

Comment les modèles de langage gèrent-ils les contextes longs ?

Introduction
L'intelligence artificielle (IA) a connu des avancées significatives ces dernières années, notamment dans le domaine des modèles de langage. Ces modèles sont essentiels pour comprendre, générer et traduire le texte. Cependant, leur performance peut varier en fonction du contexte d'entrée. Un document récent a examiné comment ces modèles se comportent lorsqu'ils sont confrontés à des contextes longs.

Analyse de la performance
Les auteurs ont analysé la performance des modèles de langage sur des tâches qui nécessitent l'identification d'informations pertinentes dans le contexte d'entrée. Ils ont constaté que la performance est la plus élevée lorsque les informations pertinentes se trouvent au début ou à la fin du contexte. Cependant, la performance diminue de manière significative lorsque les modèles doivent accéder à des informations situées au milieu de contextes longs.
Pour illustrer cela, imaginez un modèle de langage analysant un document de plusieurs pages. Il peut facilement identifier et comprendre les informations présentées au début et à la fin du document. Cependant, si des informations importantes sont cachées au milieu du document, le modèle peut avoir du mal à les identifier et à les comprendre.
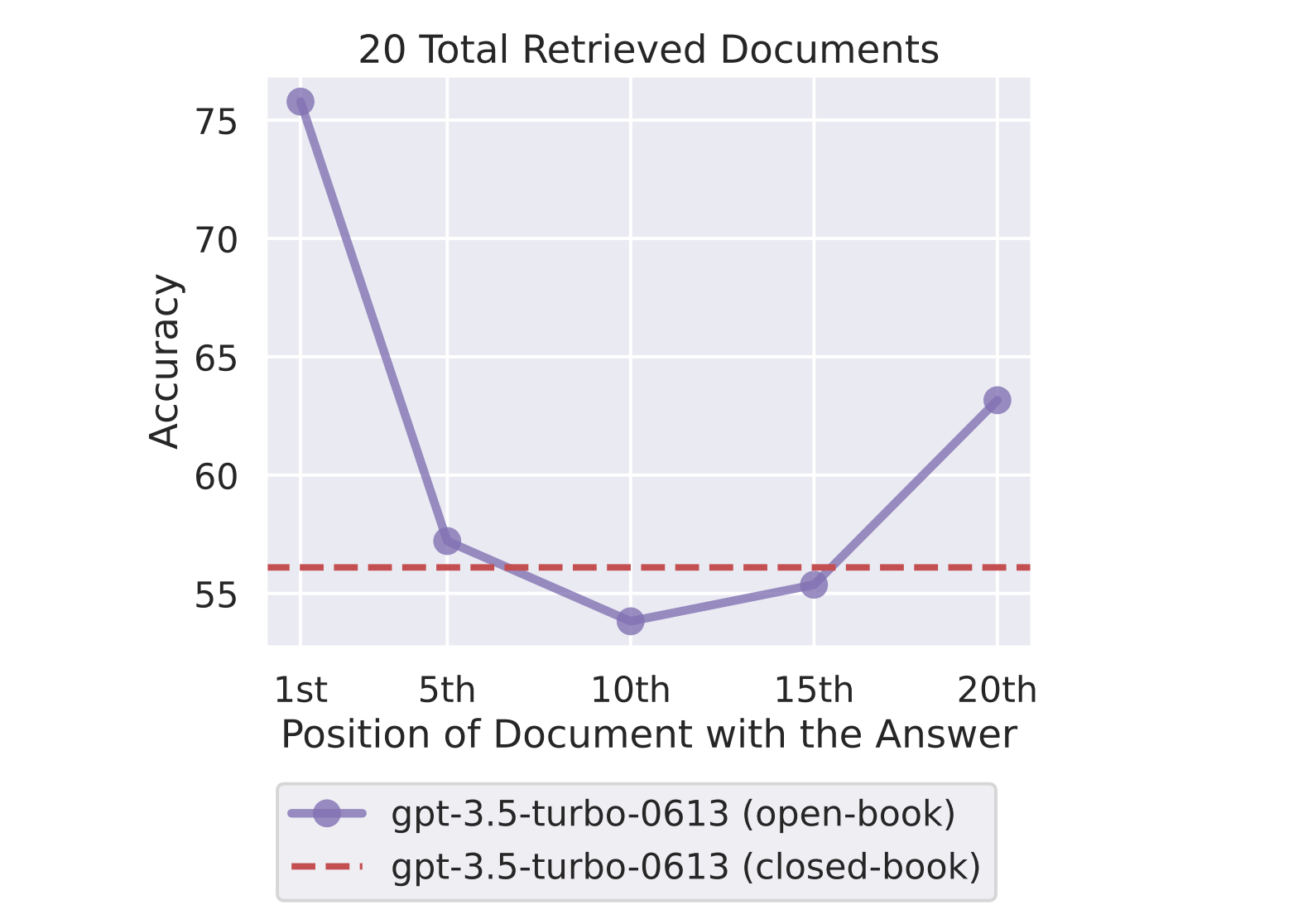
Dégradation de la performance avec l'augmentation du contexte
Une autre observation intéressante est que la performance diminue à mesure que le contexte d'entrée s'allonge, même pour les modèles conçus pour des contextes longs. Cela suggère que la gestion de contextes longs reste un défi pour les modèles de langage actuels.
