

Comment installer Llama CPP (Meta) en local sur un Mac (Apple Silicon M1)

Avec l'intérêt croissant pour l'intelligence artificielle et son utilisation dans la vie quotidienne, de nombreux modèles exemplaires tels que LLaMA de Meta, GPT-3 d'OpenAI et Kosmos-1 de Microsoft rejoignent le groupe des grands modèles de langage (LLM). Le seul problème de ces modèles est qu'ils ne peuvent pas être exécutés localement. Jusqu'à présent. Grâce à Georgi Gerganov et à son projet llama.cpp, il est possible d'exécuter LLaMA de Meta sur un seul ordinateur sans GPU dédié.

Le 3 mars, l'utilisateur 'llamanon' a divulgué le modèle LLaMA de Meta sur le forum technologique /g/ de 4chan, permettant ainsi à n'importe qui de le télécharger. Un troll a tenté d'ajouter le lien torrent au repo officiel LLaMA Github de Meta.
Comment installer Llama CPP
Installer les dépendances
Voici comment installer LLaMA sur un Mac avec Apple Silicon M1. Ouvrez votre Terminal et entrez ces commandes une par une :
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
makeDans ce tutoriel, nous ne téléchargerons que le modèle 7B, il s'agit du modèle le plus léger. vous pouvez utiliser le logiciel Transmission pour le télécharger.
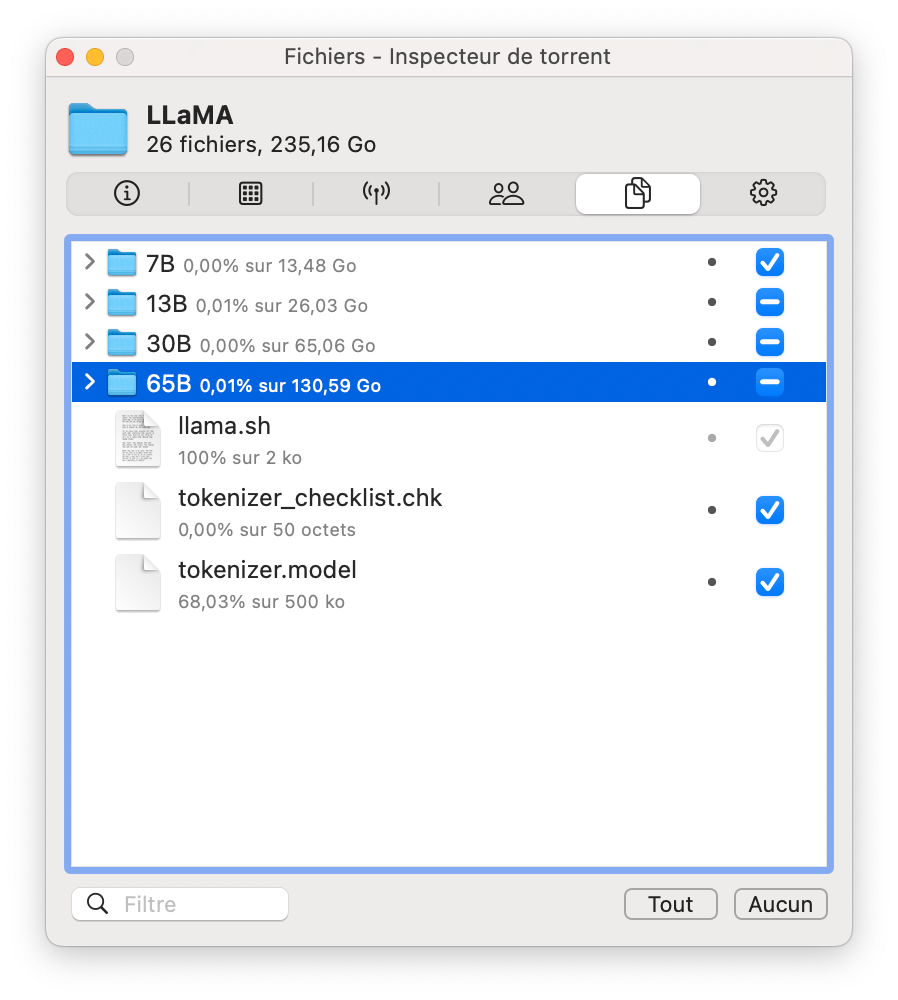
Dans le dossier models de llama.cpp, vous devez avoir la structure de fichier suivante :
13B
30B
65B
7B
llama.sh
tokenizer.model
tokenizer_checklist.chk- Xcode doit être installé pour compiler le projet C++. Si vous ne l'avez pas, veuillez procéder comme suit dans votre terminal :
xcode-select --install- Si Homebrew n'est pas installé, toujours dans l'app Terminal sur votre mac, entrez
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"- Gardez la fenêtre du terminal ouverte et suivez les instructions sous "Next steps" pour ajouter Homebrew à votre PATH.
