ses modèles. Elle a auparavant déployé ses propres clusters d'entraînement, mais a constaté que MosaicML offre plusieurs avantages clés en termes d'efficacité, de facilité d'utilisation et de coût. MosaicML permet à l'entreprise de former ses modèles plus rapidement, de manière plus efficace et plus précise, grâce à l'utilisation de l'apprentissage automatique distribué.
 Director of ML, Large Financial Enterprise
Director of ML, Large Financial Enterprise- Multiples fournisseurs de cloud. Mosaic nous permet de tirer parti des GPU de différents fournisseurs de cloud sans la charge de la configuration d'un compte et de toutes les intégrations nécessaires.
- Configurations d'entraînement LLM. La bibliothèque Composer comprend un certain nombre de configurations bien ajustées pour l'entraînement de divers modèles et pour différents types d'objectifs d'entraînement.
- Infrastructure gérée. Leur infrastructure gérée nous offre des services d'orchestration, des optimisations d'efficacité et une tolérance aux pannes (c'est-à-dire la reprise après des défaillances de nœuds).
Le groupe en question prend en compte plusieurs compromis pour déterminer les paramètres de son modèle tels que la taille du modèle, la fenêtre de contexte, le temps d'inférence et l'empreinte mémoire. Les modèles plus grands auraient de meilleures performances et seraient plus propices à l'apprentissage par transfert. Ce group reconnaît cependant que ces modèles ont des exigences informatiques plus élevées pour l'entraînement et l'inférence. Le temps d'inférence est particulièrement crucial pour eux, étant donné que Replit est un EDI natif dans le cloud avec des performances similaires à une application de bureau. Pour cette raison, ils privilégient des modèles plus petits avec une empreinte mémoire réduite et une inférence à faible latence.
Les praticiens peuvent choisir parmi une variété d'objectifs d'entraînement pour leurs modèles de langage. L'objectif de prédiction du prochain token est couramment utilisé pour la saisie semi-automatique du code, bien que cette approche ne prenne pas en compte le contexte en aval d'un document. Pour résoudre ce problème, une approche "fill-in-the-middle" peut