

FAISS : une bibliothèque pour la recherche de similarités efficace

Présentation de Faiss
Faiss, développé par Facebook AI Similarity Search, est une bibliothèque qui permet de rechercher rapidement des documents multimédias similaires. Contrairement aux moteurs de recherche traditionnels, Faiss offre une implémentation de recherche des plus proches voisins pour des ensembles de données à l'échelle du milliard, avec une vitesse jusqu'à 8,5 fois supérieure à celle de l'état de l'art précédent. Cette bibliothèque permet également de construire des graphes de plus proches voisins sur 1 milliard de vecteurs à haute dimension.
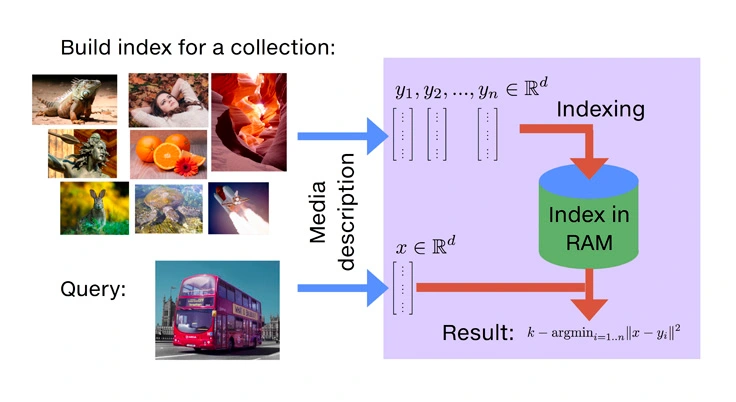
À propos de la recherche de similarités
La recherche de similarités repose sur l'utilisation de vecteurs à haute dimension générés par des outils d'IA, tels que les plongements de texte (word2vec) ou les descripteurs de réseaux neuronaux convolutionnels (CNN) entraînés avec l'apprentissage profond. Les bases de données traditionnelles et les langages de requêtes standards ne sont pas adaptés à ces nouvelles représentations en raison de leur taille et de leur complexité.
Fonctionnalités de Faiss
Faiss propose plusieurs méthodes de recherche de similarités optimisées en termes de mémoire et de rapidité. La bibliothèque offre également une implémentation GPU de pointe pour les méthodes d'indexation les plus pertinentes.
Évaluation de la recherche de similarités
Faiss se concentre sur les méthodes qui compriment les vecteurs originaux, car elles sont les seules à pouvoir s'adapter à des ensembles de données de milliards de vecteurs. L'évaluation de la précision, de la rapidité et de l'utilisation de la mémoire est essentielle pour déterminer les meilleures méthodes d'indexation.
Utilisation de Faiss
Faiss est implémenté en C++ et dispose de liaisons en Python. La bibliothèque est entièrement intégrée avec numpy et toutes les fonctions prennent des tableaux numpy (en float32). Faiss fournit des instances d'Index, où chaque sous-classe d'Index implémente une structure d'indexation à laquelle des vecteurs peuvent être ajoutés et recherchés.


