

Qu'est-ce qu'un modèle de type Transformer dans l'IA et comment fonctionne-t-il ?

Les modèles de type Transformer sont une nouvelle avancée en matière d'apprentissage automatique qui fait beaucoup parler d'elle. Ils sont incroyablement doués pour capter le contexte, et c'est pourquoi les textes qu'ils génèrent ont du sens. Dans cet article de blog, nous examinerons leur architecture et leur fonctionnement.
Les bases d'un modèle Transformer
Les modèles Transformers sont une des nouvelles avancées les plus excitantes en matière de machine learning. Ils ont été introduits dans l'article "Attention is All You Need". Les Tranformers sont utilisés pour écrire des histoires, des essais, des poèmes, répondre à des questions, traduire des langues, discuter avec des humains, et peuvent même réussir des examens qui sont difficiles pour les humains ! Mais qu'est-ce que c'est ? Vous serez heureux de savoir que l'architecture des modèles de type Transformer n'est pas très complexe, elle se compose simplement de certains composants très utiles, chacun ayant sa propre fonction. Dans cet article, vous apprendrez tout ce qu'il faut savoir sur ces composants.
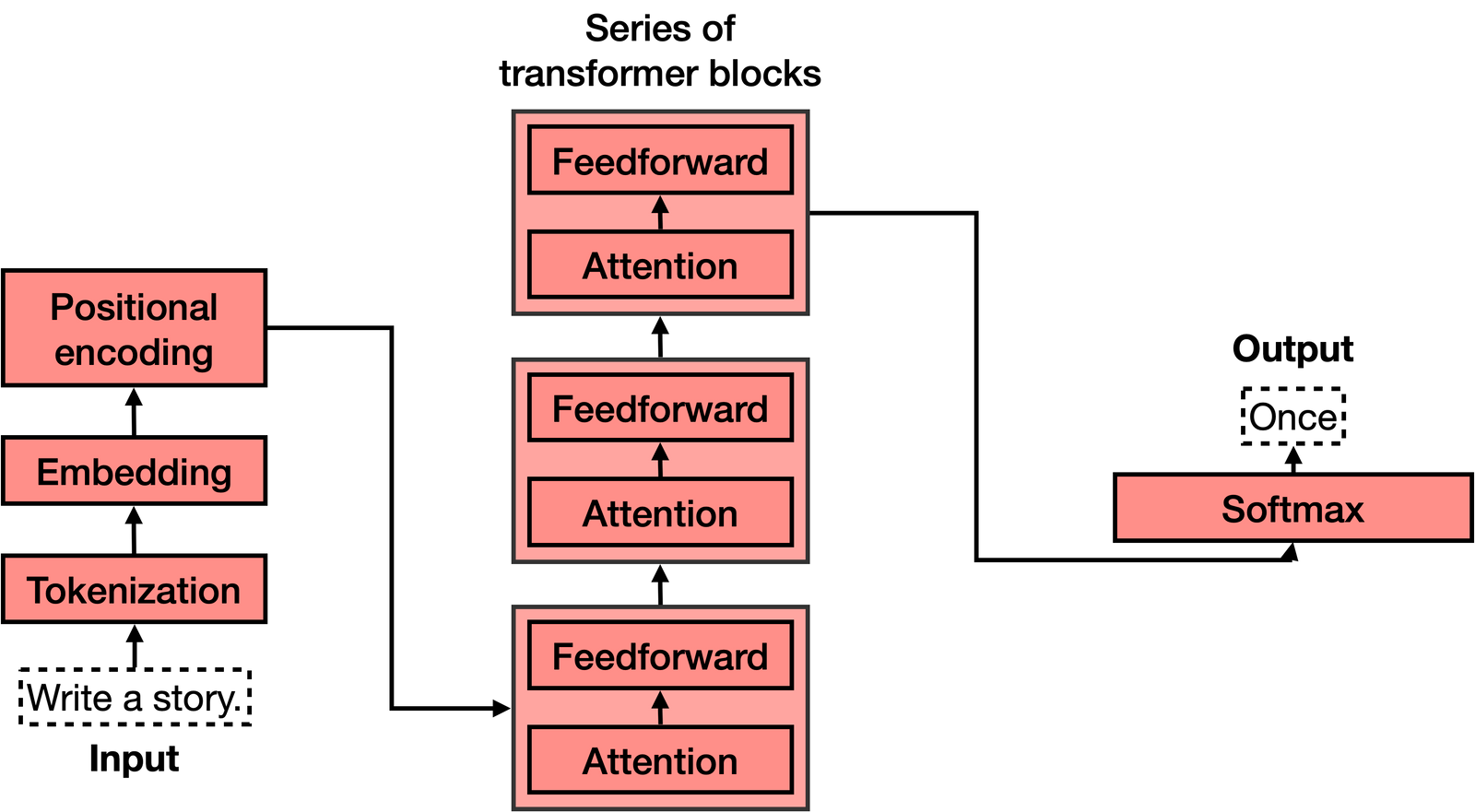
Pour une description plus détaillée des modèles de type Transformer et de leur fonctionnement, veuillez consulter ces deux excellents articles de Jay Alammar :
