

Comment utiliser LangChain pour créer votre première application d'IA en Python

Ce guide a pour objectif de présenter de manière simple et accessible les composants et les cas d'utilisation de LangChain, à travers des exemples ELI5 (Expliquer comme si j'avais cinq ans) et des extraits de code. Même si vous n'êtes pas développeur, vous pouvez suivre ce guide et créer votre propre bot en utilisant l'API d'OpenAI et LangChain. Nous allons mettre en place des cas concrets utilisant LangChain et l'API d'OpenAI pour apprendre à l'utiliser.
Qu'est-ce que LangChain ?
LangChain est un cadre pour le développement d'applications basées sur des modèles de langage. Si vous souhaitez en apprendre plus sur LangChain avant de vous lancer :

TLDR : LangChain simplifie les aspects complexes du travail et de la construction avec des modèles d'IA. Il y contribue de deux manières :
- Intégration - Apportez des données externes, telles que vos fichiers, d'autres applications et des données d'API, à vos LLM.
- Agents - Permettez à vos LLM d'interagir avec leur environnement par le biais de la prise de décision. Utilisez les LLM pour vous aider à décider de la prochaine action à entreprendre.
Pourquoi LangChain ?
- Composants 🦜 - LangChain facilite l'échange des abstractions et des composants nécessaires pour travailler avec des modèles de langage.
- Chaînes personnalisées 🔗 - LangChain permet d'utiliser et de personnaliser des "chaînes", c'est-à-dire une série d'actions enchaînées les unes aux autres.
- Rapidité 🚢 - Cette équipe travaille à une vitesse folle. Vous serez au courant des dernières fonctionnalités de LLM.
- Communauté 👥 - Merveilleux discord et soutien de la communauté, rencontres, hackathons, etc.
Bien que les LLMs puissent être simples (text-in, text-out), vous rencontrerez rapidement des points de friction que LangChain vous aidera à résoudre lorsque vous développerez des applications plus compliquées.
Note : Ce guide ne couvre pas tous les aspects de LangChain. Son contenu a été conçu pour vous permettre de construire et d'avoir un résultat aussi rapidement que possible. Pour plus d'informations, veuillez consulter la documentation conceptuelle de LangChain.
Création de l'environnement
Replit est une plateforme de développement en ligne qui permet de créer, exécuter et partager des projets de programmation dans différents langages, directement depuis votre navigateur web. Nous ne voulons pas perdre du temps à configurer un serveur en local, nous allons utiliser Replit qui va nous permettre d'héberger notre bot et d'éditer notre code. Rendez-vous sur leur site et créer un compte.
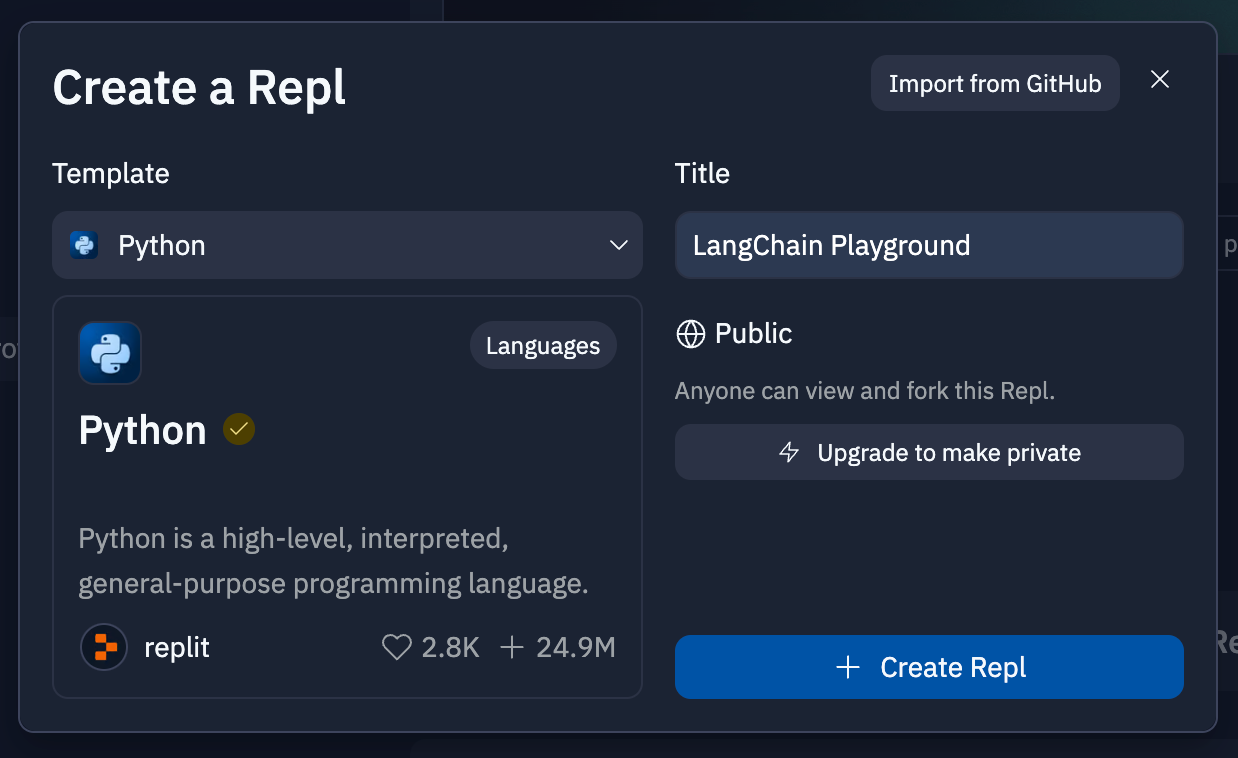
Une fois votre compte créé, cliquez en haut à gauche sur Create Repl, nous allons utiliser la version Python de LangChain, mais sachez qu'il est possible de le faire en JavaScript égallement. Dans Template recherchez le template Python, puis donnez un nom à votre Repl, et cliquez sur Create Repl
Configuration de l'environnement
Notez que vous aurez besoin d'une clé API de OpenAI, et de quelques crédits dans votre compte. Le coût d'une requête est de 0,2 cent pour ~4000 caractères de texte. Vous pouvez obtenir des crédits d'une valeur de 18 $ lorsque vous vous inscrivez et ceux-ci devraient durer un certain temps, mais il n'y a actuellement pas de version entièrement gratuite de l'API.
Ajout de la clé API
Allez sur OpenAI et cliquez sur 'Créer une nouvelle clé secrète' pour en avoir une. Attention la clé ne pourra pas être affichée une deuxième fois.
Maintenant retournons sur Replit. Nous allons devoir ajouter notre Clé API dans notre environnement. Pour cela cliquez en bas à gauche sur Secrets, un onglet va s'ouvrir à droite de l'écran. Ajoutez un secret portant le nom de openai_api_key (dans key), puis collez votre clé dans value.
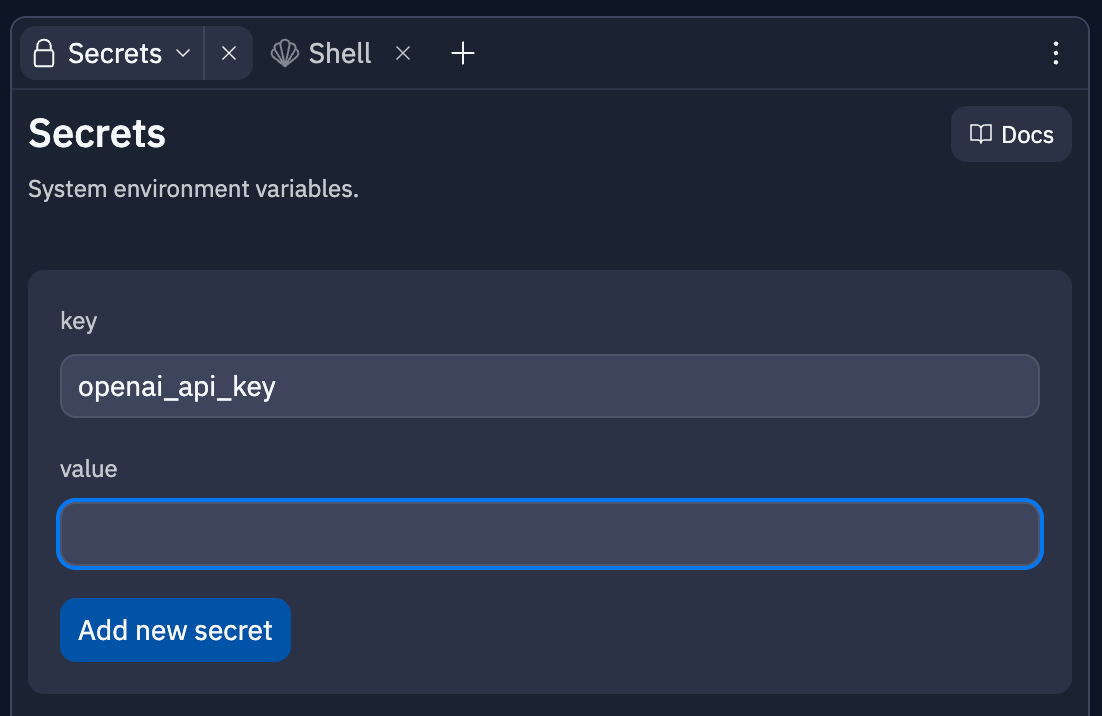
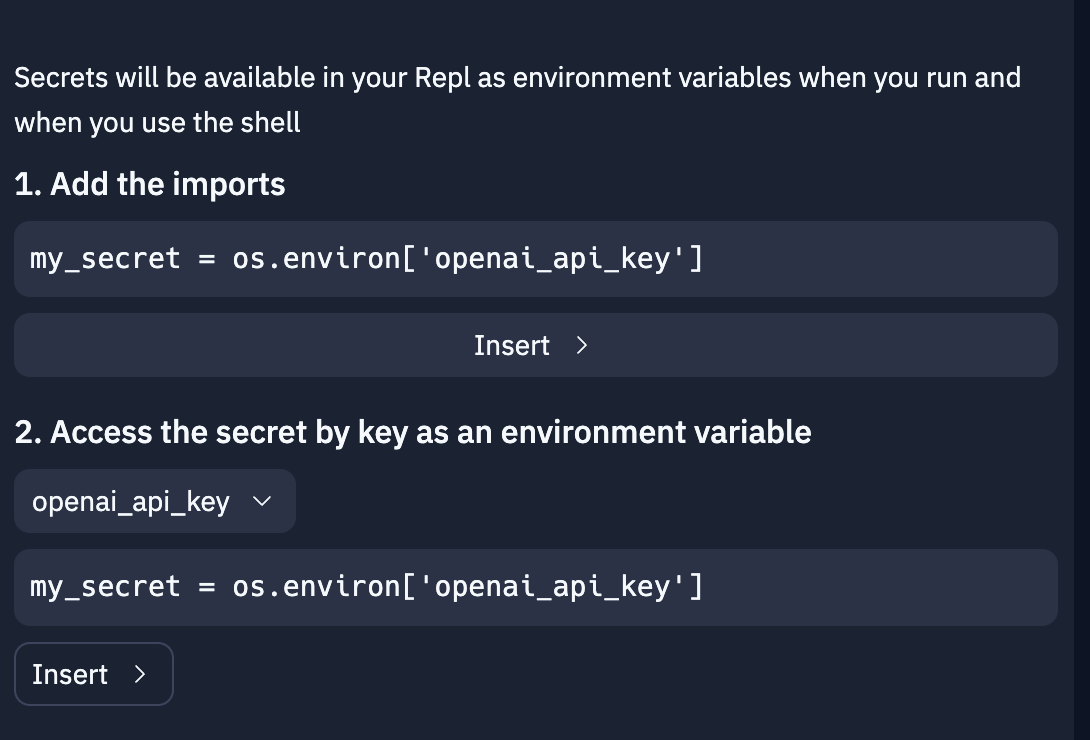
En ajoutant votre clé, du texte devrait s'afficher en dessous. Cliquez sur le premier bouton Insert. Il devrait alors écrire import os dans votre code. Cette ligne permet à votre code de venir lire vos Secrets, sans les révéler publiquement.