être utilisée, dans laquelle une séquence de tokens est cachée et le modèle doit les prédire en utilisant le contexte environnant. Une autre approche est UL2 (Unsupervised Latent Language Learning), qui vise à récupérer les sous-séquences manquantes d'une entrée donnée en utilisant différentes fonctions d'objectif pour l'entraînement des modèles de langage, telles que des tâches de débruitage.
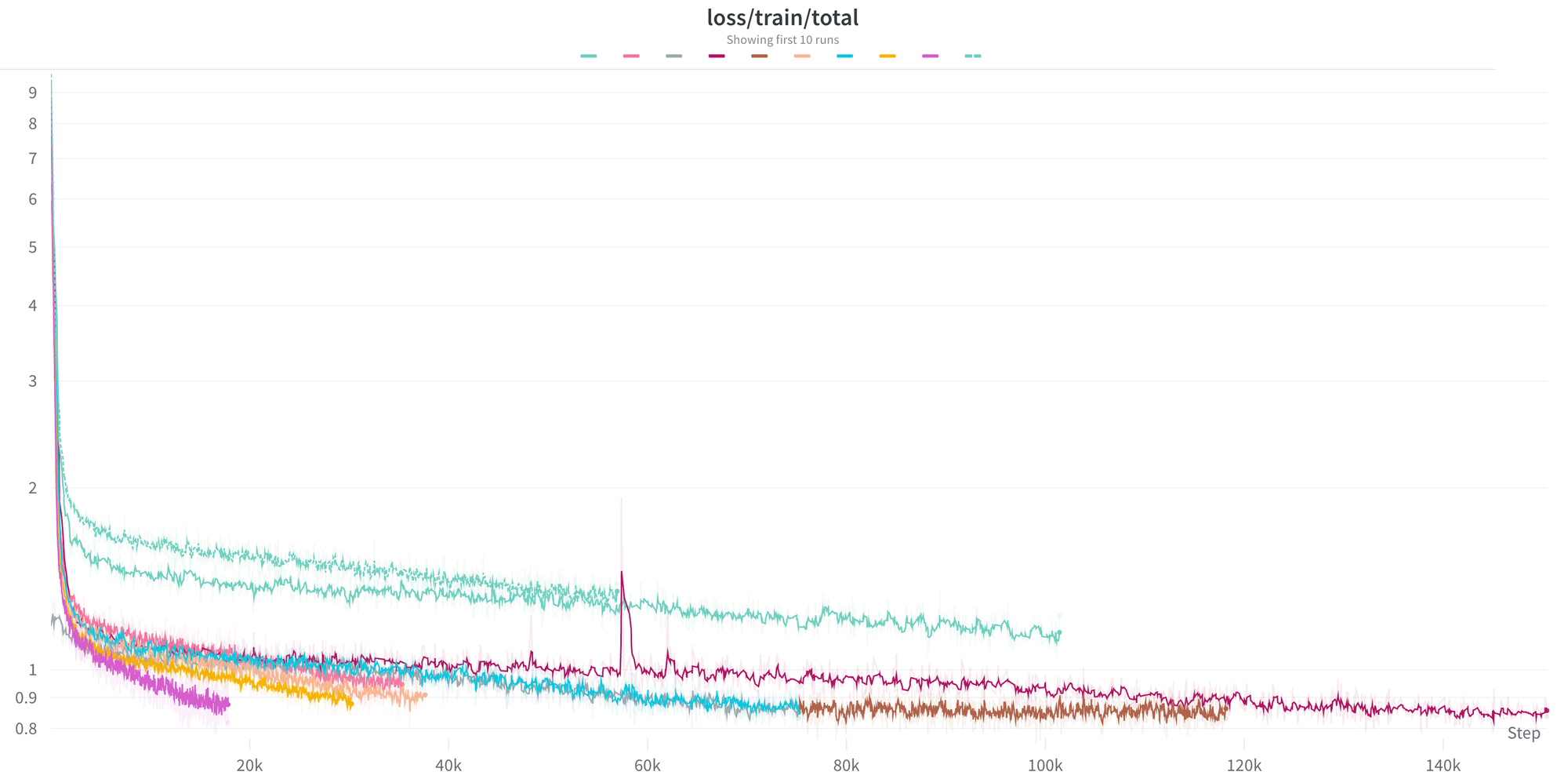
Après avoir défini la configuration de leur modèle et les objectifs d'entraînement, ces professionnels lancent des séries d'entraînement sur des clusters multi-nœuds de GPU. Ils sont capables d'adapter le nombre de nœuds pour chaque série en fonction de la taille du modèle qu'ils entraînent et de leur souhait de terminer rapidement le processus d'entraînement. Les GPU sont coûteux, il est donc important qu'ils les utilisent de la manière la plus efficace possible. Ils surveillent de près l'utilisation des GPU et de la mémoire pour s'assurer qu'ils obtiennent le meilleur rendement possible de leurs ressources informatiques.
L'équipe utilise Weights & Biases pour surveiller leur processus d'entraînement de modèles de langage. Ils vérifient régulièrement les courbes de perte pour s'assurer que le modèle apprend rapidement et efficacement. Les pics de perte sont également surveillés pour détecter les problèmes sous-jacents dans les données d'entraînement ou l'architecture du modèle. Pour permettre une résolution rapide de ces problèmes, ils ont implémenté un processus de détermination des données qui leur permet de reproduire, diagnostiquer et résoudre plus facilement la source de ces pics de perte.
Évaluation
Pour tester leurs modèles de génération de code, les développeurs utilisent une variante du cadre HumanEval décrit par Chen et al. (2021). Ils génèrent un bloc de code Python en utilisant le modèle, à partir d'une signature de fonction et d'une docstring. Ensuite, ils exécutent un cas de test sur la fonction produite pour vérifier si le bloc de code généré fonctionne correctement. Leur technique de test a pour but de réduire et de mesurer les erreurs de génération de code et de déterminer l'efficacité de leurs modèles.