- Ensuite nous installons Python 3.10 :
brew install python@3.10- Une fois Homebrew installé, vous pouvez l'utiliser pour installer Pipenv en exécutant la commande suivante dans le Terminal :
brew install pipenv- Puis on lance avec :
pipenv shell --python 3.10
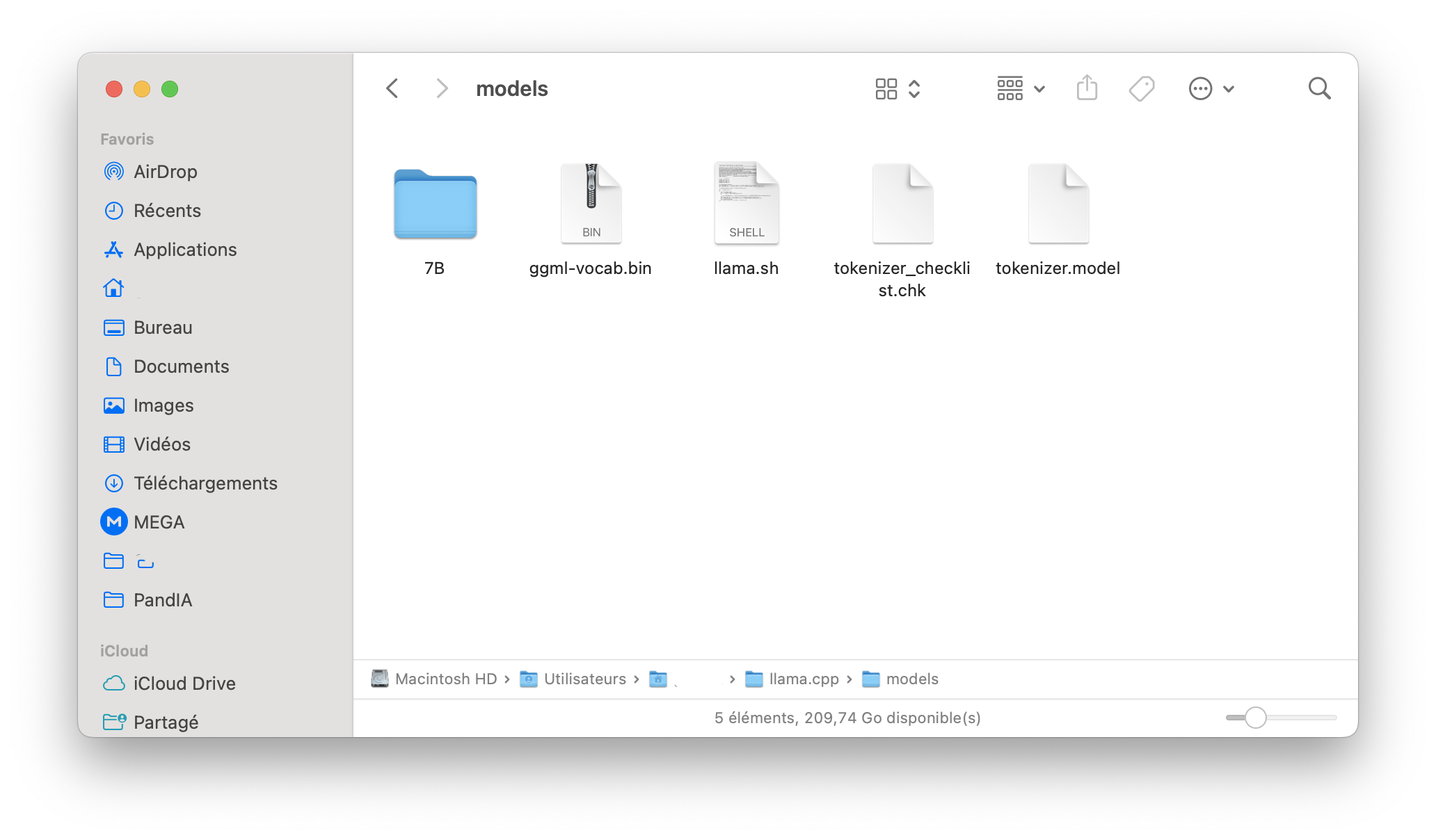
Importer les modèles
Vous devez créer un dossier /models dans votre répertoire llama.cpp qui contient directement le 7B (ou d'autres modèles) et les fichiers du téléchargement du modèle LLaMA.
Convertir les modèles
- Ensuite, installez les dépendances nécessaires au script de conversion Python :
pip install torch numpy sentencepiece- Le premier script convertit le modèle au format "ggml FP16" :
python convert-pth-to-ggml.py models/7B/ 1- Cela devrait produire
models/7B/ggml-model-f16.bin- un autre fichier de 13 Go. Le second script "quantifie le modèle à 4 bits" : ./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin 2- Cela produit
models/7B/ggml-model-q4_0.bin- un fichier de 3,9 Go. C'est le fichier que nous utiliserons pour exécuter le modèle.