Installer les dépendances
Nous allons ensuite installer les dépendances nécessaires pour notre futur code. La première est LangChain. En bas à gauche cliquez sur Shell, une fenêtre va s'ouvrir. Dans cette fenêtre, entrez pip install langchain et validez. LangChain va s'installer, attendez la fin du chargement.
Si Replit n'installe pas la dernière version vous pouvez le faire manuellement avec pip install --upgrade langchain ou encore pip install langchain==0.0.136, remplacez 0.0.136 avec la dernière version disponible ici sur le GitHub de LangChain.
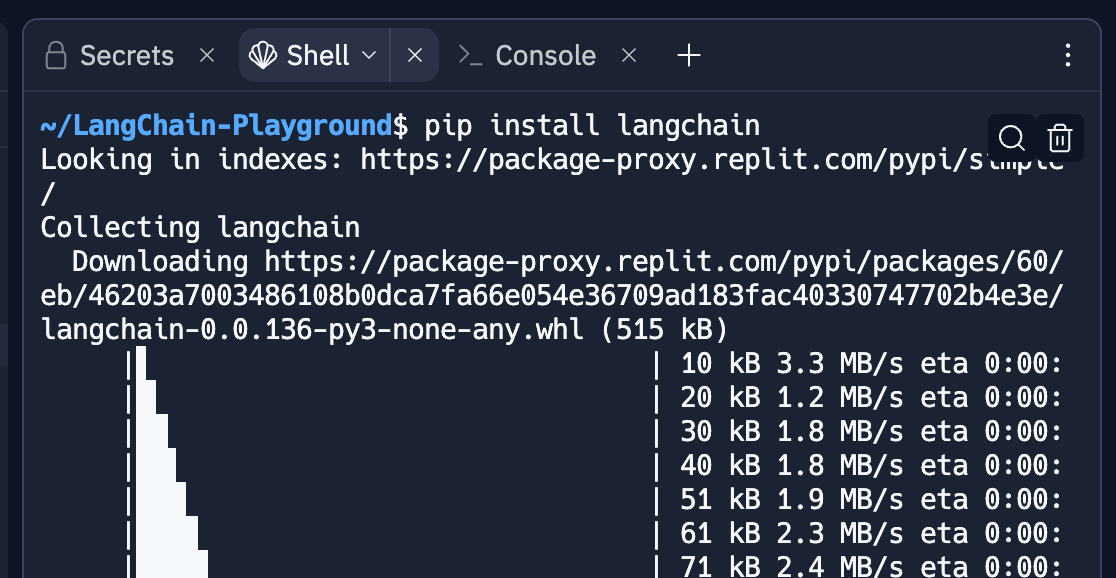
Toujours dans Shell, installez OpenAI avec pip install openai et validez.
Composants de LangChain
Schéma - Les rouages du travail avec les LLM
Texte
La façon d'interagir avec les LLM en langage naturel
my_text = "Quel jour vient après vendredi ?"
Messages de chat
Comme du texte, mais spécifié avec un type de message (Système, Humain, IA)
- Système : Contexte d'arrière-plan utile qui indique à l'IA ce qu'elle doit faire.
- Humain : messages destinés à représenter l'utilisateur.
- IA : Messages qui montrent ce que l'IA a répondu.
Premièrement nous allons importer dans notre code les dépendances précédemment installées. Placez ce code avant import os.
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessagePuis nous allons paramétrer notre bot et lui communiquer notre clé API. Placez ce code après import os.
chat = ChatOpenAI(temperature=.7, openai_api_key=os.environ['openai_api_key'])Nous écrivons ce que nous souhaitons demander à notre bot.
response = chat(
[
SystemMessage(content="Vous êtes une gentille IA qui aide l'utilisateur à savoir ce qu'il doit manger en une courte phrase."),
HumanMessage(content="J'aime les tomates, que dois-je manger ?")
]
)Et maintenant la ligne pour que notre bot puisse nous répondre.
print(response)Notez que cette commande écrit l'intégralité de l'objet AIMessage, y compris les métadonnées. Si vous ne souhaitez afficher que le contenu du message de l'IA, vous pouvez remplacer l'instruction print par :
print(response.content)On se retrouve donc avec ce code :
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
import os
chat = ChatOpenAI(temperature=.7, openai_api_key=os.environ['openai_api_key'])
response = chat(
[
SystemMessage(content="Vous êtes une gentille IA qui aide l'utilisateur à savoir ce qu'il doit manger en une courte phrase."),
HumanMessage(content="J'aime les tomates, que dois-je manger ?")
]
)
print(response.content)Cliquez sur Run en haut de la fenêtre. Votre bot va vous répondre dans la Console.
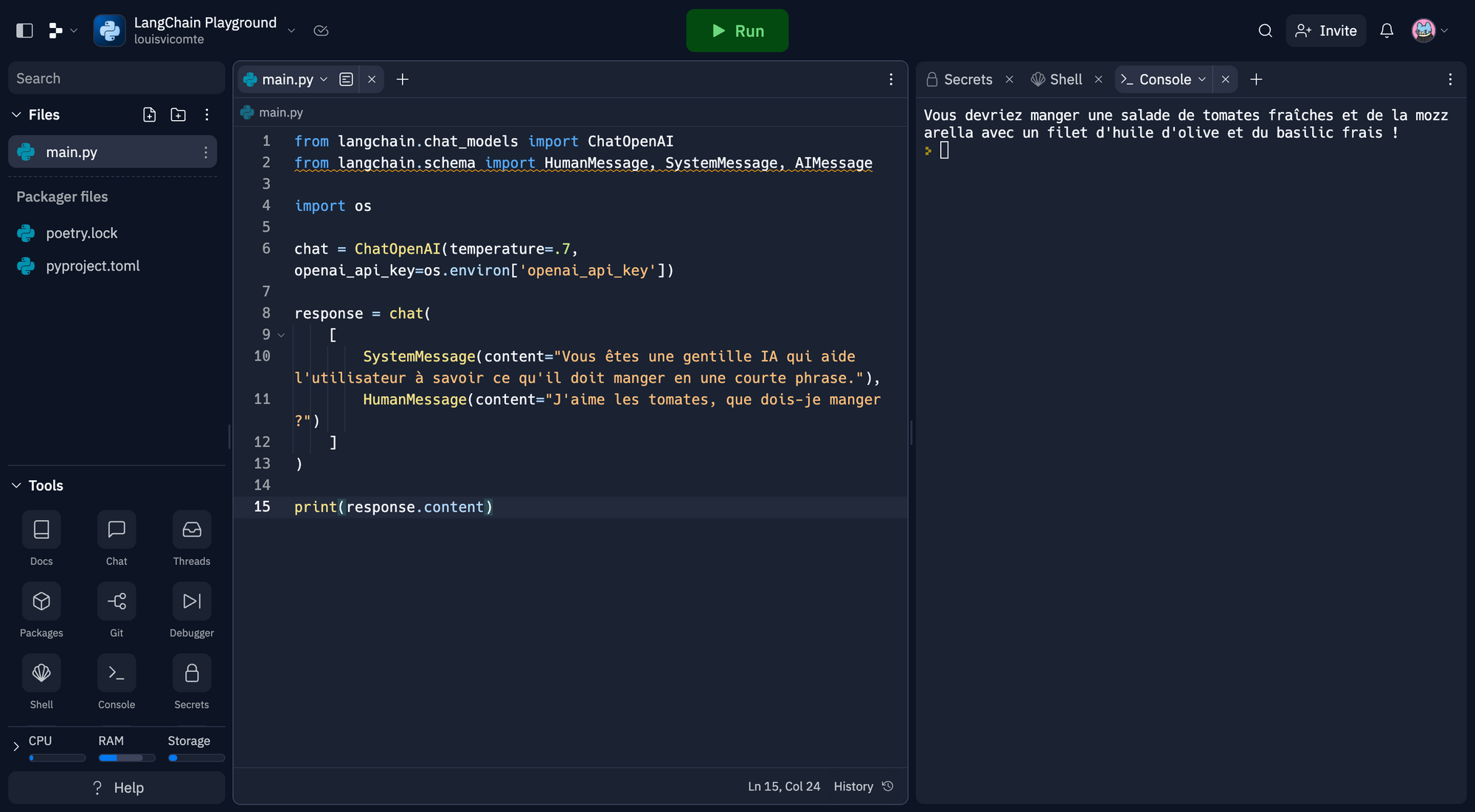
Vous pouvez également transmettre plus d'historique de chat avec les réponses de l'IA.