L'entreprise Replit reconnaît que leur approche de génération automatique de code fonctionne mieux pour le langage de programmation Python, grâce aux évaluateurs préexistants pour ce langage et aux cas de test. Toutefois, comme leur plateforme supporte de nombreux autres langages, l'entreprise cherche à évaluer les performances de leur modèle pour un large éventail de langages. Replit a constaté que cela est difficile à réaliser et qu'il n'existe aucun outil ou cadre largement adopté offrant une solution entièrement complète. Deux défis spécifiques incluent l'invention d'un environnement d'exécution reproductible pour n'importe quel langage de programmation et l'ambiguïté des langages de programmation sans normes largement utilisées pour les cas de test (par exemple, HTML, CSS, etc.). Cependant, Replit est spécialisé dans le développement d'un "environnement d'exécution reproductible pour n'importe quel langage de programmation" et est actuellement en train de construire un cadre d'évaluation qui permettra à tout chercheur de se connecter et de tester les références multilingues. Cette nouvelle sera présentée dans un futur article de blog de l'entreprise.
Déploiement en production
Pour déployer leurs modèles de complétion de code en production, l'équipe utilise notamment NVIDIA's FasterTransformer et Triton Server. FasterTransformer est une bibliothèque qui optimise l'inférence de réseaux de neurones basés sur les transformateurs, tandis que Triton offre un serveur d'inférence stable et rapide. Cette combinaison permet à l'équipe d'obtenir une couche de haute performance entre le modèle de transformateur et le matériel GPU, ce qui se traduit par une inférence rapide et distribuée de grands modèles.
Lors du déploiement d'un modèle en production, la dimension est un aspect crucial, ce qui peut être réalisé en utilisant l'infrastructure Kubernetes. Cependant, héberger un serveur d'inférence présente des défis uniques. Les poids de modèle sont souvent volumineux et des exigences spécifiques en matière de matériel, tels que les différentes tailles et quantités de GPU, sont nécessaires. Pour surmonter ces défis, il convient de concevoir le déploiement et les configurations de clustering de manière à fournir rapidement et de manière fiable les ressources demandées. Dans cet objectif, la configuration des clusters doit prendre en compte la pénurie de GPU dans certaines zones et rechercher les nœuds disponibles les moins chers pour l'efficacité économique.