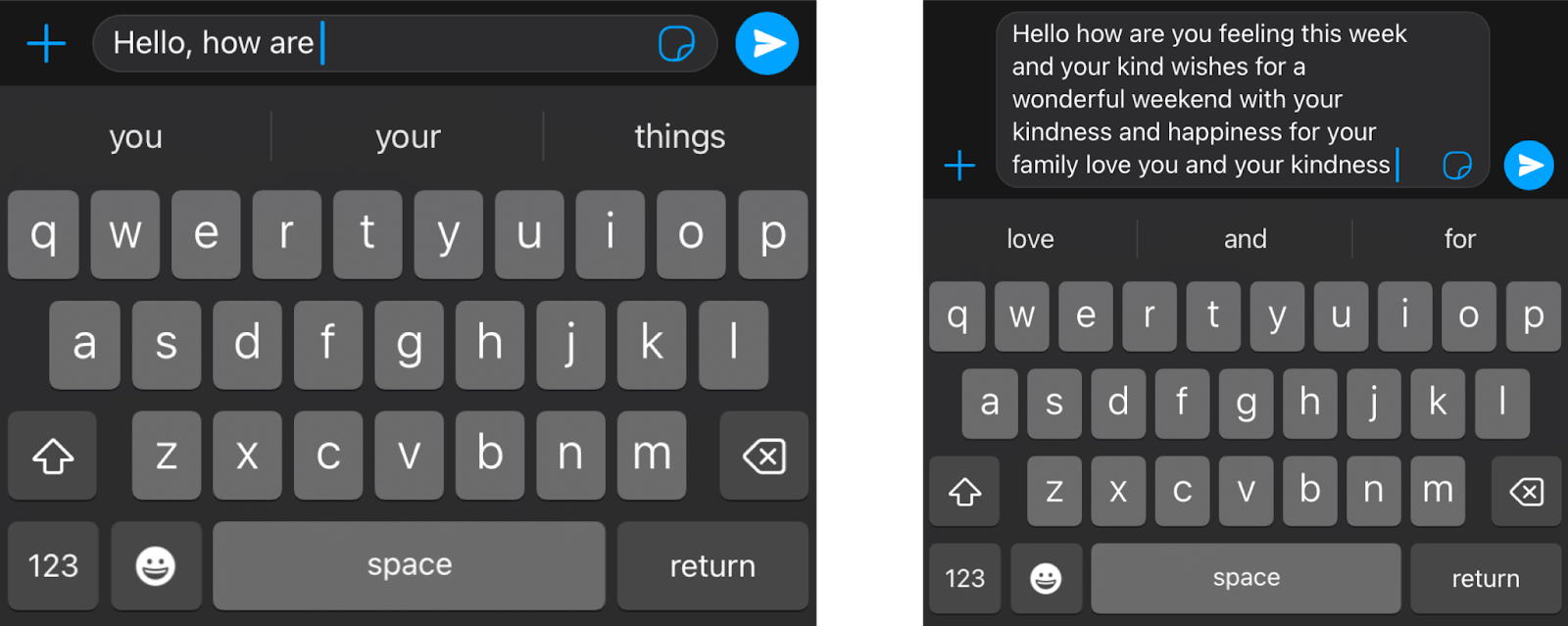
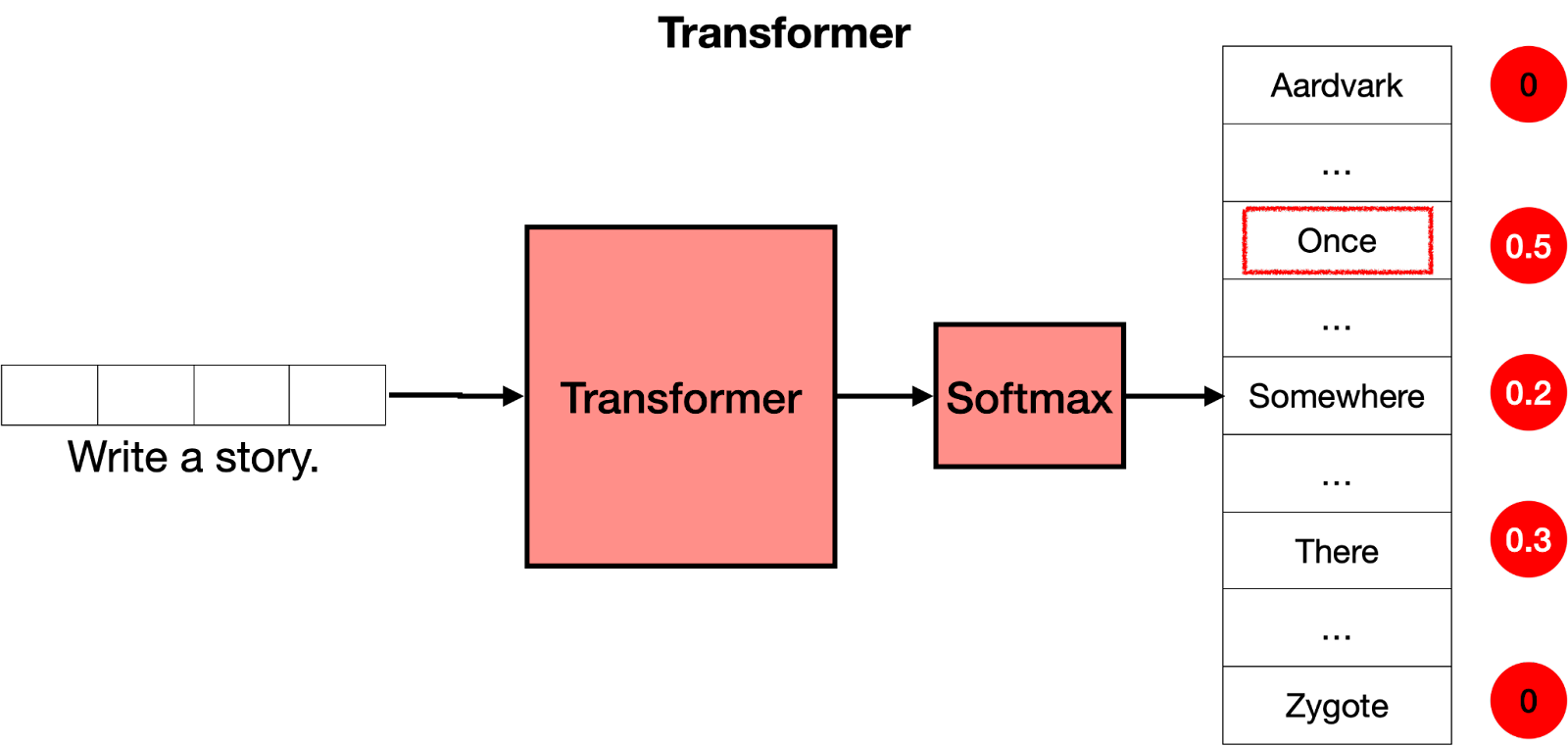
En un mot, à quoi sert un Transformer ? Imaginez que vous écrivez un message texte sur votre téléphone. Après chaque mot, trois autres mots vous sont proposés. Par exemple, si vous tapez "Bonjour, comment ça", le téléphone peut suggérer des mots tels que "va", "se" ou "passe" comme mot suivant. Bien sûr, si vous continuez à choisir le mot suggéré sur votre téléphone, vous verrez vite que le message formé par ces mots n'a pas de sens. Si vous regardez chaque ensemble de 3 ou 4 mots consécutifs, cela peut avoir un sens, mais ces mots ne se concatènent pas en quelque chose de