response = chat(
[
SystemMessage(content="Vous êtes une gentille IA qui aide l'utilisateur à savoir ce qu'il doit manger en une courte phrase."),
HumanMessage(content="J'aime les tomates, que dois-je manger ?"),
AIMessage(content="Vous devriez manger une salade de tomates fraîches et de la mozzarella avec un filet d'huile d'olive et du basilic frais !"),
HumanMessage(content="Je préfère quand c'est chaud, tu as une meilleure idée ?")
]
)Cliquez sur Run de nouveau, le bot prendra en compte l'historique que vous lui communiquez pour vous répondre.

Documents
Objet contenant un morceau de texte et des métadonnées (plus d'informations sur ce texte). Commencez par importer Document au début de votre code.
from langchain.schema import DocumentPuis on remplace chat(... ...}) par :
Document(page_content="This is my document. It is full of text that I've gathered from other places",
metadata={
'my_document_id' : 234234,
'my_document_source' : "The LangChain Papers",
'my_document_create_time' : 1680013019
})Et aussi :
print(response.content)Par :
print(response)Nous avons donc ce code :
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
from langchain.schema import Document
import os
chat = ChatOpenAI(temperature=.7, openai_api_key=os.environ['openai_api_key'])
response = Document(page_content="Voici mon document. Il est rempli de textes que j'ai recueillis à divers endroits",
metadata={
'my_document_id' : 234234,
'my_document_source' : "The LangChain Papers",
'my_document_create_time' : 1680013019
})
print(response)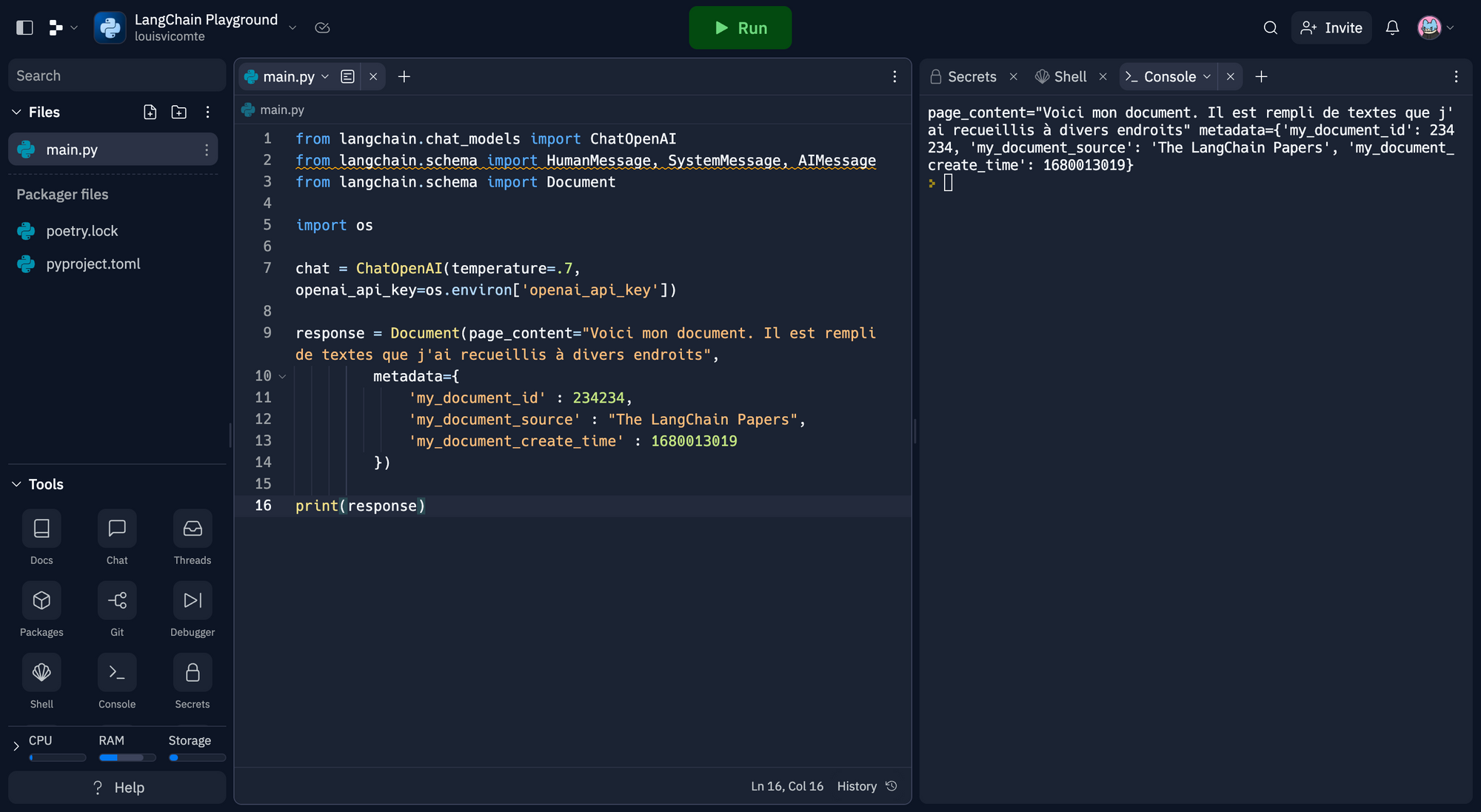
Modèles - L'interface avec les cerveaux de l'IA
Modèle linguistique
Un modèle qui permet de faire : texte d'entrée ➡️ texte de sortie.
Nous pouvons effacer notre ancien code et le remplacer comme ceci :
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", openai_api_key=os.environ['openai_api_key'])Dans l'exemple j'utilise le modèle text-ada-001. Ensuite on ajoute notre texte d'entrée.
response = llm("What day comes after Friday?")Voici le code que vous devriez avoir :
from langchain.llms import OpenAI
import os
llm = OpenAI(model_name="text-ada-001", openai_api_key=os.environ['openai_api_key'])
response = llm("What day comes after Friday?")
print(response)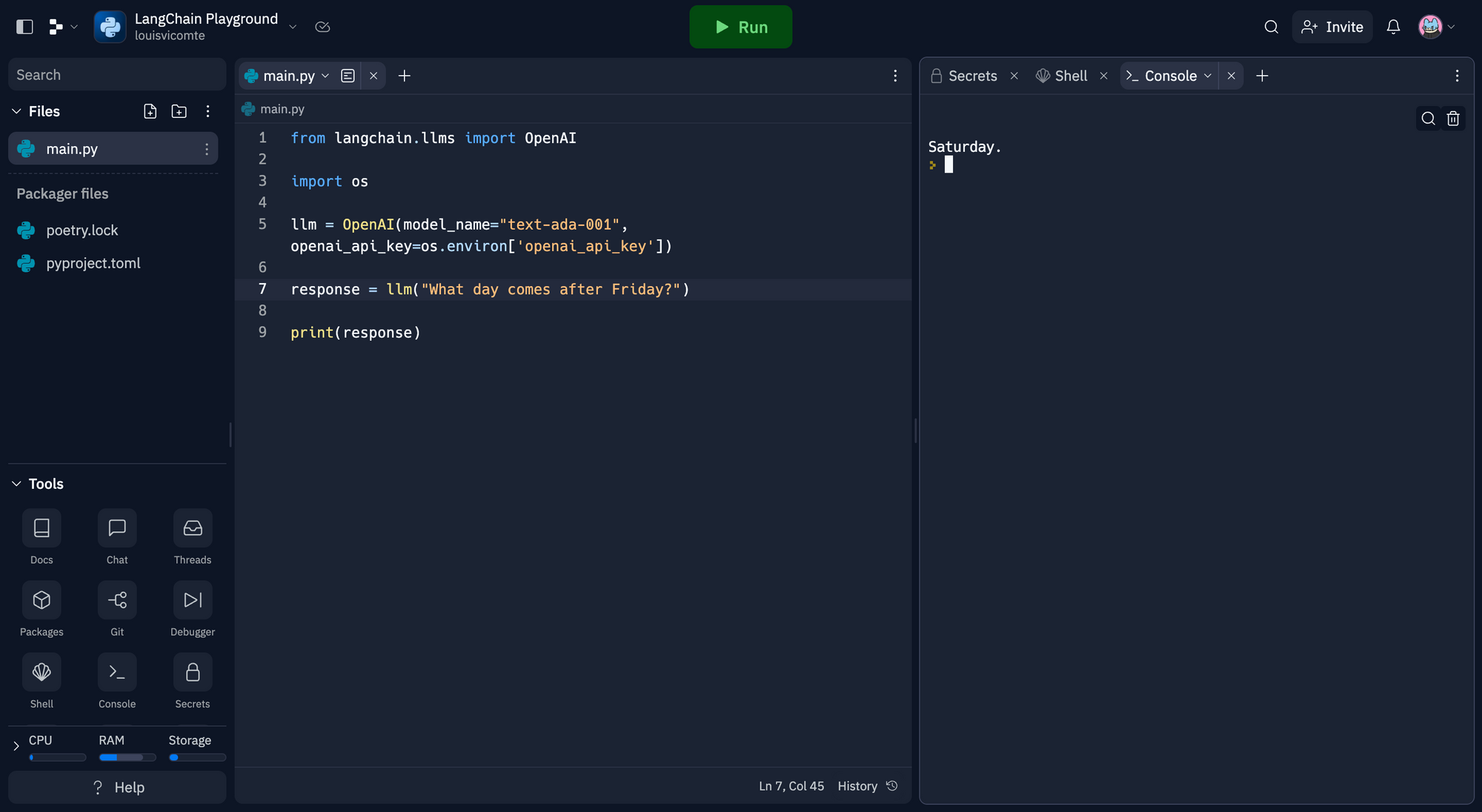
Modèle de conversation
Un modèle qui prend une série de messages et renvoie un message en sortie.
