

Orca LLM : Simuler les processus de raisonnement de ChatGPT

Dans le monde des grands modèles linguistiques (LLMs), il y a une quête constante pour améliorer les capacités des modèles plus petits sans compromettre leur efficacité. L'article Orca : Apprentissage progressif à partir des traces d'explication complexes de GPT-4 introduit Orca, un modèle de 13 milliards de paramètres conçu pour imiter le processus de raisonnement des grands modèles de fondation (LFMs) tels que GPT-4.
Introduction
L'approche traditionnelle a été d'utiliser l'apprentissage par imitation, où les modèles plus petits apprennent à partir des sorties générées par les LFMs. Cependant, cette approche a été entravée par plusieurs défis, y compris les signaux d'imitation limités à partir des sorties peu profondes des LFMs, les données d'entraînement homogènes à petite échelle, et un manque d'évaluation rigoureuse. Cela conduit souvent les modèles plus petits à imiter le style mais pas le processus de raisonnement des LFMs.
Méthodologie de formation
La méthode d'entraînement d'Orca se compose de deux étapes.
Dans la première étape, Orca est formé sur FLAN-5M, qui inclut des augmentations de ChatGPT. Cet assistant enseignant intermédiaire aide à combler l'écart de capacité entre Orca et GPT-4, qui a une taille de paramètres nettement plus grande. En tirant parti des capacités de ChatGPT, Orca bénéficie d'une amélioration des performances de l'apprentissage par imitation.
Dans la deuxième étape, Orca suit une formation sur FLAN-1M, qui intègre des augmentations de GPT-4. Cette approche d'apprentissage progressif suit un paradigme d'apprentissage par curriculum, où le modèle étudiant apprend à partir d'exemples plus faciles avant de s'attaquer à des tâches plus difficiles. En exposant progressivement Orca à un raisonnement de plus en plus complexe et à des explications étape par étape, le modèle améliore ses capacités de raisonnement et d'imitation.
Avantages et Contributions
La méthodologie de formation d'Orca offre plusieurs avantages par rapport aux LLMs traditionnels.
Tout d'abord, elle aborde le problème de l'écart de capacité en utilisant un modèle enseignant intermédiaire, permettant à Orca d'apprendre à partir d'une source plus capable. Cette approche a été démontrée comme améliorant les performances de l'apprentissage par imitation pour les modèles étudiants plus petits.
Deuxièmement, l'aspect d'apprentissage progressif de la formation d'Orca permet au modèle de construire progressivement ses connaissances. En commençant par des exemples plus simples et en introduisant progressivement des exemples plus complexes, Orca développe une base plus solide pour le raisonnement et la génération d'explications.