Par exemple, un modèle de langage conçu pour traiter des textes de 500 mots pourrait ne pas être aussi efficace lorsqu'il est confronté à un texte de 2000 mots. Cela peut être dû à divers facteurs, tels que la difficulté à maintenir une représentation cohérente de l'ensemble du contexte ou à la limitation de la capacité de mémoire du modèle.
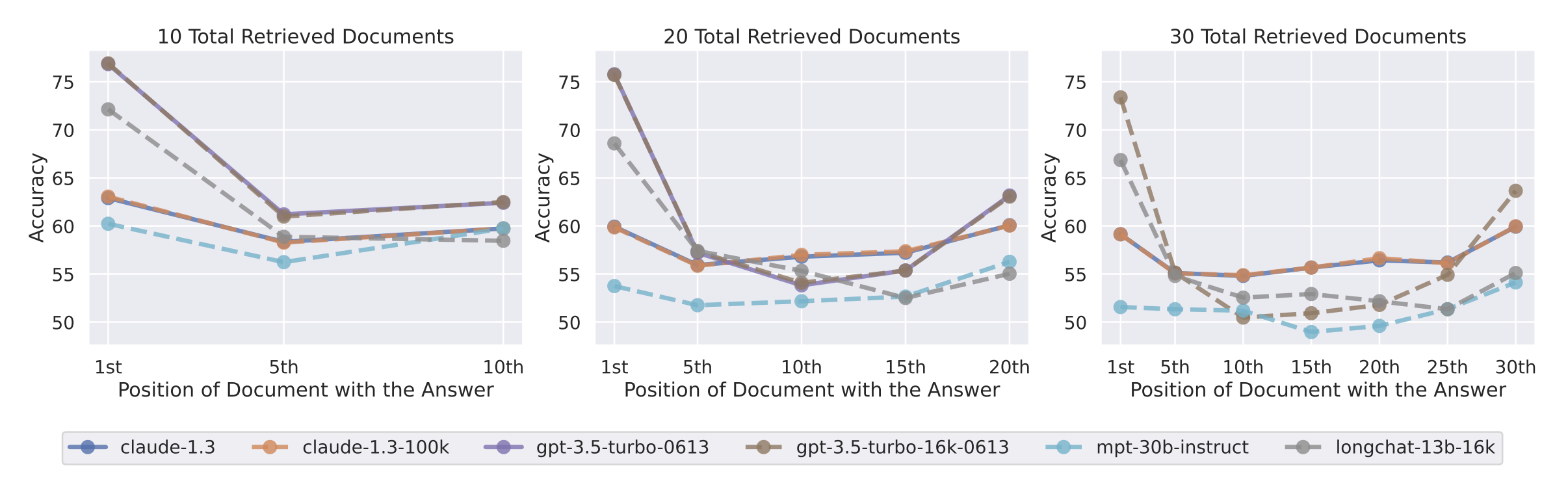
Implications et perspectives futures
Cette analyse offre des perspectives intéressantes sur la manière dont les modèles de langage utilisent leur contexte d'entrée. Elle suggère également de nouveaux protocoles d'évaluation pour les futurs modèles. En comprenant mieux ces limites, les chercheurs peuvent développer de nouvelles méthodes pour améliorer la performance des modèles de langage, en particulier dans le traitement de contextes longs.
Par exemple, les chercheurs pourraient explorer des techniques pour améliorer la capacité des modèles à accéder à des informations situées au milieu de contextes longs. Ils pourraient également développer des méthodes pour minimiser la dégradation de la performance lorsque le contexte d'entrée s'allonge.
Conclusion
En conclusion, bien que les modèles de langage aient fait d'énormes progrès, il reste encore des défis à relever. La compréhension et l'amélioration de la performance dans des contextes longs est l'un de ces défis. Les recherches futures dans ce domaine sont donc essentielles pour continuer à faire progresser le domaine de l'intelligence artificielle.
Si vous souhaitez approfondir le sujet, vous pouvez consulter le document original ici.