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(temperature=1, openai_api_key=os.environ['openai_api_key'])On donne l'instruction :
chat(
[
SystemMessage(content="Vous êtes un robot d'IA peu utile qui se moque de tout ce que dit l'utilisateur."),
HumanMessage(content="J'aimerais me rendre à Paris, comment dois-je procéder ?")
]
)Code final :
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
import os
chat = ChatOpenAI(temperature=1, openai_api_key=os.environ['openai_api_key'])
response = chat(
[
SystemMessage(content="Vous êtes un robot d'IA peu utile qui se moque de tout ce que dit l'utilisateur."),
HumanMessage(content="J'aimerais me rendre à Paris, comment dois-je procéder ?")
]
)
print(response.content)
Modèle d'intégration de texte
Transformez votre texte en vecteur (une série de nombres qui contiennent le "sens" sémantique de votre texte). Principalement utilisé pour comparer deux morceaux de texte.
Nous allons devoir installer tiktoken pour utiliser ce modèle, dans la fenêtre Shell entrez pip install tiktoken et validez.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['openai_api_key'])text = "Bitcoin: A Peer-to-Peer Electronic Cash System"text_embedding = embeddings.embed_query(text)
print (f"Your embedding is length {len(text_embedding)}")
print (f"Here's a sample: {text_embedding[:5]}...")Et le code final :
from langchain.embeddings import OpenAIEmbeddings
import os
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['openai_api_key'])
text = "Bitcoin: A Peer-to-Peer Electronic Cash System"
text_embedding = embeddings.embed_query(text)
print (f"Your embedding is length {len(text_embedding)}")
print (f"Here's a sample: {text_embedding[:5]}...")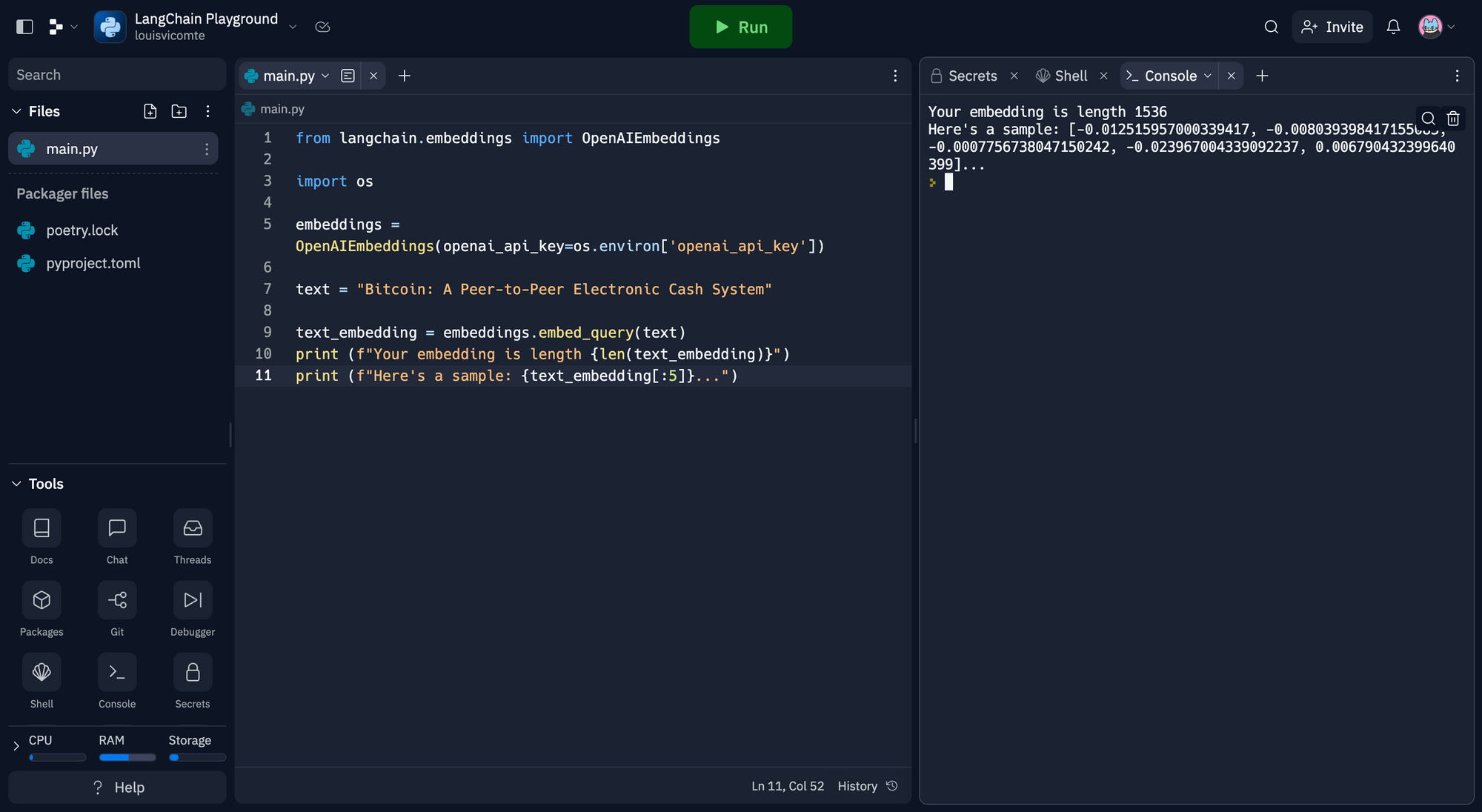
Prompts - Texte généralement utilisé comme instructions pour votre modèle.
Prompt
Ce que vous allez transmettre au modèle sous-jacent.
from langchain.llms import OpenAI
import os
llm = OpenAI(model_name="text-davinci-003", openai_api_key=os.environ['openai_api_key'])
prompt = """
De quelle chanson proviennent ces paroles :
I see a red door and I want it painted black
No colours anymore, I want them to turn black
"""
response = llm(prompt)
print(response)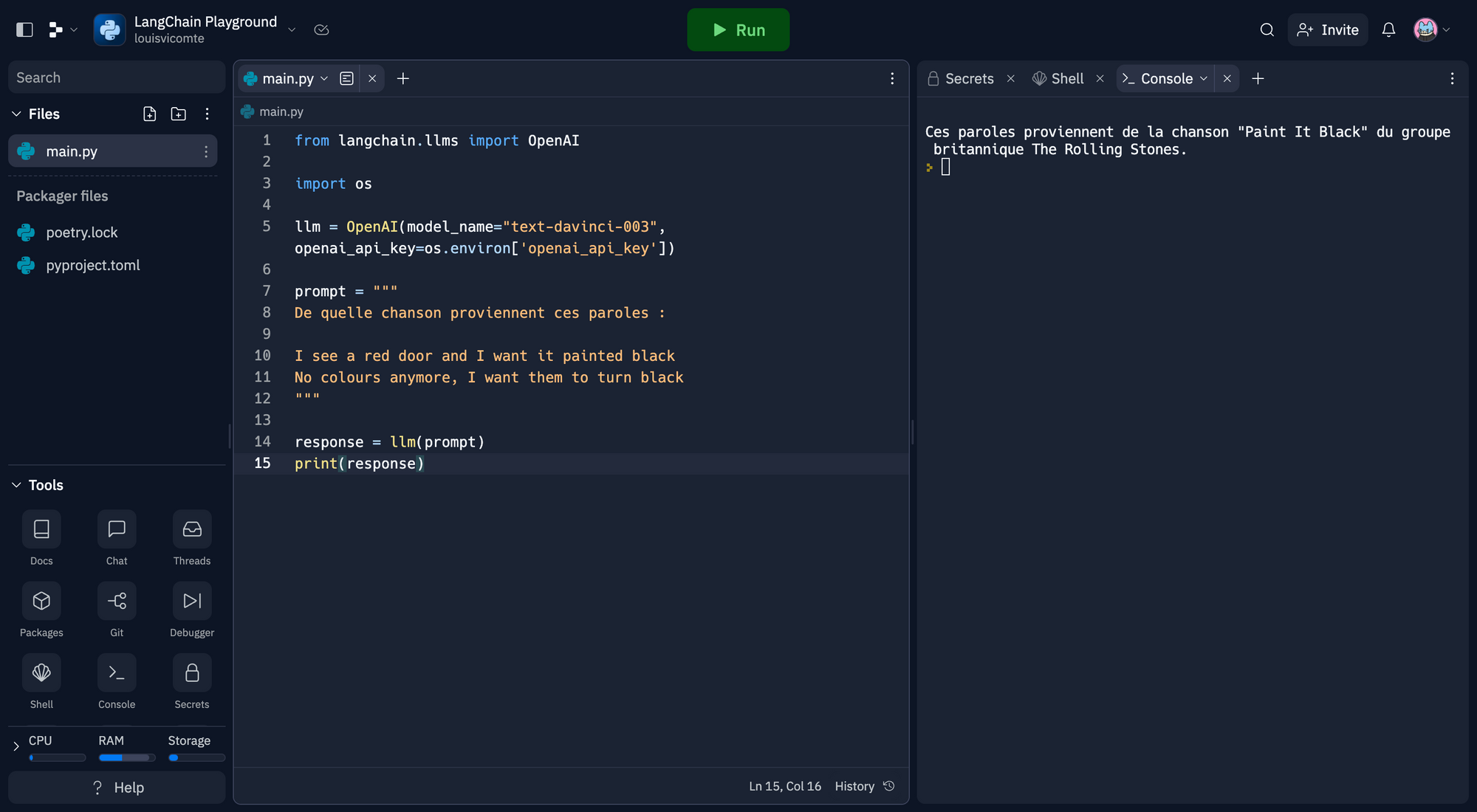
Prompt template
Un objet qui permet de créer des prompts basées sur une combinaison d'entrées utilisateur, d'autres informations non statiques et d'une chaîne de caractères fixe.
