

Les chercheurs en IA affirment pouvoir doubler l'efficacité des chatbots

Abacus AI prétend avoir trouvé un moyen d'optimiser les LLM (Large Language Models), leur permettant de traiter 200% de leur capacité originale en tokens de contexte.
Un problème d'attention numérique ?
Avez-vous déjà remarqué que votre chatbot AI se perdait au milieu d'une conversation, ou qu'il disait simplement qu'il ne pouvait pas gérer des invites trop longues ? C'est parce que chaque modèle a une limitation dans ses capacités de traitement et commence à souffrir une fois qu'il dépasse cette limite - un peu comme s'il souffrait d'un type de trouble déficitaire de l'attention numérique. Mais cela pourrait bientôt changer grâce à une nouvelle méthode pour surcharger les capacités des LLM.

Les LLM actuels ont des capacités de contexte limitées. Par exemple, ChatGPT n'utilise que 8 000 tokens de contexte, tandis que Claude en gère 100 000. Les tokens sont les unités de base de texte ou de code utilisées par un LLM AI pour traiter et générer du langage. Cela limite la quantité d'informations de fond qu'ils peuvent exploiter lorsqu'ils formulent des réponses. Abacus AI a développé une méthode qui doublerait soi-disant la longueur de contexte utilisable pour des LLM open-source comme Llama de Meta sans compromettre la précision du modèle en application pratique.
L'échelle fait la différence
Leur technique implique la "mise à l'échelle" des embeddings de position qui suivent les emplacements des mots dans les textes d'entrée. Selon leur page Github, Abacus AI prétend que sa méthode de mise à l'échelle augmente considérablement le nombre de tokens qu'un modèle peut gérer.
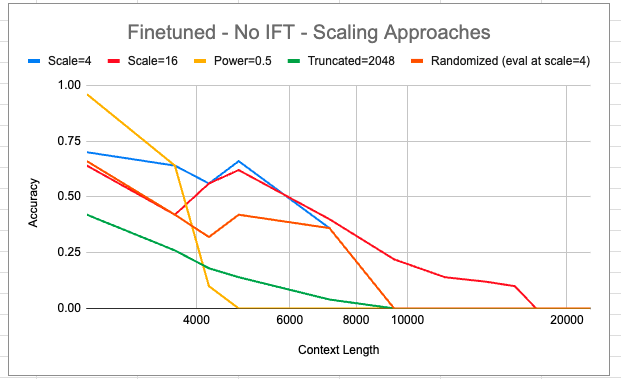
Les chercheurs ont évalué deux variantes de LlaMA mises à l'échelle sur des tâches comme la localisation de sous-chaînes et les questions-réponses ouvertes. Le modèle à l'échelle 16 a maintenu la précision sur des exemples réels jusqu'à des contextes de 16 000 mots, contre seulement 2 000 mots dans Llama de base. Il a même montré une certaine cohérence à plus de 20 000 mots, ce qui n'était pas possible à réaliser avec de simples techniques d'optimisation.
L'importance du contexte
L'importance de l'extension du contexte ne peut être surestimée. Une fenêtre de contexte étroite rend le modèle précis mais pas vraiment utilisable dans des tâches complexes qui nécessitent des antécédents. À l'inverse, avec un contexte élargi, les LLM peuvent traiter et générer de meilleures réponses mais prennent plus de temps pour le faire ou renvoient des résultats inférieurs à la moyenne. Gérer des contextes plus longs efficacement pourrait permettre aux LLM d'absorber des documents entiers ou plusieurs documents comme arrière-plan lors de la génération de texte. Cela pourrait conduire à des sorties qui sont plus ancrées dans la connaissance et cohérentes sur de longues conversations.
Cependant, les gains ne sont pas parfaitement proportionnels aux facteurs d'échelle. Il est encore nécessaire d'affiner les stratégies car la mise à l'échelle seule ne garantit pas des résultats de haute qualité. L'équipe d'Abacus explore également des schémas d'encodage de position avancés provenant de documents récents pour étendre davantage la capacité de contexte.
Vers des modèles à grande échelle
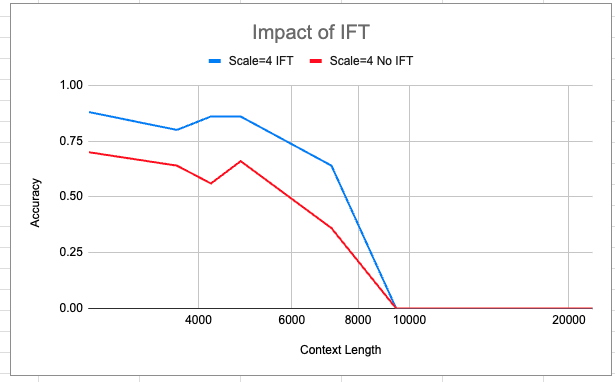
Leur travail suggère que la mise à l'échelle des LLM existants est une voie viable pour étendre la longueur de contexte utilisable. Cela pourrait démocratiser l'accès à des Large Language Models capables de gérer beaucoup de contexte à la fois.
Abacus AI a ouvert les portes de leur dépôt "à des fins de recherche uniquement", partageant le code spécifique à leurs projets de fine-tuning. Cela rend possible d'itérer davantage sur son développement et d'appliquer les méthodes de fine-tuning sur pratiquement n'importe quel Large Language Model open source.
Avec des applications allant des chatbots personnalisés aux aides à l'écriture créative, des LLM plus puissants pourraient bientôt permettre des assistants AI de nouvelle génération qui sont capables de converser sur divers sujets. Pour l'instant, les chercheurs progressent rapidement pour surmonter les contraintes techniques dans la poursuite de l'intelligence artificielle générale - c'est-