De plus, la capacité d'Orca à imiter le processus de raisonnement des LFMs comme GPT-4 ouvre des possibilités pour une performance améliorée dans diverses tâches. En exploitant les signaux riches fournis par les traces d'explication et les processus de pensée étape par étape de GPT-4, Orca acquiert des informations précieuses et améliore ses propres capacités.
Performances
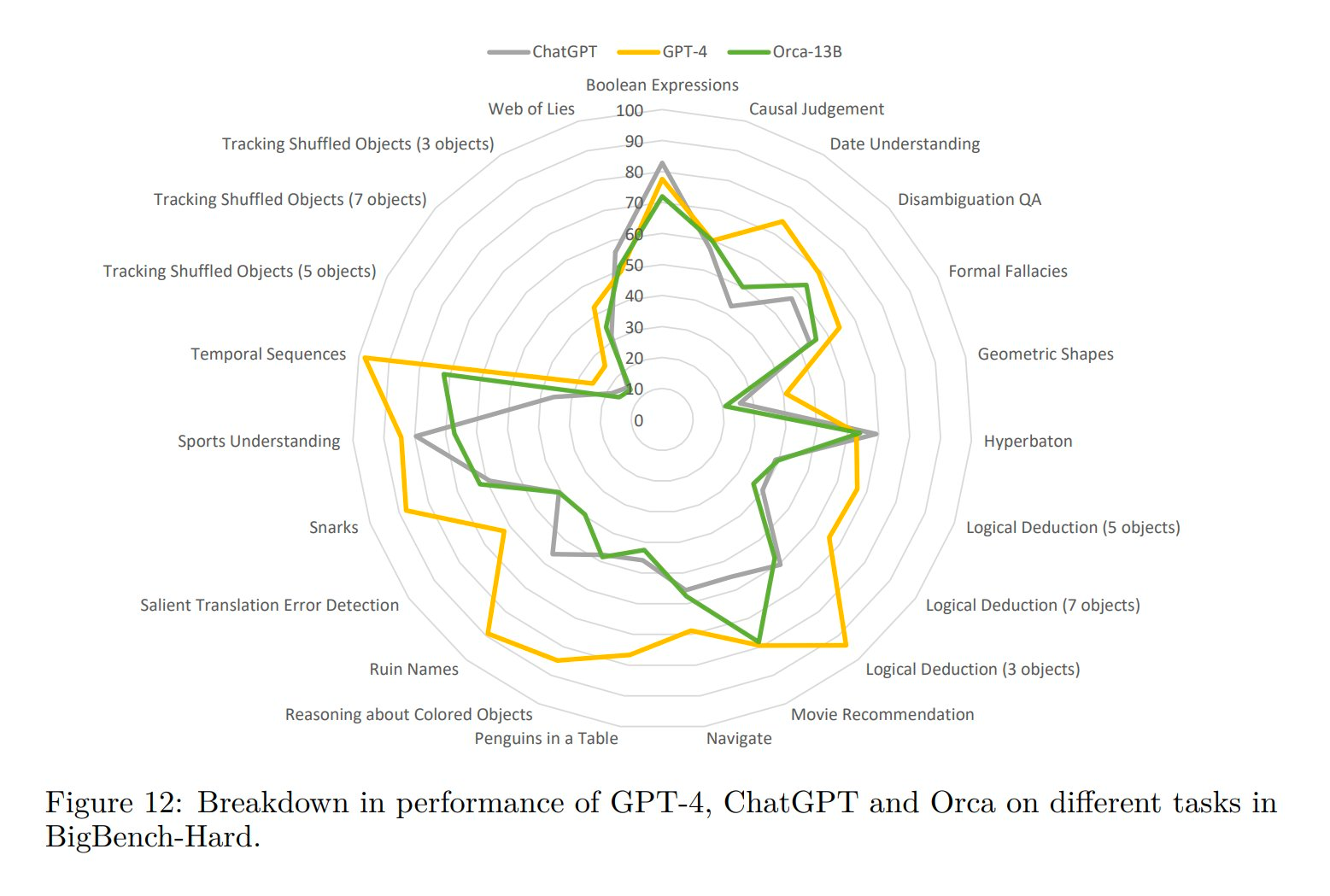
Orca a montré des performances remarquables dans les benchmarks de raisonnement complexe en configuration zero-shot. Il surpasse les modèles traditionnels à la pointe de la technologie comme Vicuna-13B de plus de 100% sur des benchmarks comme Big-Bench Hard (BBH) et de plus de 42% sur AGIEval. En outre, Orca atteint les mêmes scores que ChatGPT sur les benchmarks BBH et montre une performance compétitive sur des examens professionnels et académiques tels que le SAT, LSAT, GRE, et GMAT. Cela est particulièrement impressionnant étant donné que ce sont des paramètres zero-shot sans chaîne de pensée, et Orca reste compétitif tout en étant à la traîne derrière GPT-4.
Implications et Directions futures
Le développement d'Orca représente une avancée significative dans le domaine des LLMs. En apprenant à partir de signaux riches et en imitant le processus de raisonnement des LFMs, Orca est capable d'effectuer des tâches de raisonnement complexe avec un haut degré de précision. Cela a des implications de grande portée, en particulier dans les domaines où un raisonnement complexe et la résolution de problèmes sont nécessaires.
De plus, cette recherche indique que l'apprentissage à partir des explications étape par étape des modèles d'IA est une direction prometteuse pour l'amélioration des capacités des modèles. Cela ouvre de nouvelles voies pour la recherche et le développement dans le domaine des LLMs.
Conclusion
Orca présente une nouvelle approche pour la formation des grands modèles linguistiques, combinant l'apprentissage progressif et l'assistance de l'enseignant pour améliorer l'apprentissage par imitation. En exploitant des modèles enseignants intermédiaires et en exposant progressivement le modèle étudiant à des exemples plus complexes, Orca surmonte l'écart de capacité et améliore ses capacités de raisonnement et de génération d'explications. Les résultats de l'article contribuent à l'avancement des techniques d'apprentissage par imitation et ont des implications pour le développement de futurs modèles linguistiques.
Source : Microsoft