Il s'agit en quelque sorte une f-string en python, mais pour les prompts.
from langchain.llms import OpenAI
from langchain import PromptTemplate
import os
llm = OpenAI(model_name="text-davinci-003", openai_api_key=os.environ['openai_api_key'])
# Notice "location" below, that is a placeholder for another value later
template = """
Je souhaite visier {location}. Que puis-je faire sur place ?
Répondre en une phrase courte
"""
prompt = PromptTemplate(
input_variables=["location"],
template=template,
)
final_prompt = prompt.format(location='Tokyo')
print (f"Final Prompt: {final_prompt}")
print ("-----------")
print (f"LLM Output: {llm(final_prompt)}")
Exemples de sélecteurs
Un moyen facile de choisir parmi une série d'exemples qui vous permettent de placer de manière dynamique des informations en contexte dans votre message. Souvent utilisé lorsque votre tâche est nuancée ou que vous disposez d'une longue liste d'exemples.
Nous allons avoir besoin de faiss pour utiliser cette fonction, dans shell écrivez pip install faiss-cpu et validez.
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langchain.llms import OpenAI
import os
llm = OpenAI(model_name="text-davinci-003", openai_api_key=os.environ['openai_api_key'])
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Example Input: {input}\nExample Output: {output}",
)
# Exemples d'endroits où l'on trouve ces noms
examples = [
{"input": "pirate", "output": "ship"},
{"input": "pilot", "output": "plane"},
{"input": "driver", "output": "car"},
{"input": "tree", "output": "ground"},
{"input": "bird", "output": "nest"},
]
# SemanticSimilarityExampleSelector sélectionne les exemples qui sont similaires à vos données en fonction de leur signification sémantique.
example_selector = SemanticSimilarityExampleSelector.from_examples(
# Voici la liste des exemples disponibles.
examples,
# Il s'agit de la classe d'intégration utilisée pour produire des intégrations qui servent à mesurer la similarité sémantique.
OpenAIEmbeddings(openai_api_key=os.environ['openai_api_key']),
# Il s'agit de la classe VectorStore, qui est utilisée pour stocker les encastrements et effectuer une recherche de similarité.
FAISS,
# C'est le nombre d'exemples à produire.
k=2
)
similar_prompt = FewShotPromptTemplate(
# L'objet qui permet de sélectionner les exemples
example_selector=example_selector,
# Votre prompt
example_prompt=example_prompt,
# Personnalisations qui seront ajoutées en haut et en bas du prompt
prefix="Give the location an item is usually found in",
suffix="Input: {noun}\nOutput:",
# Les inputs que votre prompt recevra
input_variables=["noun"],
)
# Sélectionnez un nom !
my_noun = "student"
print(similar_prompt.format(noun=my_noun))
# Créer le prompt
formatted_prompt = similar_prompt.format(noun=my_noun)
# Générer une réponse à l'aide de la fonction llm
response = llm(formatted_prompt)
# Écrire la réponse
print(response)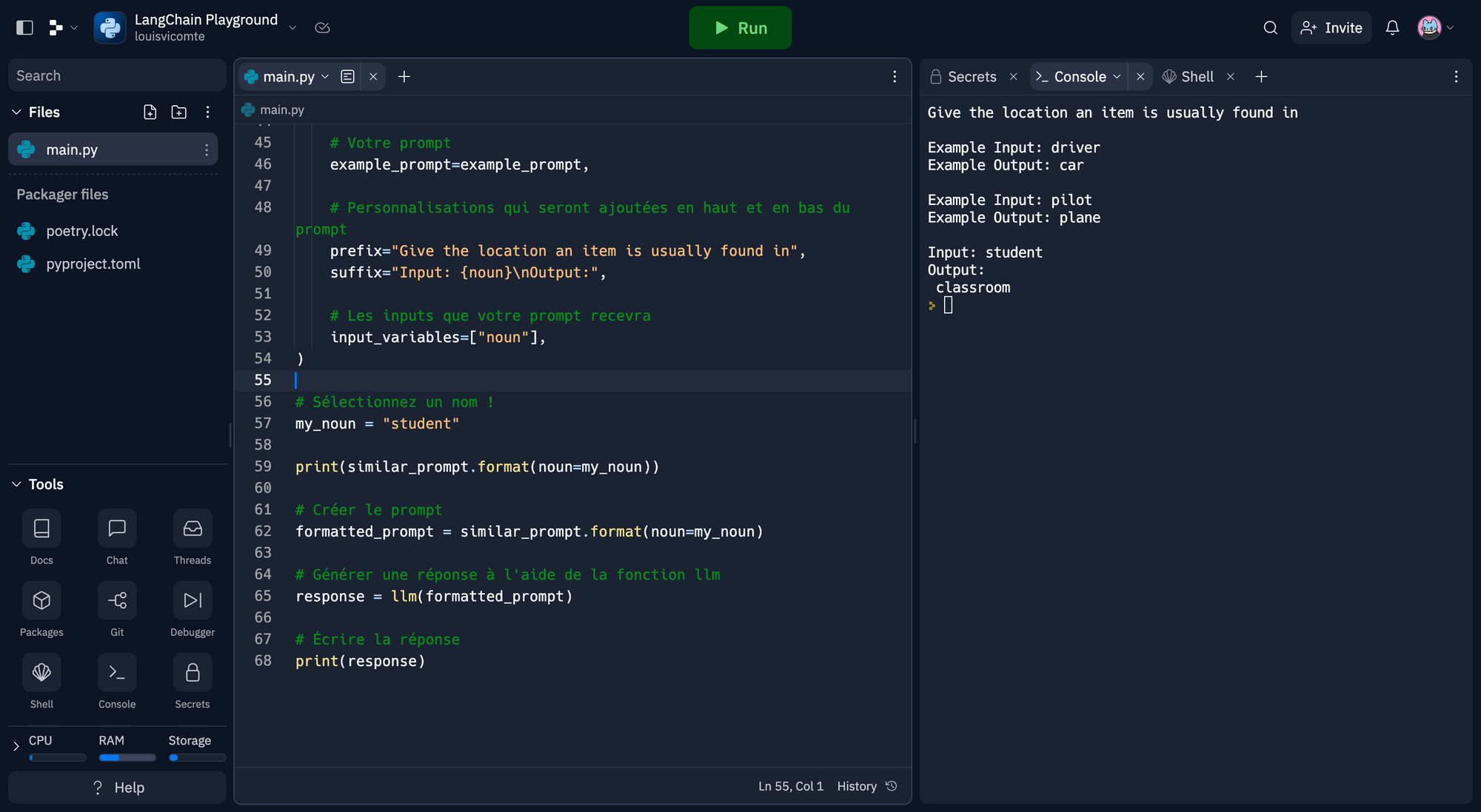
Analyseurs de sortie
Une façon utile de formater la sortie d'un modèle. Généralement utilisé pour les sorties structurées.
Deux grands concepts :
- Instructions de format - Un prompt autogénérée qui indique au LLM comment formater sa réponse en fonction du résultat souhaité.
- Parser - Une méthode qui va extraire la sortie texte de votre modèle dans une structure désirée (généralement json).