significatif. C'est parce que le modèle utilisé dans le téléphone ne prend pas en compte le contexte global du message, il se contente de prédire quel mot est plus susceptible de venir après les derniers mots. Les Transformers, en revanche, gardent en mémoire le contexte de ce qui est écrit, et c'est pourquoi le texte qu'ils écrivent a du sens.
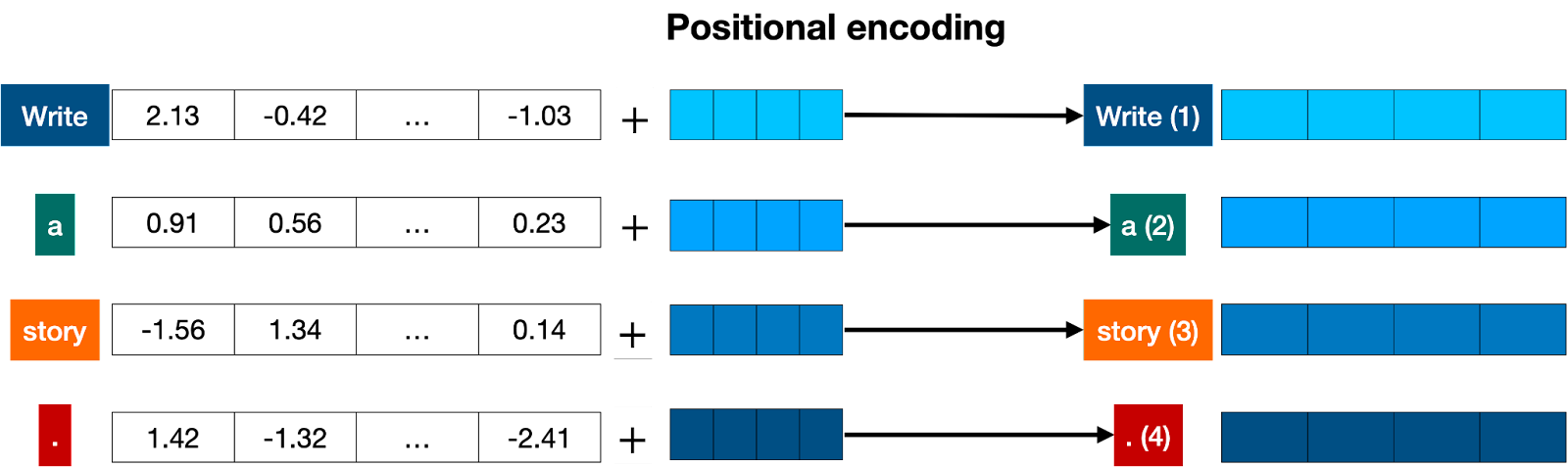
Tokenisation, vectorisation et encodage positionnel
L'architecture d'un modèle de type Transformer se décompose en plusieurs étapes :
- Tokenisation : l'entrée textuelle est transformée en une série de "tokens" ou de symboles, tels que des mots, des caractères ou des morceaux de mots.