Le processus de test des modèles avant leur déploiement en production est crucial pour garantir leur efficacité. Chez Replit, ils utilisent une approche qui consiste à tester eux-mêmes le modèle pour avoir une idée de ses performances, notamment en termes de latence, de cohérence des suggestions et d'utilité en général. Bien que les résultats du test HumanEval soient également utiles, rien ne vaut le fait de travailler avec un modèle pour avoir une idée de son fonctionnement. Une fois que le modèle est validé en interne, il est facile de le mettre à disposition pour le reste des utilisateurs de Replit en appuyant simplement sur un bouton.
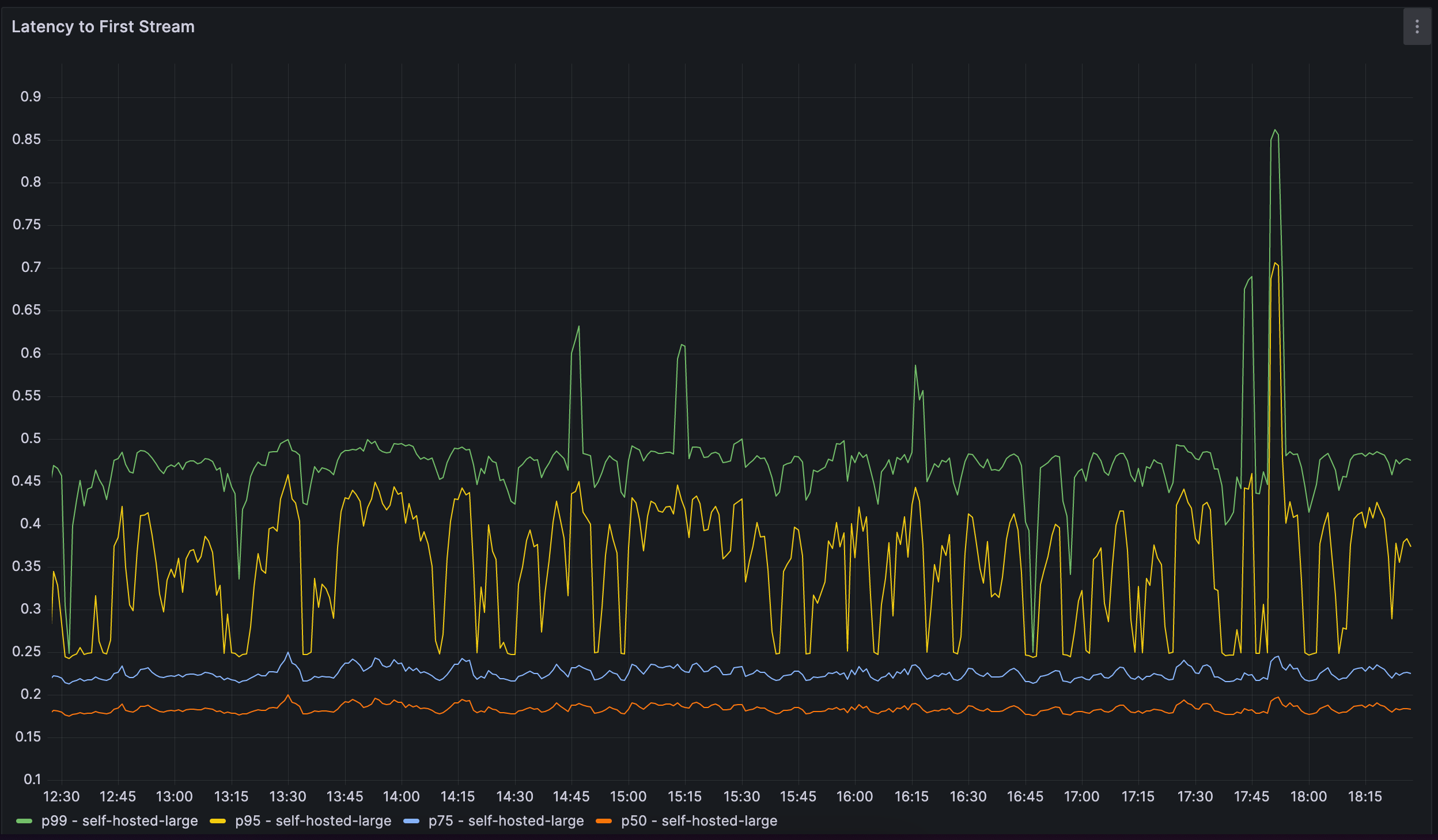
Les développeurs de Replit suivent de près les performances de leur modèle ainsi que les mesures d'utilisation. Ils surveillent la latence des requêtes et l'utilisation du GPU pour évaluer la performance du modèle. Ils suivent également le taux d'acceptation des suggestions de code et le décomposent en plusieurs sections, y compris le langage de programmation. En effectuant des tests A/B sur différents modèles, ils sont en mesure d'obtenir une mesure quantitative pour comparer la performance des modèles.
Rétroaction et itération
Leur plateforme de formation de modèles permet de former et déployer des modèles à partir de données brutes en moins d'une journée. Ils peuvent récolter des commentaires et itérer rapidement sur la base de ces commentaires.
Il est important que leur processus reste robuste face à toute modification des sources de données sous-jacentes, des objectifs de formation des modèles ou de l'architecture des serveurs, pour être à jour sur les nouvelles avancées et capacités dans un domaine en constante évolution.
Ils prévoient d'étendre leur plateforme pour utiliser Replit afin d'améliorer leurs modèles, avec des techniques telles que l'apprentissage par renforcement basé sur la rétroaction humaine (RLHF) et l'ajustement des instructions à l'aide des données collectées lors des enchères Replit.
Prochaines étapes
Bien que des progrès significatifs aient été réalisés, les premières étapes de la formation de modèles de langue sont encore en cours. Les problèmes à résoudre sont nombreux et nécessitent des améliorations considérables. À mesure que la technologie des modèles linguistiques progresse, les défis liés aux données, aux algorithmes et à l'évaluation continueront à augmenter.
Si vous êtes passionné par les défis techniques de la formation de modèles de langue, une discussion avec des experts du domaine pourrait s'avérer intéressante. Les opinions et les retours d'expérience sont toujours les bienvenus pour déterminer les domaines d'amélioration.