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, PromptTemplate
from langchain.llms import OpenAI
import os
llm = OpenAI(model_name="text-davinci-003", openai_api_key=os.environ['openai_api_key'])
# Comment vous souhaitez que votre réponse soit structurée. Il s'agit en fait d'un modèle de réponse sophistiqué
response_schemas = [
ResponseSchema(name="bad_string", description="This a poorly formatted user input string"),
ResponseSchema(name="good_string", description="This is your response, a reformatted response")
]
# Comment vous souhaitez analyser votre résultat
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# Voir le modèle de prompt que vous avez créé pour le formatage
format_instructions = output_parser.get_format_instructions()
print (format_instructions)
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
prompt = PromptTemplate(
input_variables=["user_input"],
partial_variables={"format_instructions": format_instructions},
template=template
)
promptValue = prompt.format(user_input="welcom to califonya!")
print(promptValue)
llm_output = llm(promptValue)
parsed_output = output_parser.parse(llm_output)
print(parsed_output)
Index - Structurer les documents de manière à ce que les LLM puissent travailler avec eux
Chargeurs de documents
Des moyens simples d'importer des données à partir d'autres sources. Fonctionnalités partagées avec les plugins OpenAI, en particulier les plugins d'extraction.
Voir une grande liste de chargeurs de documents ici. Il y en a aussi beaucoup d'autres sur Llama Index.
Pour utiliser cette fonction nous allons devoir installer bs4. Entrez pip install bs4 dans la fenêtre Shell et validez.
from langchain.document_loaders import HNLoader
loader = HNLoader("https://news.ycombinator.com/item?id=34422627")
data = loader.load()
print (f"Found {len(data)} comments")
print (f"Here's a sample:\n\n{''.join([x.page_content[:150] for x in data[:2]])}")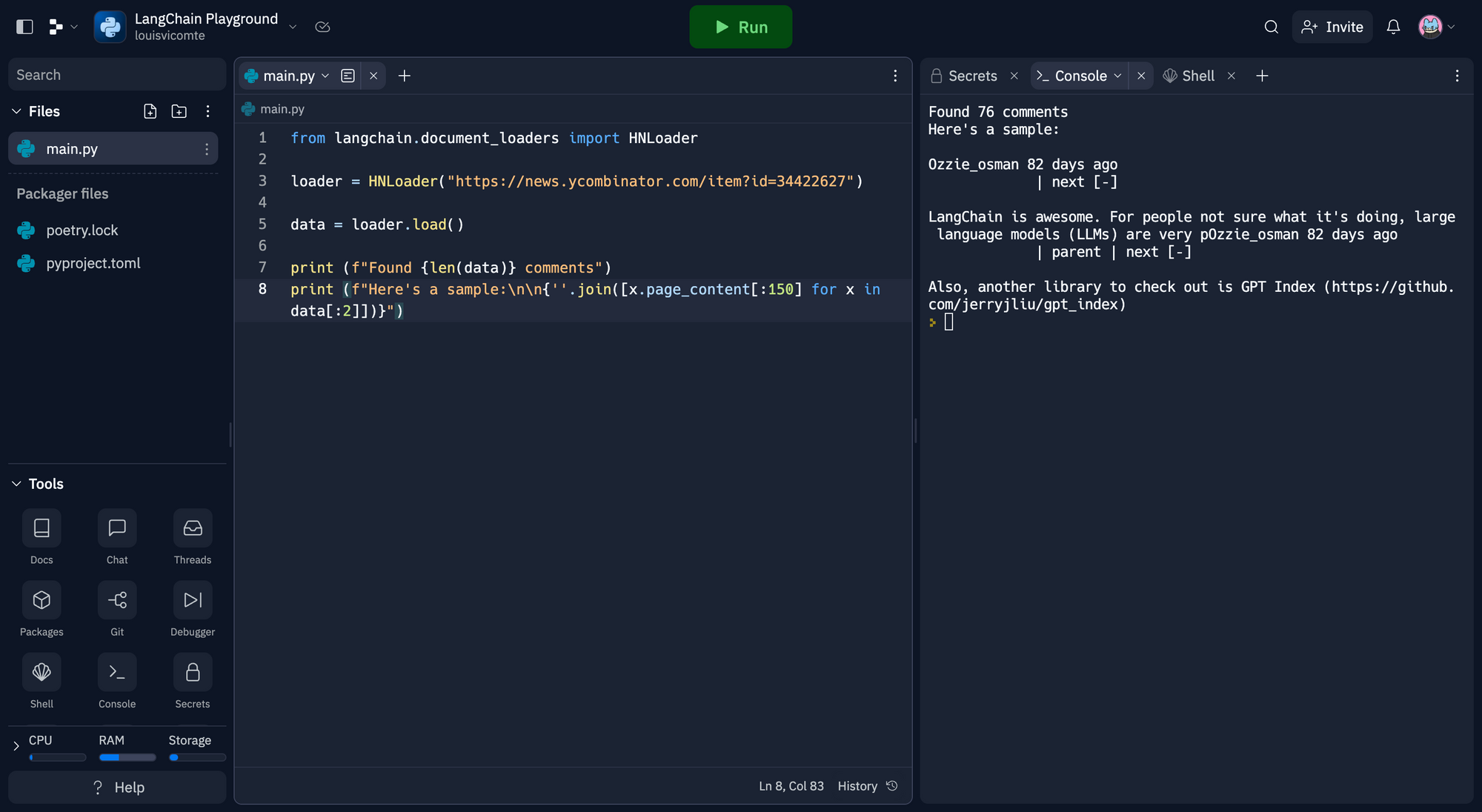
Séparateurs de texte
Souvent, votre document est trop long (comme un livre) pour votre LLM. Vous devez alors le diviser en plusieurs parties. Les séparateurs de texte vous aident à le faire.
Il existe de nombreuses façons de diviser votre texte en morceaux, essayez-en plusieurs pour voir ce qui vous convient le mieux.
Sur Replit, créer un nouveau dossier Data et créer un fichier bitcoin.txt, ou du nom que vous voulez.
Remplissez ce fichier texte avec du texte. Mettez ce que vous voulez. J'ai placé le texte du whitepaper du Bitcoin à l'intérieur.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Il s'agit d'un long document que nous pouvons scinder.
with open('data/bitcoin.txt') as f:
pg_work = f.read()
print (f"You have {len([pg_work])} document")
text_splitter = RecursiveCharacterTextSplitter(
# Définissez une taille de morceau très petite, juste pour montrer.
chunk_size = 150,
chunk_overlap = 20,
)
texts = text_splitter.create_documents([pg_work])
print (f"You have {len(texts)} documents")
print ("Preview:")
print (texts[0].page_content, "\n")
print (texts[1].page_content)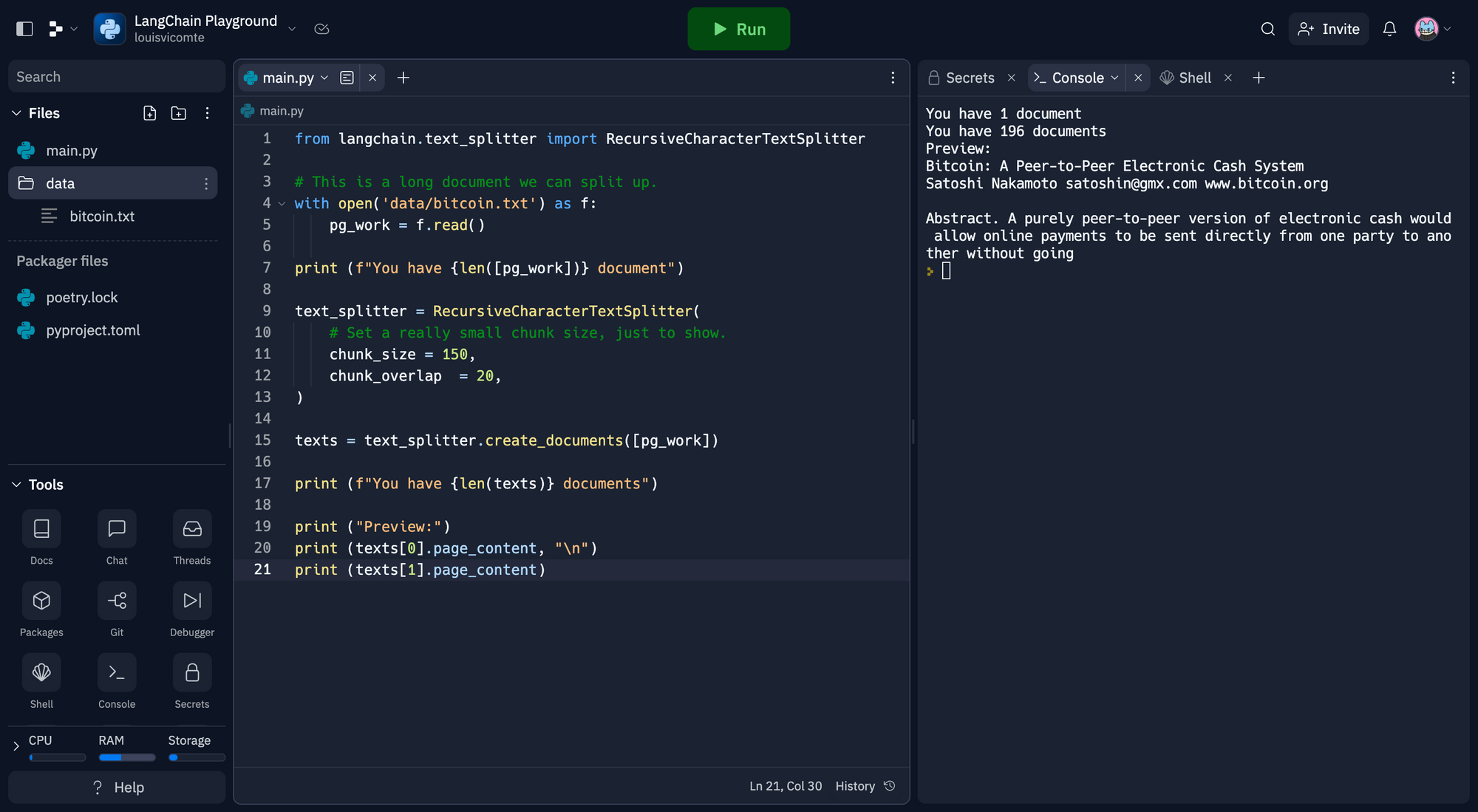
Retrievers
Une manière simple de combiner des documents avec des modèles de langage.