- Vectorisation ou "embedding" : les tokens sont transformés en vecteurs numériques, qui représentent les entités sémantiques et les relations entre les tokens dans un espace multidimensionnel.

- Encodage positionnel : pour tenir compte de l'ordre des tokens et de leur position relative dans la séquence, on ajoute un signal positionnel aux vecteurs.
Blocs de type Transformer
Un modèle de type Transformer est constitué d'une série de blocs de type Transformer. Chaque bloc est composé de deux parties principales :
- Mécanisme d'attention : il permet de repérer les relations entre les différents tokens, en tenant compte du contexte.

- Réseau de neurones feedforward : il s'agit d'un réseau de neurones classique qui traite les informations et effectue des prédictions.
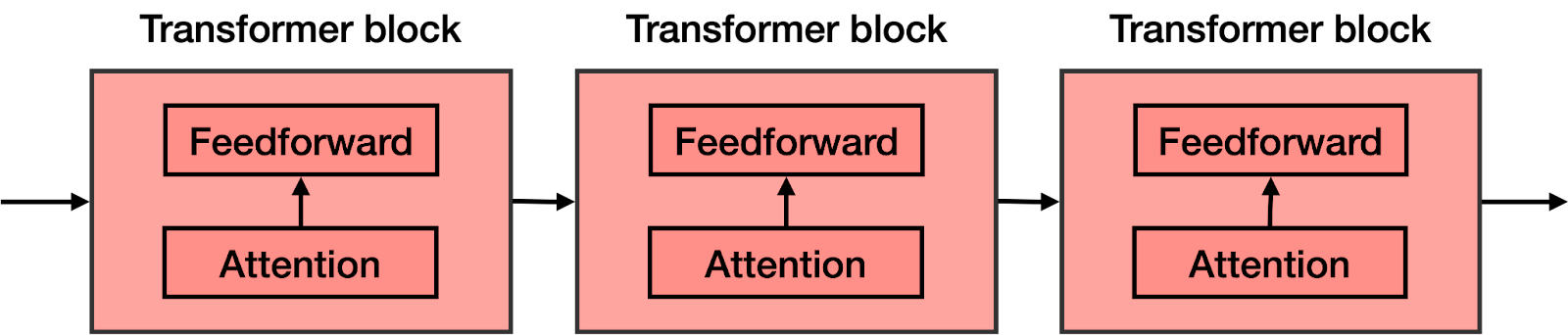
Les blocs de type Transformer sont empilés les uns sur les autres, formant l'architecture complète du modèle de type Transformer.
Enfin, la dernière étape consiste en une couche Softmax qui transforme les scores donnés par le Transformer en probabilités afin de choisir le mot suivant dans le texte.
Conclusion
Les modèles de type Transformer sont une avancée passionnante dans le domaine de l'apprentissage automatique, offrant des capacités de traitement et de génération de texte impressionnantes. En combinant la tokenisation, la vectorisation, l'encodage positionnel, les mécanismes d'attention et les réseaux de neurones feedforward, ils parviennent à capturer le contexte et à générer des prédictions pertinentes pour des tâches linguistiques complexes. Grâce à leur architecture modulaire et aux multiples couches de traitement de l'information, les modèles Transformers sont capables de maîtriser différents types de tâches, allant de la traduction automatique à la rédaction de textes complexes et cohérents.
L'importance de l'entraînement et du post-entraînement est également cruciale pour maximiser la performance et l'utilité de ces modèles. En les entraînant sur des ensembles de données spécifiques, tels que des questions-réponses ou des conversations, les Transformers peuvent être adaptés à des applications ciblées.
Dans l'ensemble, les modèles de type Transformer ouvrent la voie à une nouvelle génération d'intelligence artificielle capable de comprendre et de générer du texte de manière plus naturelle et précise que jamais auparavant. Les chercheurs et les développeurs continueront à explorer leur potentiel pour découvrir de nouvelles applications et approfondir notre compréhension du traitement du langage naturel et de l'apprentissage automatique en général.



