

Synthèse de vidéos haute définition avec des modèles de diffusion latente

Toronto AI Lab présente de nouveaux modèles d'intelligence artificielle pour générer des vidéos de haute résolution grâce à une approche fondée sur les modèles de diffusion latente (Latent Diffusion Models, LDMs). Ces modèles permettent une synthèse d'images de haute qualité tout en évitant une consommation excessive de ressources informatiques. Les applications potentielles incluent la simulation de données de conduite dans la nature et la création de contenu créatif à partir de texte.
Modèles de diffusion latente pour la production vidéo
L'équipe a mis au point des modèles de diffusion latente pour la production vidéo (Video LDMs) pour générer des vidéos haute résolution de manière efficace sur le plan informatique. Pour surmonter les défis liés à la consommation élevée de ressources des vidéos en haute résolution, les chercheurs ont appliqué le paradigme LDM au domaine de la vidéo.
Les Video LDMs transforment les vidéos en un espace latent compressé et modélisent des séquences de variables latentes correspondant aux images des vidéos. Les modèles sont initialisés à partir des LDMs d'image existants et des couches temporelles sont ajoutées dans les réseaux de débruitage des LDMs pour modéliser les séquences de cadres vidéo encodés.
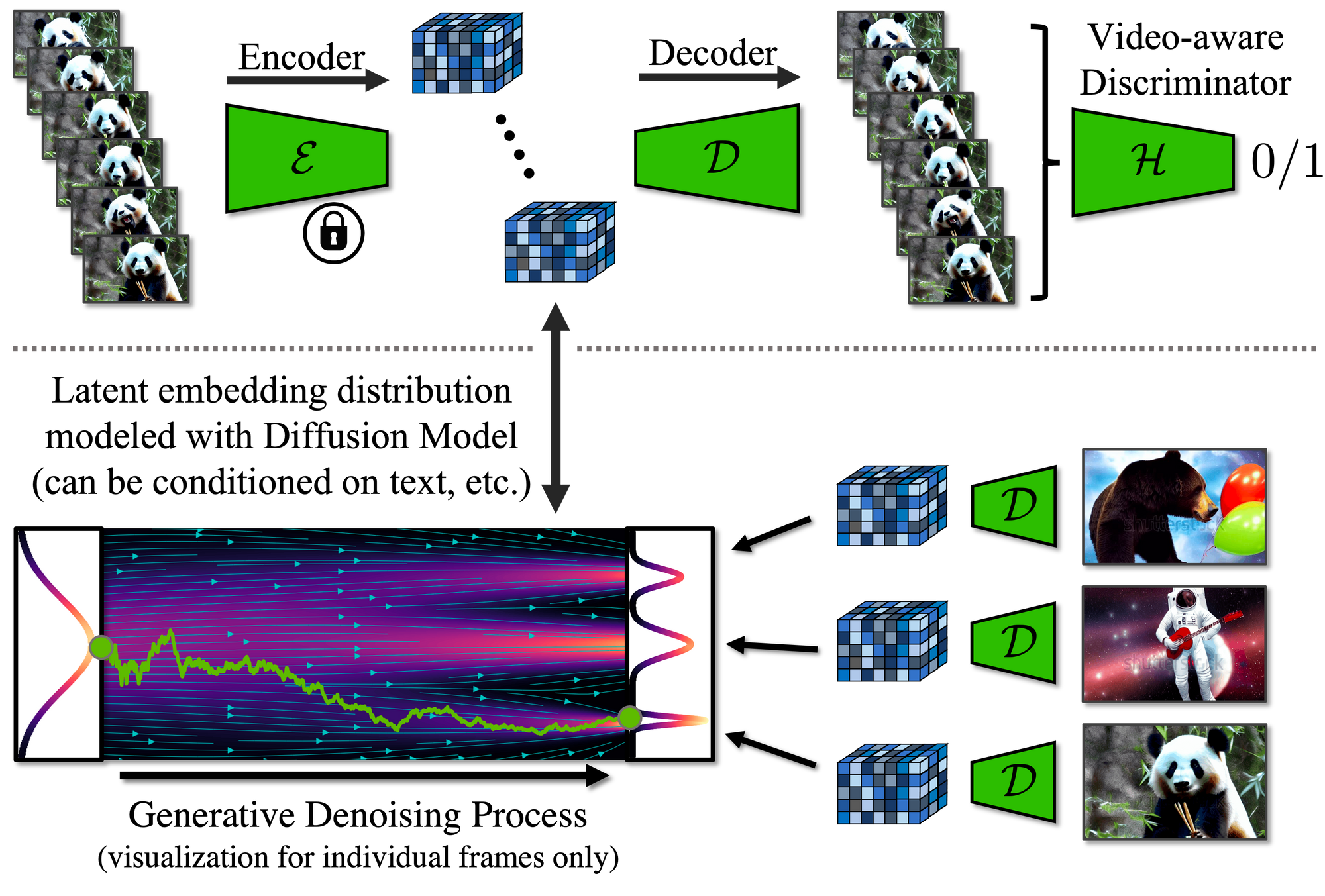
Applications de la création de vidéos
L'équipe a validé son approche avec deux applications distinctes mais pertinentes: la génération de vidéos de scène de conduite en situation réelle et la création de contenu créatif à partir de modélisation texte-vidéo. Pour la synthèse de vidéos de conduite, les Video LDMs permettent de générer des vidéos cohérentes sur le plan temporel, d'une durée de plusieurs minutes et d'une résolution de 512 x 1024 pixels. Les chercheurs ont également réussi à obtenir des vidéos basées sur des textes de quelques secondes avec une résolution allant jusqu'à 1280 x 2048 pixels.
Synthèse de vidéos à partir de texte
Les vidéos générées sont des vidéos à 24 images par seconde qui durent environ 4,7 secondes et ont une résolution de 1280 x 2048 pixels. Cette approche repose sur le modèle Stable Diffusion, qui compte 4,1 milliards de paramètres et permet de produire des vidéos de haute résolution, cohérentes et diversifiées.
Génération de vidéos personnalisées
En utilisant les couches temporelles apprises et en les insérant dans d'autres modèles LDM, les chercheurs ont également obtenu des résultats initiaux pour la génération de vidéos personnalisées à partir de texte.
Synthèse de vidéos pour des scènes de conduite
En plus des applications de texte à la vidéo, les chercheurs ont également entraîné un modèle LDM sur de véritables scènes de conduite en situation réelle pour générer des vidéos d'une résolution de 512 x 1024 pixels. Grâce à cette approche, il est possible de produire des vidéos temporellement cohérentes d'une durée de plusieurs minutes.
Les travaux de recherche présentés à la conférence IEEE de 2023 sur la vision par ordinateur et la reconnaissance des motifs (IEEE Conference on Computer Vision and Pattern Recognition, CVPR) montrent que les modèles de diffusion latente peuvent être un outil précieux dans la création de vidéos haute résolution et offrent des directions passionnantes pour la création de contenu futur.
Source : Nvidia Research