Il existe de nombreux types de récupérateurs, le plus répandu étant le VectoreStoreRetriever.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import os
loader = TextLoader('data/bitcoin.txt')
documents = loader.load()
# Préparez votre séparateur
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
# Divisez vos documents en textes
texts = text_splitter.split_documents(documents)
# Préparer le moteur d'intégration
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['openai_api_key'])
# Incorporer vos textes
db = FAISS.from_documents(texts, embeddings)
# Lancez votre retriever. Demande de restitution d'un seul document
retriever = db.as_retriever()
retriever
docs = retriever.get_relevant_documents("What is the goal of Bitcoin ?")
print("\n\n".join([x.page_content[:200] for x in docs[:2]]))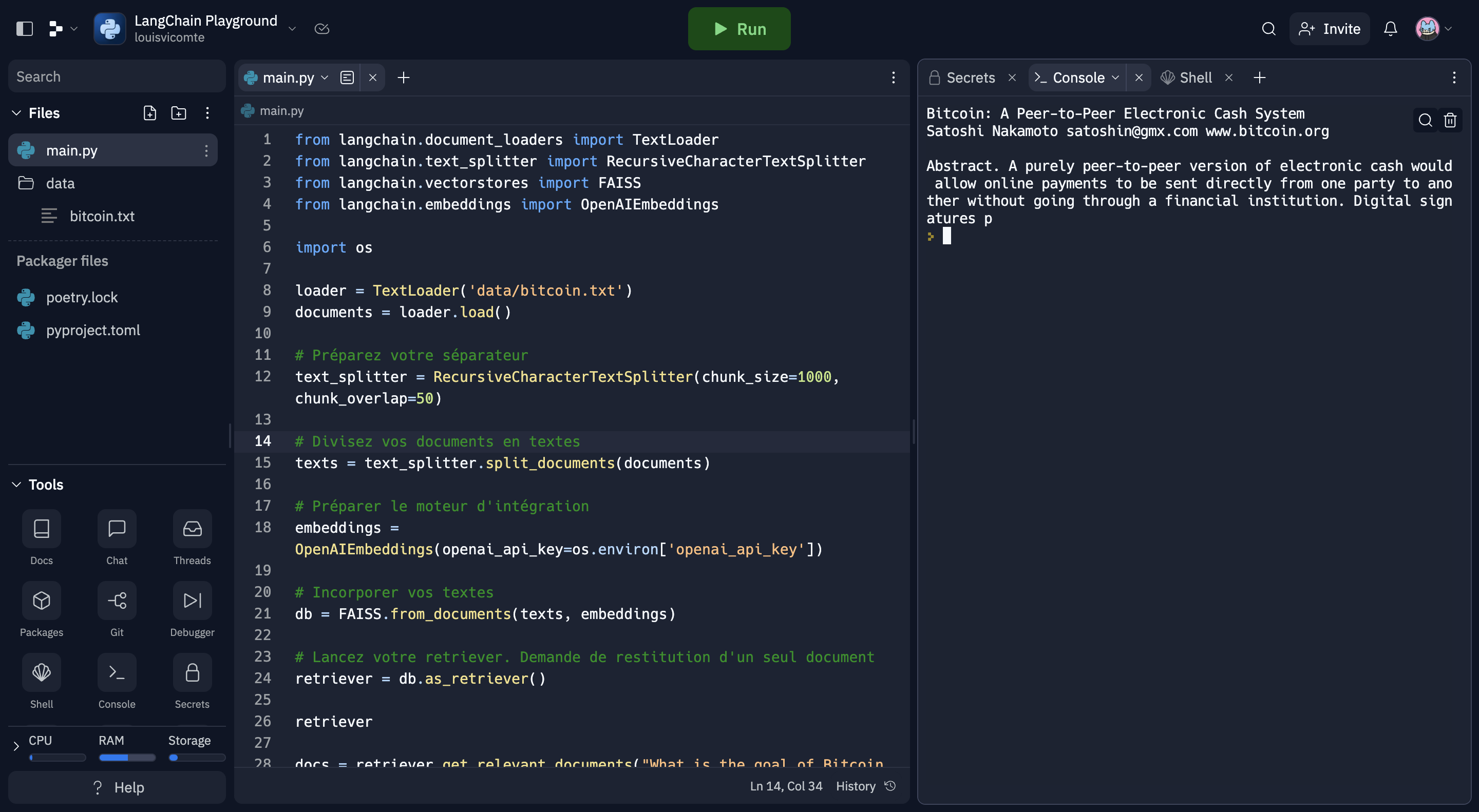
VectorStores
Bases de données pour stocker les vecteurs. Les plus populaires sont Pinecone et Weaviate. Plus d'exemples dans la documentation de OpenAIs retriever. Chroma et FAISS sont faciles à utiliser localement.
Conceptuellement, considérez-les comme des tableaux avec une colonne pour les embeddings (vecteurs) et une colonne pour les métadonnées.
Exemple de tableau :
| Embedding | Metadata |
|---|---|
| [-0.00015641732898075134, -0.003165106289088726, ...] | {'date' : '1/2/23} |
| [-0.00035465431654651654, 1.4654131651654516546, ...] | {'date' : '1/3/23} |
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import os
loader = TextLoader('data/bitcoin.txt')
documents = loader.load()
# Préparez votre séparateur
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
# Divisez vos documents en textes
texts = text_splitter.split_documents(documents)
# Préparer le moteur d'intégration
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['openai_api_key'])
print (f"You have {len(texts)} documents")
embedding_list = embeddings.embed_documents([text.page_content for text in texts])
print (f"You have {len(embedding_list)} embeddings")
print (f"Here's a sample of one: {embedding_list[0][:3]}...")
Votre vectorstore stocke vos embeddings (☝️) et les rend facilement consultables.
Mémoire
Aider les LLM à se souvenir des informations.
La mémoire est un terme un peu flou. Il peut s'agir simplement de se souvenir d'informations dont vous avez discuté dans le passé ou d'une recherche d'informations plus complexe.
Nous nous en tiendrons au cas d'utilisation des messages de conversation. Il s'agit d'un cas d'utilisation pour les agents conversationnels (chat bots).
Il existe de nombreux types de mémoire, explorez la documentation pour voir lequel correspond à votre cas d'utilisation.
Historique des messages de chat
Pour utiliser cette fonction nous devons nous assurer d'avoir la bonne version d'OpenAI avec pip install --upgrade openai, à entrer dans Shell.
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAI
import os
chat = ChatOpenAI(temperature=0, openai_api_key=os.environ['openai_api_key'])
history = ChatMessageHistory()
history.add_ai_message("hi!")
history.add_user_message("what is the capital of france?")
print("History before AI response:")
print(history.messages)
ai_response = chat(history.messages)
print("AI response:")
print(ai_response)
history.add_ai_message(ai_response.content)
print("History after AI response:")
print(history.messages)

Chaînes
Combiner différents appels et actions LLM automatiquement
Ex : Résumé #1, Résumé #2, Résumé #3 > Résumé final
Il existe de nombreuses applications des chaînes de recherche pour déterminer celles qui conviennent le mieux à votre cas d'utilisation.
Nous en aborderons deux :
1. Chaînes séquentielles simples
Chaînes faciles où vous pouvez utiliser la sortie d'un LMM comme entrée dans un autre. C'est un bon moyen de diviser les tâches (et de garder votre LLM concentré).
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
import os
llm = OpenAI(temperature=1, openai_api_key=os.environ['openai_api_key'])
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
# Tient ma chaîne de "location" (localisation).
location_chain = LLMChain(llm=llm, prompt=prompt_template)
