

La nouvelle approche QLoRA permet d'affiner l'IA sur les GPU grand public

Introduction
Dans le domaine en constante évolution de l'intelligence artificielle (IA), une nouvelle avancée a été réalisée. Une approche de finetuning efficace nommée QLORA a été présentée, qui réduit l'utilisation de la mémoire pour finetuner un modèle de 65 milliards de paramètres sur un seul GPU de 48GB tout en préservant les performances de la tâche de finetuning en 16 bits.
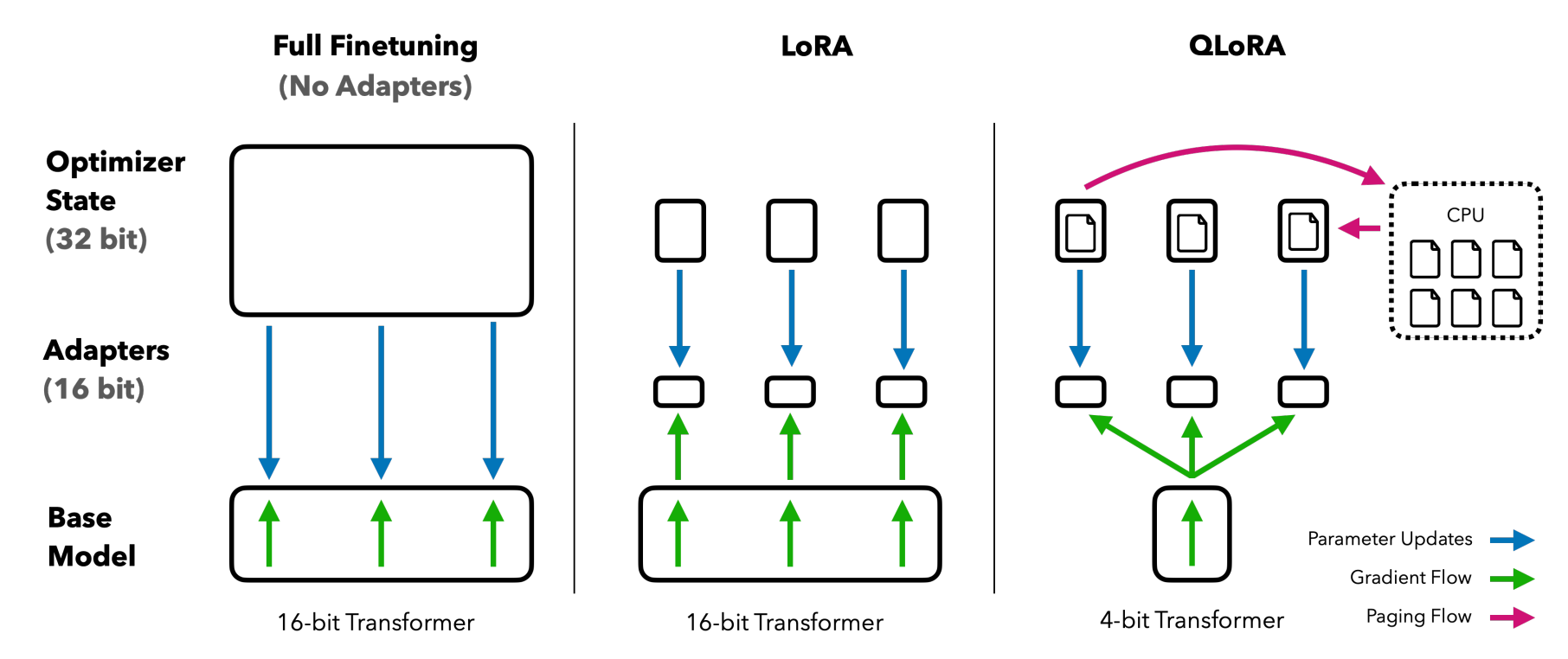
QLORA et ses Innovations
QLORA rétropropage les gradients à travers un modèle de langage pré-entraîné gelé et quantifié à 4 bits dans les adaptateurs à faible rang (LoRA). Cette méthode introduit un certain nombre d'innovations pour économiser la mémoire sans sacrifier les performances.
La Famille de Modèles Guanaco
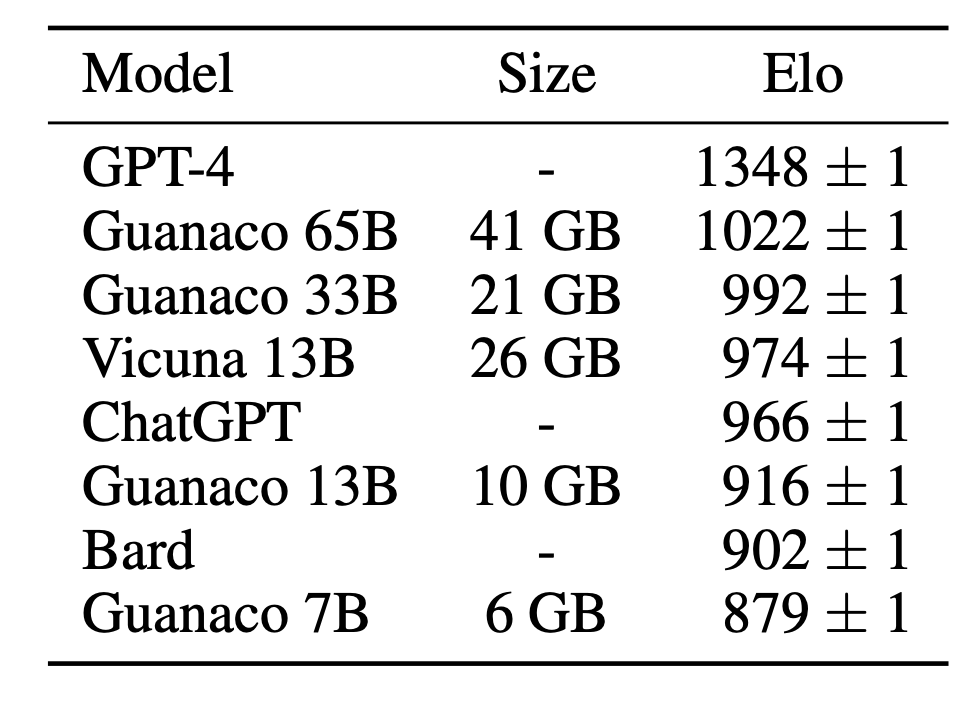
La meilleure famille de modèles, nommée Guanaco, surpasse tous les modèles précédemment publiés sur le benchmark Vicuna, atteignant 99,3% du niveau de performance de ChatGPT tout en nécessitant seulement 24 heures de finetuning sur une seule GPU.
Analyse de Performance
Le document fournit une analyse détaillée des performances de suivi des instructions et des chatbots sur 8 ensembles de données d'instructions, plusieurs types de modèles (LLaMA, T5), et des échelles de modèles qui seraient infaisables à exécuter avec un finetuning régulier (par exemple, des modèles de 33B et 65B de paramètres).
Conclusion
En conclusion, QLORA représente une avancée significative dans le domaine de l'IA, en particulier dans le finetuning des modèles de langage. Cependant, le document souligne également que les benchmarks actuels de chatbot ne sont pas fiables pour évaluer avec précision les niveaux de performance des chatbots. Cette découverte souligne l'importance de développer des méthodes d'évaluation plus robustes à mesure que la technologie de l'IA continue d'évoluer.
Source : ArXiv