Utiliser Llama CPP
Maintenant que tout est prêt, nous pouvons exécuter le modèle :
./main -m ./models/7B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p 'Bitcoin is a cryptocurrency './main --help affiche les options. -m est le modèle. -t est le nombre de threads à utiliser. -n est le nombre de jetons à générer. -p est le prompt. Pour obtenir des réponses plus longues il faudra augmenter -n, par exemple -n 512.
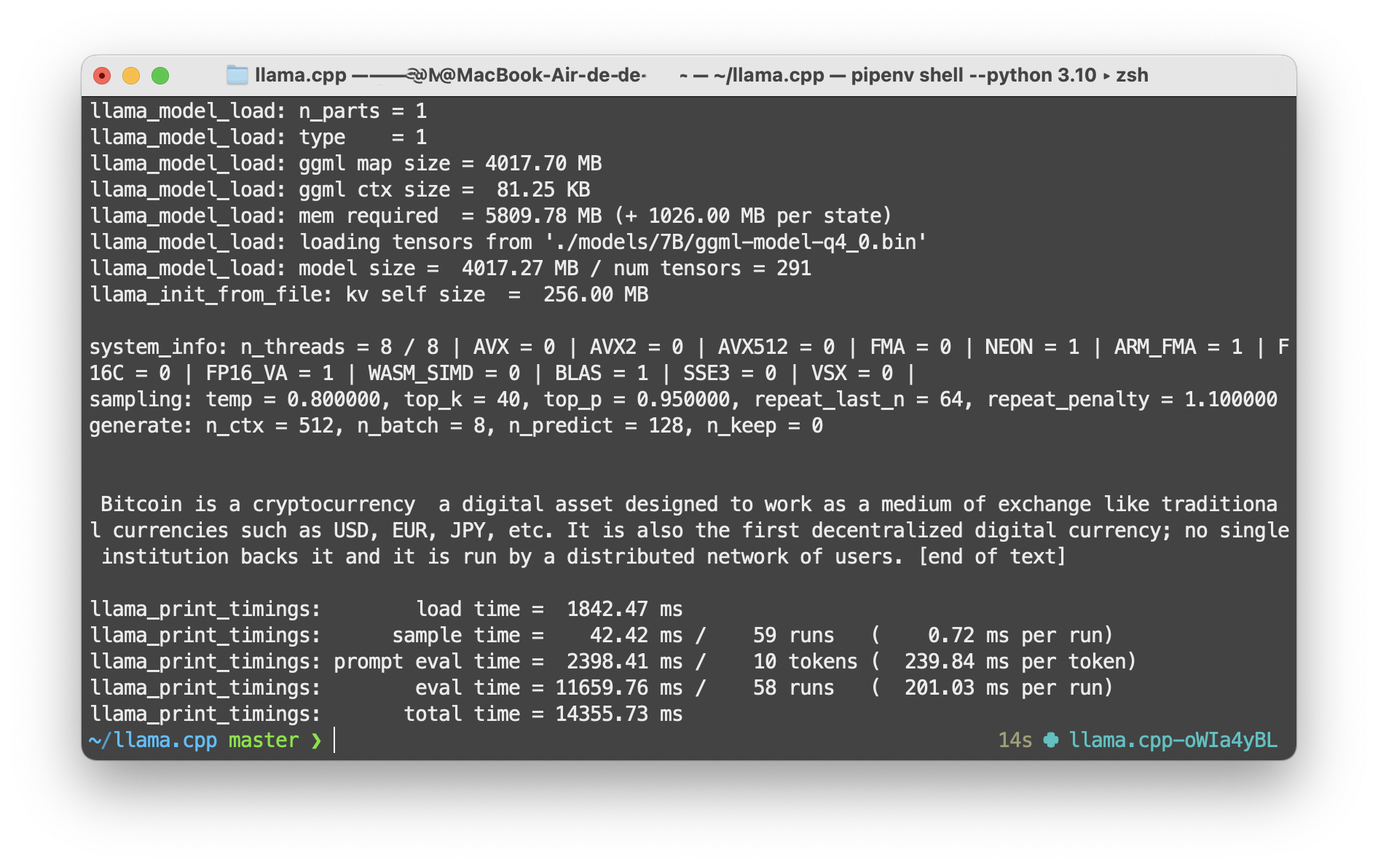
Réponse de Llama CPP :
Bitcoin is a cryptocurrency, a digital asset designed to work as a medium of exchange like traditional currencies such as USD, EUR, JPY, etc. It is also the first decentralized digital currency; no single institution backs it and it is run by a distributed network of users. [end of text]
Conclusion
Vous pouvez désormais intéragir avec votre propre IA, sur votre Mac sans avoir besoin d'internet. Si vous rencontrez des erreurs durant l'installation de Llama CPP, n'hésitez pas à les copier, et à les coller dans ChatGPT en lui disant : J'obtiens cette erreur dans mon Terminal sur un Mac : [coller l'erreur] il devrait être en mesure de vous apporter la solution.
À voir aussi :