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
# Tient ma chaîne de "meal" (repas).
meal_chain = LLMChain(llm=llm, prompt=prompt_template)
overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("Rome")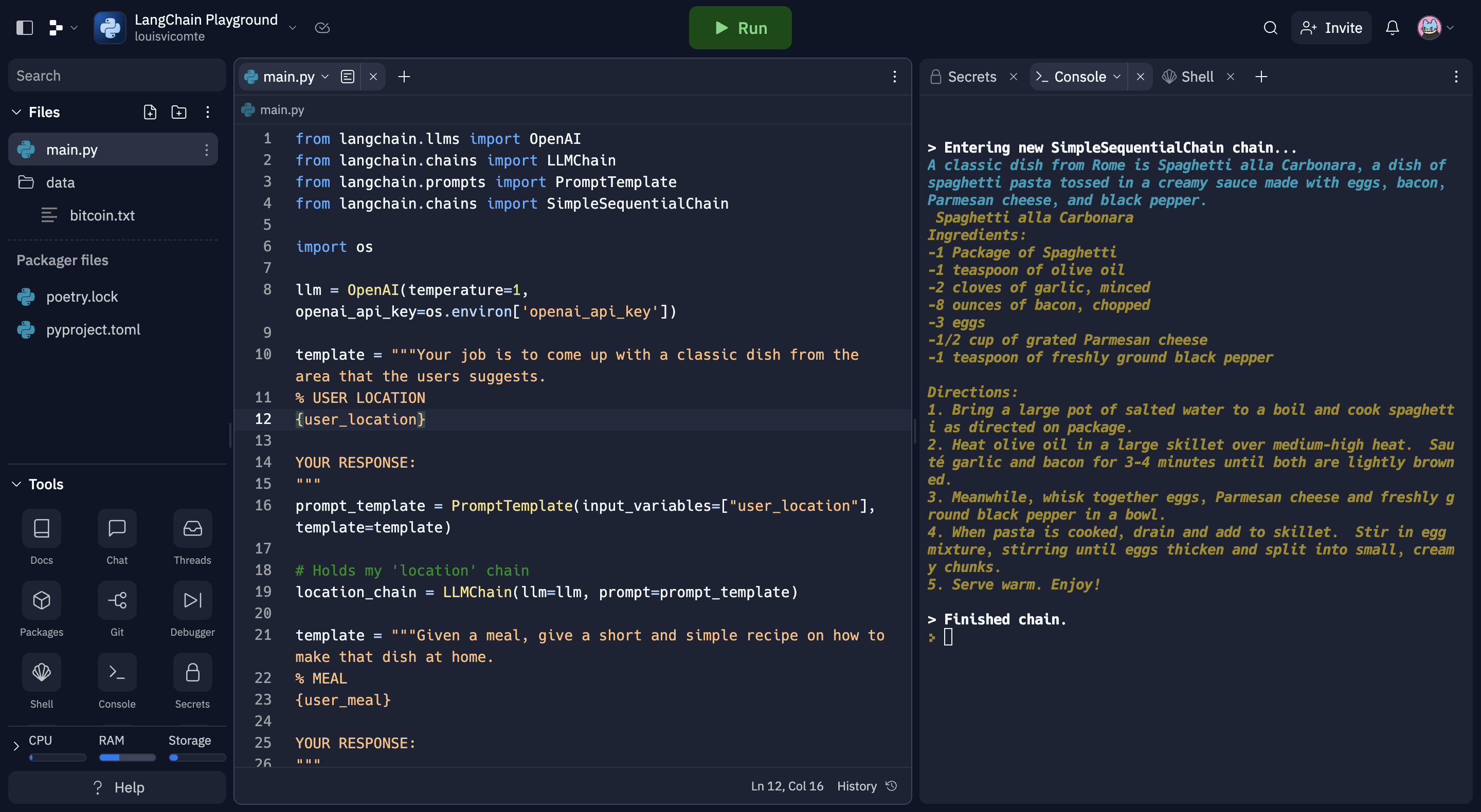
2. Chaîne de résumé
Il est facile de parcourir de nombreux et longs documents et d'en obtenir un résumé.
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
import os
llm = OpenAI(temperature=1, openai_api_key= os.environ['openai_api_key'])
loader = TextLoader('data/bitcoin.txt')
documents = loader.load()
# Préparez votre séparateur
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=50)
# Divisez vos documents en textes
texts = text_splitter.split_documents(documents)
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
summary = chain.run(texts)
print("Summary:")
print(summary)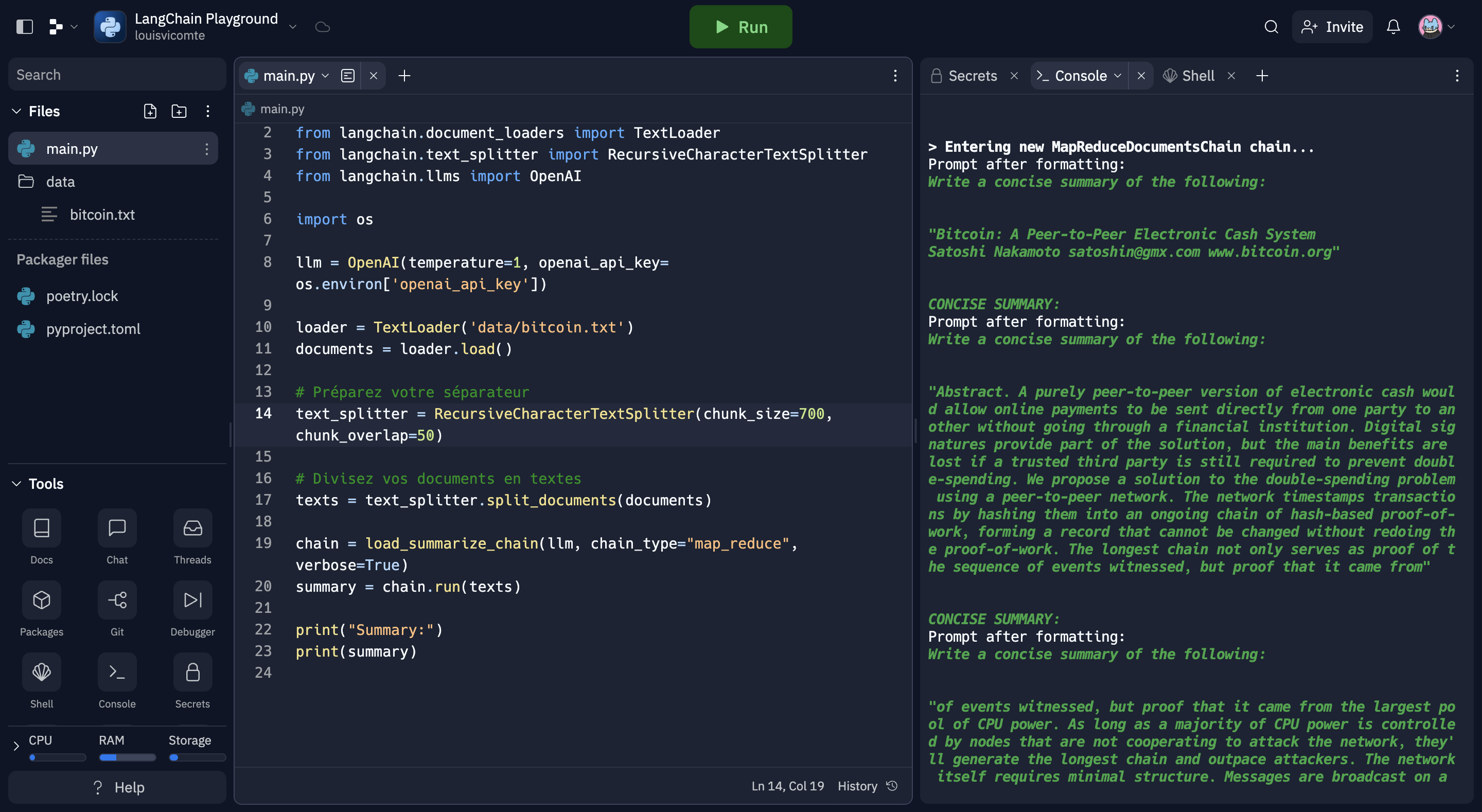
Agents
La documentation officielle LangChain décrit parfaitement les agents :
Certaines applications nécessiteront non seulement une chaîne prédéterminée d'appels aux LLMs/autres outils, mais aussi potentiellement une chaîne inconnue qui dépend de l'entrée de l'utilisateur. Dans ces types de chaînes, il y a un "agent" qui a accès à une suite d'outils. En fonction des données fournies par l'utilisateur, l'agent peut alors décider lequel de ces outils doit être appelé, le cas échéant.
En fait, vous utilisez les LLM non seulement pour produire du texte, mais aussi pour prendre des décisions. On n'insistera jamais assez sur l'intérêt et la puissance de cette fonctionnalité.
Sam Altman souligne que les LLM sont un bon "moteur de raisonnement". Les agents en tirent parti.
Les Agents
Le modèle de langage qui guide la prise de décision.
Plus précisément, un agent reçoit une entrée et renvoie une réponse correspondant à une action à entreprendre en même temps qu'une entrée d'action. Vous pouvez voir différents types d'agents (qui conviennent mieux à différents cas d'utilisation).
Tools
Une "capacité" d'un agent. Il s'agit d'une abstraction au-dessus d'une fonction qui permet aux LLM (et aux agents) d'interagir facilement avec elle. Ex : la recherche Google.
Ce domaine a des points communs avec les plugins OpenAI.
Toolkit
Groupes d'outils que votre agent peut sélectionner. Pour cet exemple nous allons avoir besoin d'une clé API SerpApi. Cela va nous permettre de récupérer des informations sur Google directement.
Puis on l'ajoute dans Secrets avec le nom serpapi_api_key.
Puis on installe google search results avec pip install google-search-results dans le Shell.

from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
import json
import os
llm = OpenAI(temperature=0, openai_api_key=os.environ['openai_api_key'])
serpapi_api_key=os.environ['serpapi_api_key']
toolkit = load_tools(["serpapi"], llm=llm, serpapi_api_key=serpapi_api_key)
agent = initialize_agent(toolkit, llm, agent="zero-shot-react-description", verbose=True, return_intermediate_steps=True)
response = agent({"input":"what was the first album of the"
"band that Mick Jagger is a part of?"})
print(json.dumps(response["intermediate_steps"], indent=2))

Conclusion
Félicitations, vous maîtrisez maintenant les bases de LangChain et savez comment l'utiliser avec l'API d'OpenAI. Ce guide vous a donné un aperçu des différentes possibilités offertes par LangChain pour résoudre divers problèmes. N'hésitez pas à explorer davantage la documentation et les exemples pour découvrir d'autres fonctionnalités et applications. En combinant LangChain et l'API d'OpenAI, vous êtes prêt à créer des solutions innovantes et résoudre des problèmes complexes. Bonne continuation dans votre exploration de ces puissants outils !
Pour en apprendre plus sur LangChain :
Source : langchain-tutorials



